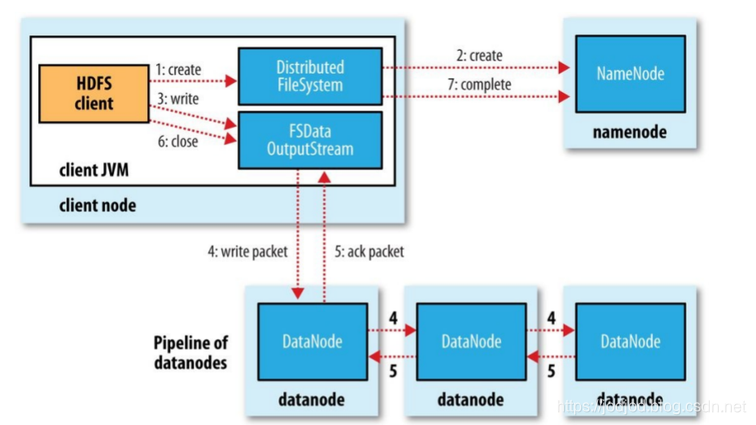
写流程
在创建了分布式文件系统的实例后,客户端通过调用该实例的create()方法就可以创建文件,并会发送给Namenode一个RPC调用,在文件系统的命名空间中创建一个新文件,在创建文件前namenode会做一些检查(如文件是否存在,客户端是否有权限)。检查通过后namenode会为创建文件写一条记录到本地磁盘的Editlog文件,创建成功后DFS实例会返回一个FSDataOutputStream对象,客户端由此开始写入数据。
FSDataOutputStream类封装成DFSDataOutputStream对象,这个对象管理着datanode和namenode之间的交互:
1、客户端在向namenode请求之前先写入文件数据到本地文件系统的内存中(缓存队列dataqueue)
2、等到内存中达到块大小时客户端(DataStreamer线程)开始向namenode请求datanode信息
3、namenode在文件系统中创建文件并返回给客户端一个数据块以及对应datanode的地址列表(包含副本存放位置),这些datanode构成一个管线(pipeline),管线中除了最后一个节点外都负有接力转发的能力
4、客户端通过地址列表把内存中的数据冲刷(flush)到列表中的第一个datanode
①客户端以数据包(Packet)的形式向第一个datanode发送数据,每发送一个packet,这个packet从dataqueue中转移到由ResponseProcessor线程管理的缓存队列ackqueue;
②通过管线依次向下流节点发送packet,并且在管线中的每一个datanode节点在收到数据后都会向前一个datanode节点发送一个ack(ResponseProcessor会在ackqueue中将其移除),最终第一个datanode会向客户端发送一个ack确认
③当客户端收到数据块的确认后,数据块会被认为已经持久化到所有节点,然后客户端会向namenode发送一个确认;如果发送过程中出错,已经发送并移到ackqueue中的packet没有得到应答确认,首先会关闭管线,ackqueue中的packet会移回至dataqueue以供重发,为存储在另一正常datanode的当前数据块指定一个新的标识,并将该标识发送给namenode,以便故障datanode在恢复后可以删除存储的部分数据块。然后从管线中删除故障datanode,基于两个正常的datanode构建一条新的管线
5、文件关闭时,namenode会提交这次文件创建,此时文件在文件系统中可见
Hadoop 默认存放策略:在运行客户端的节点上存放第一个复本,如果客户端位于集群之外,会随机选择一个节点(但会避开那些存储太满或太忙的节点);第二个复本放在与第一个不同且随机另外选择的机架的节点上;第三个复本与第二个复本在同一个机架上,且随机选择另外一个节点;系统会尽量避免在同一个机架上放太多复本
Block、Packet、Chunk
block是最大的一个单位,它是最终存储于DataNode上的数据粒度,由dfs.block.size参数决定,默认是64M
chunk是最小的一个单位,它是DFSClient到DataNode数据传输中进行数据校验的粒度,由io.bytes.per.checksum参数决定,默认是512B;事实上一个chunk还包含4B(ChecksumSize)的校验值,因而chunk写入packet时是516B;数据与检验值的比值为128:1,所以对于一个128M的block会有一个1M的校验文件与之对应,这也就为什么默认最小块大小(dfs.namenode.fs-limits.min-block-size)为1M!
