文章目录
- 1、背景
- 2、hdfs file system shell命令有哪些
- 3、确定shell操作的是哪个文件系统
- 4、本地准备如下文件
- 5、hdfs file system shell
- 5.1 mkdir创建目录
- 5.2 put上传文件
- 5.3 ls查看目录或文件
- 5.4 cat 查看文件内容
- 5.5 head 查看文件前1000字节内容
- 5.6 tail 查看文件后1000字节内容
- 5.7 appendToFile 追加数据到hdfs文件中
- 5.8 get下载文件
- 5.9 getmerge合并下载
- 5.10 cp复制文件
- 5.11 mv移动文件
- 5.12 setrep 修改指定文件的副本数
- 5.13 df显示可用空间
- 5.14 du统计文件夹或文件的大小
- 5.15 chgrp chmod chown改变文件的所属权限
- 5.16 rm删除文件或目录
- 6、界面操作
- 7、参考链接
1、背景
此处我们通过命令行,简单的学习一下 hdfs file system shell 的一些操作。
hdfs_file_system_shell_4">2、hdfs file system shell命令有哪些
我们可以通过如下网址https://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-common/FileSystemShell.html#appendToFile来看看支持的命令操作。 其中大部分命令都和linux的命令用法类似。
 hdfs file system shell有哪些" />
hdfs file system shell有哪些" />
3、确定shell操作的是哪个文件系统
 hadoop fs操纵时如何知道操作的是那个文件系统" />
hadoop fs操纵时如何知道操作的是那个文件系统" />
# 操作本地文件系统
[hadoopdeploy@hadoop01 ~]$ hadoop fs -ls file:///
Found 19 items
dr-xr-xr-x - root root 24576 2023-02-18 14:47 file:///bin
dr-xr-xr-x - root root 4096 2022-06-13 10:41 file:///boot
drwxr-xr-x - root root 3140 2023-02-28 20:17 file:///dev
......
# 操作hdfs 文件系统
[hadoopdeploy@hadoop01 ~]$ hadoop fs -ls hdfs://hadoop01:8020/
Found 1 items
drwxrwx--- - hadoopdeploy supergroup 0 2023-02-19 17:20 hdfs://hadoop01:8020/tmp
# 操作hdfs 文件系统 fs.defaultFS
[hadoopdeploy@hadoop01 ~]$ hadoop fs -ls /
Found 1 items
drwxrwx--- - hadoopdeploy supergroup 0 2023-02-19 17:20 /tmp
[hadoopdeploy@hadoop01 ~]$
4、本地准备如下文件
| 文件名 | 内容 |
|---|---|
| 1.txt | aaa |
| 2.txt | bbb |
| 3.txt | ccc |
hdfs_file_system_shell_38">5、hdfs file system shell
5.1 mkdir创建目录
语法: Usage: hadoop fs -mkdir [-p] <paths>
-p表示,如果父目录不存在,则创建父目录。
[hadoopdeploy@hadoop01 sbin]$ hadoop fs -mkdir -p /bigdata/hadoop
[hadoopdeploy@hadoop01 sbin]$
5.2 put上传文件
语法: Usage: hadoop fs -put [-f] [-p] [-d] [-t <thread count>] [-q <thread pool queue size>] [ - | <localsrc> ...] <dst>
-f 如果目标文件已经存在,则进行覆盖操作
-p 保留访问和修改时间、所有权和权限
-d 跳过._COPYING_的临时文件
-t 要使用的线程数,默认为1。上传包含1个以上文件的目录时很有用
-q 要使用的线程池队列大小,默认为1024。只有线程数大于1时才生效
# 创建3个文件 1.txt 2.txt 3.txt
[hadoopdeploy@hadoop01 ~]$ echo aaa > 1.txt
[hadoopdeploy@hadoop01 ~]$ echo bbb > 2.txt
[hadoopdeploy@hadoop01 ~]$ echo ccc > 3.txt
# 上传本地的 1.txt 到hdfs的 /bigdata/hadoop 目录中
[hadoopdeploy@hadoop01 ~]$ hadoop fs -put -p 1.txt /bigdata/hadoop
# 因为 /bigdata/hadoop 中已经存在了 1.txt 所有上传失败
[hadoopdeploy@hadoop01 ~]$ hadoop fs -put -p 1.txt /bigdata/hadoop
put: `/bigdata/hadoop/1.txt': File exists
# 通过 -f 参数,如果目标文件已经存在,则进行覆盖操作
[hadoopdeploy@hadoop01 ~]$ hadoop fs -put -p -f 1.txt /bigdata/hadoop
# 查看 /bigdata/hadoop 目录中的文件
[hadoopdeploy@hadoop01 ~]$ hadoop fs -ls /bigdata/hadoop
Found 1 items
-rw-rw-r-- 2 hadoopdeploy hadoopdeploy 4 2023-02-28 12:31 /bigdata/hadoop/1.txt
# 通过多线程和 通配符 上传多个文件
[hadoopdeploy@hadoop01 ~]$ hadoop fs -put -p -f -t 3 *.txt /bigdata/hadoop
# 查看 /bigdata/hadoop 目录中的文件
[hadoopdeploy@hadoop01 ~]$ hadoop fs -ls /bigdata/hadoop
Found 3 items
-rw-rw-r-- 2 hadoopdeploy hadoopdeploy 4 2023-02-28 12:31 /bigdata/hadoop/1.txt
-rw-rw-r-- 2 hadoopdeploy hadoopdeploy 4 2023-02-28 12:31 /bigdata/hadoop/2.txt
-rw-rw-r-- 2 hadoopdeploy hadoopdeploy 4 2023-02-28 12:31 /bigdata/hadoop/3.txt
5.3 ls查看目录或文件
语法: Usage: hadoop fs -ls [-h] [-R] <paths>
-h 展示成人类可读的,比如文件的大小,展示成多少M等。
-R 递归展示。
# 列出/bigdata 目录和文件
[hadoopdeploy@hadoop01 ~]$ hadoop fs -ls /bigdata/
Found 1 items
drwxr-xr-x - hadoopdeploy supergroup 0 2023-02-28 12:37 /bigdata/hadoop
# -R 递归展示
[hadoopdeploy@hadoop01 ~]$ hadoop fs -ls -R /bigdata/
drwxr-xr-x - hadoopdeploy supergroup 0 2023-02-28 12:37 /bigdata/hadoop
-rw-rw-r-- 2 hadoopdeploy hadoopdeploy 4 2023-02-28 12:31 /bigdata/hadoop/1.txt
-rw-rw-r-- 2 hadoopdeploy hadoopdeploy 4 2023-02-28 12:31 /bigdata/hadoop/2.txt
-rw-rw-r-- 2 hadoopdeploy hadoopdeploy 4 2023-02-28 12:31 /bigdata/hadoop/3.txt
# -h 展示成人类可读的,比如多少k,多少M等
[hadoopdeploy@hadoop01 ~]$ hadoop fs -ls -R -h /bigdata/
drwxr-xr-x - hadoopdeploy supergroup 0 2023-02-28 12:37 /bigdata/hadoop
-rw-rw-r-- 2 hadoopdeploy hadoopdeploy 4 2023-02-28 12:31 /bigdata/hadoop/1.txt
-rw-rw-r-- 2 hadoopdeploy hadoopdeploy 4 2023-02-28 12:31 /bigdata/hadoop/2.txt
-rw-rw-r-- 2 hadoopdeploy hadoopdeploy 4 2023-02-28 12:31 /bigdata/hadoop/3.txt
5.4 cat 查看文件内容
语法: Usage: hadoop fs -cat [-ignoreCrc] URI [URI ...]