Packet在HDFS中被视为一个基本的网络传输单元,是数据由DFSClient流向DataNode的粒度,以dfs.write.packet.size参数为参考值默认是64K,但由于packet有特定的结构,实际上为65049B
Packet由三部分组成:
每个Packet最多由126(chunksPerPkt)个chunk组成,每个chunk中有4B校验和与512B的数据,但在实际发送packet过程中,校验和和数据是分开存放的
1、头部,由两部分组成,头部最长长度为33B
PKT_LENGTHS_LEN = 6
MAX_PROTO_SIZE = 27
PKT_MAX_HEADER_LEN = PKT_LENGTHS_LEN + MAX_PROTO_SIZE = 332、检验和Checksum,最大长度为 chunksPerPkt(126)*4 = 504B
3、数据,最大长度为 chunksPerPkt(126)*512 = 64512B
所以Packet最大长度为 33 + 504 + 64512 = 65049B,或者可以理解为 33 + (512+4)*126
写过程中会以chunk、packet及packet 三个粒度做三层缓存:
1、当数据流入DFSOutputStream时,DFSOutputStream底层内有一个9倍(BUFFER_NUM_CHUNKS)chunk大小的buf,当数据写满这个buf(或遇到强制flush),会计算checksum值,然后填塞进packet;
2、当一个chunk填塞进入packet后,仍然不会立即发送,而是累积到一个packet填满后,将这个packet放入dataqueue队列;
3、进入dataqueue队列的packet会被按序取出发送到datanode;生产者消费者模型,阻塞生产者的条件是dataqueue与ackqueue之和超过一个block的packet上限
部分源码分析
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class HDFSWriteTest {
public static void main(String[] args) throws IOException {
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(conf);
Path path = new Path("hdfs://master1:9000/d2/f1");
FSDataOutputStream fsout = fs.create(path);
fsout.write("helloworld".getBytes());
fsout.close();
}
}
fsout.write("helloworld".getBytes());
└1─[FilterOutputStream] void write(byte b[])
└2──[FilterOutputStream] void write(byte b[], int off, int len)
└3───[DataOutputStream] synchronized void write(byte b[], int off, int len)
└4────[FSDataOutputStream.PositionCache] write(byte b[], int off, int len)
└5─────[FSOutputSummer] synchronized void write(byte b[], int off, int len)
└6──────[FSOutputSummer] int write1(byte b[], int off, int len)
FSOutputSummer内有一个BytesPerChecksum*BUFFER_NUM_CHUNKS=512*9=4608B的buf[],以及对应的存放校验和数组checksum[],长度为4B*9=36B
//如果写入数据长度大于缓冲区长度(4608),将其直接发送到底层流(packet)
if(count==0 && len>=buf.length) {
final int length = buf.length;
writeChecksumChunks(b, off, length);
return length;
}
//将数据复制到buf中
int bytesToCopy = buf.length-count;
bytesToCopy = (len<bytesToCopy) ? len : bytesToCopy;
System.arraycopy(b, off, buf, count, bytesToCopy);
count += bytesToCopy;
//buf满了则flush,当前只有10B
if (count == buf.length)
flushBuffer();
}
return bytesToCopy;
fsout.close();
└1─[FSDataOutputStream] void close()
└2──[FSDataOutputStream.PositionCache]
└3───[DFSOutputStream] void close()
└4────[DFSOutputStream] synchronized void closeImpl()
//DFSOutputStream中有两个LinkedList类型的缓冲队列dataQueue和ackQueue
try {
//从所有上层流flush至packert中
flushBuffer();
//当前packet不为空时,等待dataqueue为空闲时挂入
if (currentPacket != null) {
waitAndQueueCurrentPacket();
}
if (bytesCurBlock != 0) {
//发送一个空的packet标志着块的结束,该packet中仅有头部即长度为33
currentPacket = createPacket(0, 0, bytesCurBlock, currentSeqno++, true);
currentPacket.setSyncBlock(shouldSyncBlock);
}
//将所有数据(此时为空的packet)flush到datanode中
flushInternal();
//获取最后一个block
ExtendedBlock lastBlock = streamer.getBlock();
try {
//namenode进行创建文件并写入数据
completeFile(lastBlock);
} finally {
scope.close();
}
//关闭streamer和DFSOutputStream,释放dataQueue,ackQueue空间
}finally {
closeThreads(true);
}└5─────[FSOutputSummer] synchronized void flushBuffer()
└6──────[FSOutputSummer] synchronized int flushBuffer(boolean keep,boolean flushPartial)
//强制对buf中的数据进行校验并写入底层输出流(packet),如果buf中有未被填满
//的(大概这个意思,源码注释英文为trailing partial)chunk,flushPartial为true
//则flush该chunk;当flushPartial为true,keep决定是否将改chunk保留在buf中,
//若flushPartial为false,则保存在buf内
int bufLen = count;
int partialLen = bufLen % sum.getBytesPerChecksum();
int lenToFlush = flushPartial ? bufLen : bufLen - partialLen;
//lenToFlush=10
if (lenToFlush != 0) {
writeChecksumChunks(buf, 0, lenToFlush);└7───────[FSOutputSummer] void writeChecksumChunks(byte b[], int off, int len)
//为指定的chunk生成校验和,将chunk+校验和一起发送给底层输出流(packet)
//通过CRC32C进行计算校验和
sum.calculateChunkedSums(b, off, len, checksum, 0);