-ignoreCrc 禁用checkshum验证
注意: 如果文件比较大,需要慎重读取,因为这是查看文件的全部内容
# 查看 1.txt 和 2.txt 的文件内容
[hadoopdeploy@hadoop01 ~]$ hadoop fs -cat -ignoreCrc /bigdata/hadoop/1.txt /bigdata/hadoop/2.txt
aaa
bbb
[hadoopdeploy@hadoop01 ~]$
5.5 head 查看文件前1000字节内容
语法: Usage: hadoop fs -head URI
Displays first kilobyte of the file to stdout(显示文件的前1000字节)
# 查看1.txt的前1000字节
[hadoopdeploy@hadoop01 ~]$ hadoop fs -head /bigdata/hadoop/1.txt
aaa
[hadoopdeploy@hadoop01 ~]$
5.6 tail 查看文件后1000字节内容
语法: Usage:hadoop fs -tail [-f] URI
Displays last kilobyte of the file to stdout.(显示文件的后1000字节)
-f:表示将随着文件的增长输出附加数据,就像在Unix中一样。
# 查看1.txt的后1000字节
[hadoopdeploy@hadoop01 ~]$ hadoop fs -tail /bigdata/hadoop/1.txt
aaa
[hadoopdeploy@hadoop01 ~]$
hdfs_143">5.7 appendToFile 追加数据到hdfs文件中
语法: Usage: hadoop fs -appendToFile <localsrc> ... <dst>
将单个src或多个src从本地文件系统附加到目标文件系统。还可以从标准输入(localsrc是-)读取输入并附加到目标文件系统。
# 查看1.txt文件的内容
[hadoopdeploy@hadoop01 ~]$ hadoop fs -cat /bigdata/hadoop/1.txt
aaa
# 查看2.txt文件的内容
[hadoopdeploy@hadoop01 ~]$ hadoop fs -cat /bigdata/hadoop/2.txt
bbb
# 将1.txt文件的内容追加到2.txt文件中
[hadoopdeploy@hadoop01 ~]$ hadoop fs -appendToFile 1.txt /bigdata/hadoop/2.txt
# 再次查看2.txt文件的内容
[hadoopdeploy@hadoop01 ~]$ hadoop fs -cat /bigdata/hadoop/2.txt
bbb
aaa
[hadoopdeploy@hadoop01 ~]$
5.8 get下载文件
语法: Usage: hadoop fs -get [-ignorecrc] [-crc] [-p] [-f] [-t <thread count>] [-q <thread pool queue size>] <src> ... <localdst>
将文件复制到本地文件系统。可以使用-gnrecrc选项复制未能通过CRC检查的文件。可以使用-crc选项复制文件和CRC。
-f 如果目标文件已经存在,则进行覆盖操作
-p 保留访问和修改时间、所有权和权限
-t 要使用的线程数,默认为1。下载包含多个文件的目录时很有用
-q 要使用的线程池队列大小,默认为1024。只有线程数大于1时才生效
# 下载hdfs文件系统的1.txt 到本地当前目录下的1.txt.download文件
[hadoopdeploy@hadoop01 ~]$ hadoop fs -get /bigdata/hadoop/1.txt ./1.txt.download
# 查看 1.txt.download是否存在
[hadoopdeploy@hadoop01 ~]$ ls
1.txt 1.txt.download 2.txt 3.txt
# 再次下载,因为本地已经存在1.txt.download文件,所有报错
[hadoopdeploy@hadoop01 ~]$ hadoop fs -get /bigdata/hadoop/1.txt ./1.txt.download
get: `./1.txt.download': File exists
# 通过 -f 覆盖已经存在的文件
[hadoopdeploy@hadoop01 ~]$ hadoop fs -get -f /bigdata/hadoop/1.txt ./1.txt.download
# 多线程下载
[hadoopdeploy@hadoop01 ~]$ hadoop fs -get -f -t 3 /bigdata/hadoop/*.txt ./123.txt.download
get: `./123.txt.download': No such file or directory
# 多线程下载
[hadoopdeploy@hadoop01 ~]$ hadoop fs -get -f -t 3 /bigdata/hadoop/*.txt .