for (int i = 0; i < len; i += sum.getBytesPerChecksum()) {
//当前只有1个chunk,chunkLen为10,checksum数组中只有4位有值
int chunkLen = Math.min(sum.getBytesPerChecksum(), len - i);
int ckOffset = i / sum.getBytesPerChecksum() * getChecksumSize();
//将chunk写入底层输出流
writeChunk(b, off + i, chunkLen, checksum, ckOffset, getChecksumSize());
}└8────────[DFSOutputStream] void writeChunk(byte[] b, int offset, int len,byte[] checksum, int ckoff, int cklen)
└9────────[DFSOutputStream] synchronized void writeChunkImpl(byte[] b, int offset, int len,byte[] checksum, int ckoff, int cklen)
//当前packet为空,新建一个packet
if (currentPacket == null) {
//packetSize=chunkSize*chunksPerPacket=(512+4)*126=65016
currentPacket = createPacket(packetSize, chunksPerPacket,
bytesCurBlock, currentSeqno++, false);
}
//将校验和部分写入到packet中的buf
currentPacket.writeChecksum(checksum, ckoff, cklen);
//将数据部分写入到packet中的buf中
currentPacket.writeData(b, offset, len);
//chunk数+1
currentPacket.incNumChunks();
//block中有10B了
bytesCurBlock += len;└10─────────[DFSOutputStream] DFSPacket createPacket(int packetSize, int chunksPerPkt, long offsetInBlock,long seqno, boolean lastPacketInBlock)
//packet内部维护着一个缓冲区
final byte[] buf;
//buf长度为 33+65016=65049
final int bufferSize = PacketHeader.PKT_MAX_HEADER_LEN + packetSize;
try {
buf = byteArrayManager.newByteArray(bufferSize);
} catch (InterruptedException ie) {
final InterruptedIOException iioe = new InterruptedIOException(
"seqno=" + seqno);
iioe.initCause(ie);
throw iioe;
}
//返回构造方法
return new DFSPacket(buf, chunksPerPkt, offsetInBlock, seqno,
getChecksumSize(), lastPacketInBlock);└11─────────[DFSPacket] DFSPacket(byte[] buf, int chunksPerPkt, long offsetInBlock, long seqno,int checksumSize, boolean lastPacketInBlock)
this.lastPacketInBlock = lastPacketInBlock;
this.numChunks = 0;
this.offsetInBlock = offsetInBlock;
this.seqno = seqno;
this.buf = buf;
//PKT_MAX_HEADER_LEN = PKT_LENGTHS_LEN + MAX_PROTO_SIZE =6+27=33
checksumStart = PacketHeader.PKT_MAX_HEADER_LEN;
checksumPos = checksumStart;
//33+(126*4)=537
dataStart = checksumStart + (chunksPerPkt * checksumSize);
dataPos = dataStart;
//126
maxChunks = chunksPerPkt;└5─────[DFSOutputStream] void waitAndQueueCurrentPacket()
//等待dataqueue空闲时挂入
synchronized (dataQueue) {
try {
boolean firstWait = true;
try {
//阻塞条件为dataQueue.size() + ackQueue.size() >80
while (!isClosed() && dataQueue.size() + ackQueue.size() >
dfsClient.getConf().writeMaxPackets) {
try {
dataQueue.wait();
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
break;
}
}
} finally {
}
//加入dataQueue并唤醒dataStreamer线程
checkClosed();
queueCurrentPacket();
} catch (ClosedChannelException e) {
}
}└5─────[DFSOutputStream] void queueCurrentPacket()
if (currentPacket == null) return;
currentPacket.addTraceParent(Trace.currentSpan());
//将该packet添加到队列末尾
dataQueue.addLast(currentPacket);
lastQueuedSeqno = currentPacket.getSeqno();
currentPacket = null;
//唤醒dataStreamer线程
dataQueue.notifyAll();
}└5─────[DFSOutputStream] void flushInternal()
//待确认的packet数量
long toWaitFor;
synchronized (this) {
dfsClient.checkOpen();
checkClosed();
//
// If there is data in the current buffer, send it across
//
queueCurrentPacket();
toWaitFor = lastQueuedSeqno;
}
//向datanode发送packet
waitForAckedSeqno(toWaitFor);└5─────[DFSOutputStream] void completeFile(ExtendedBlock last)
boolean fileComplete = false;
//有5次重试机会
int retries = dfsClient.getConf().nBlockWriteLocateFollowingRetry;
while (!fileComplete) {
//src=/d2/f1
//DFSClient[clientName=DFSClient_NONMAPREDUCE_-1501156867_1, ugi=jinge (auth:SIMPLE)]
//last=BP-163740078-192.168.80.120-1554104956001:blk_1073741875_1061
//fileId=16426
fileComplete =
dfsClient.namenode.complete(src, dfsClient.clientName, last, fileId);