[hadoopdeploy@hadoop01 ~]$
5.9 getmerge合并下载
语法: Usage: hadoop fs -getmerge [-nl] [-skip-empty-file] <src> <localdst>
将多个src文件的内容合并到localdst文件中
-nl 表示在每个文件末尾增加换行符
-skip-empty-file 跳过空文件
# hdfs上1.txt文件的内容
[hadoopdeploy@hadoop01 ~]$ hadoop fs -cat /bigdata/hadoop/1.txt
aaa
# hdfs上3.txt文件的内容
[hadoopdeploy@hadoop01 ~]$ hadoop fs -cat /bigdata/hadoop/3.txt
ccc
# 将hdfs上1.txt 3.txt下载到本地 merge.txt 文件中 -nl增加换行符 -skip-empty-file跳过空文件
[hadoopdeploy@hadoop01 ~]$ hadoop fs -getmerge -nl -skip-empty-file /bigdata/hadoop/1.txt /bigdata/hadoop/3.txt ./merge.txt
# 查看merge.txt文件
[hadoopdeploy@hadoop01 ~]$ cat merge.txt
aaa
ccc
[hadoopdeploy@hadoop01 ~]$
5.10 cp复制文件
语法: Usage: hadoop fs -cp [-f] [-p | -p[topax]] [-t <thread count>] [-q <thread pool queue size>] URI [URI ...] <dest>
-f 如果目标文件存在则进行覆盖。
-t 要使用的线程数,默认为1。复制包含多个文件的目录时很有用
-q 要使用的线程池队列大小,默认为1024。只有线程数大于1时才生效
# 查看 /bigdata目录下的文件
[hadoopdeploy@hadoop01 ~]$ hadoop fs -ls /bigdata
Found 1 items
drwxr-xr-x - hadoopdeploy supergroup 0 2023-02-28 12:55 /bigdata/hadoop
# 查看/bigdata/hadoop目录下的文件
[hadoopdeploy@hadoop01 ~]$ hadoop fs -ls /bigdata/hadoop
Found 3 items
-rw-rw-r-- 2 hadoopdeploy hadoopdeploy 4 2023-02-28 12:31 /bigdata/hadoop/1.txt
-rw-rw-r-- 2 hadoopdeploy hadoopdeploy 8 2023-02-28 12:55 /bigdata/hadoop/2.txt
-rw-rw-r-- 2 hadoopdeploy hadoopdeploy 4 2023-02-28 12:31 /bigdata/hadoop/3.txt
# 将 /bigdata/hadoop 目录下所有的文件 复制到 /bigdata 目录下
[hadoopdeploy@hadoop01 ~]$ hadoop fs -cp /bigdata/hadoop/* /bigdata
# 查看 /bigdata/ 目录下的文件
[hadoopdeploy@hadoop01 ~]$ hadoop fs -ls /bigdata
Found 4 items
-rw-r--r-- 2 hadoopdeploy supergroup 4 2023-02-28 13:17 /bigdata/1.txt
-rw-r--r-- 2 hadoopdeploy supergroup 8 2023-02-28 13:17 /bigdata/2.txt
-rw-r--r-- 2 hadoopdeploy supergroup 4 2023-02-28 13:17 /bigdata/3.txt
drwxr-xr-x - hadoopdeploy supergroup 0 2023-02-28 12:55 /bigdata/hadoop
[hadoopdeploy@hadoop01 ~]$
5.11 mv移动文件
语法: Usage: hadoop fs -mv URI [URI ...] <dest>
将文件从源移动到目标。此命令还允许多个源,在这种情况下,目标需要是一个目录。不允许跨文件系统移动文件。
# 列出 /bigdata/hadoop 目录下的文件
[hadoopdeploy@hadoop01 ~]$ hadoop fs -ls /bigdata/hadoop
Found 3 items
-rw-rw-r-- 2 hadoopdeploy hadoopdeploy 4 2023-02-28 12:31 /bigdata/hadoop/1.txt
-rw-rw-r-- 2 hadoopdeploy hadoopdeploy 8 2023-02-28 12:55 /bigdata/hadoop/2.txt
-rw-rw-r-- 2 hadoopdeploy hadoopdeploy 4 2023-02-28 12:31 /bigdata/hadoop/3.txt
# 将 1.txt 重命名为 1-new-name.txt
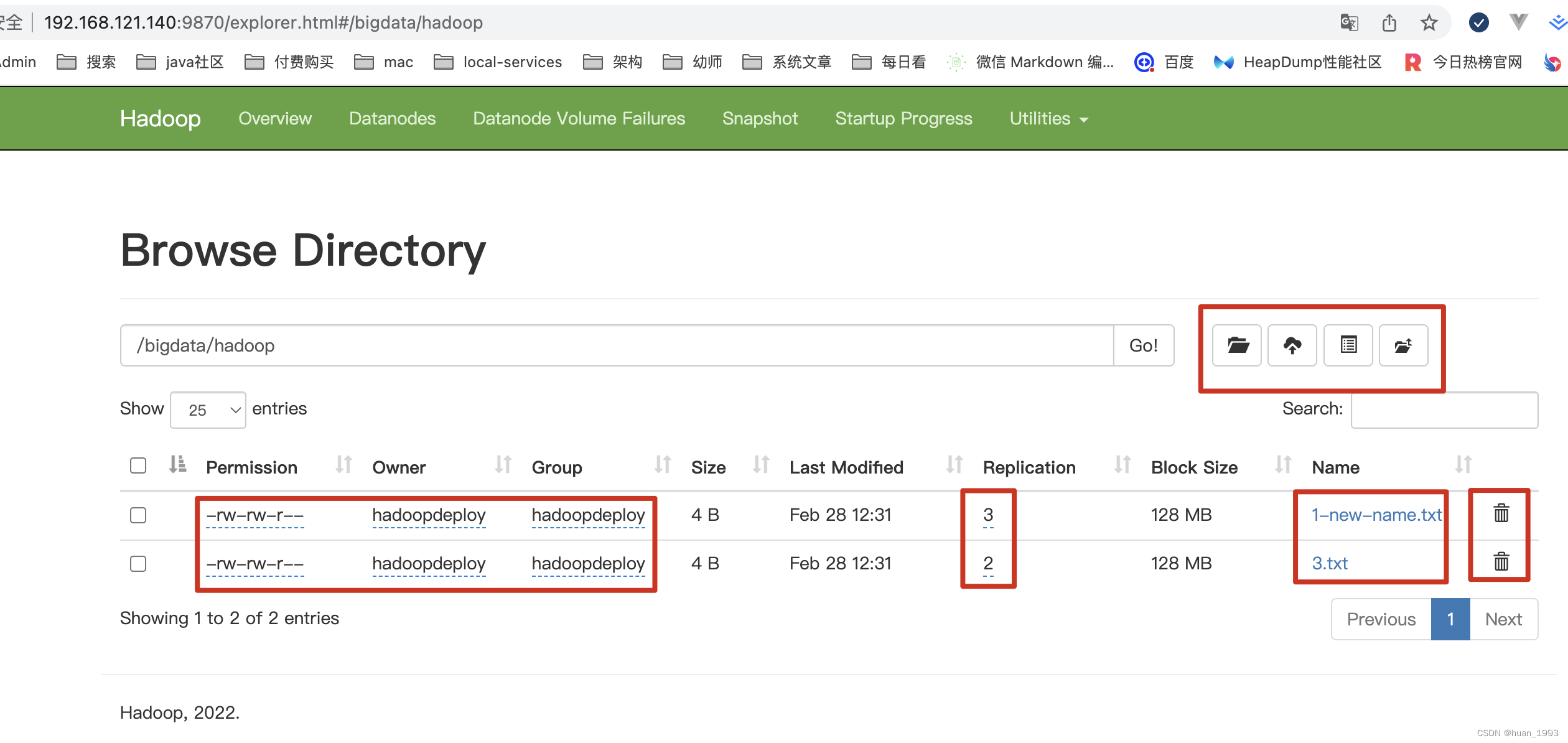
[hadoopdeploy@hadoop01 ~]$ hadoop fs -mv /bigdata/hadoop/1.txt /bigdata/hadoop/1-new-name.txt
# 列出 /bigdata/hadoop 目录下的文件,可以看到1.txt已经改名了
[hadoopdeploy@hadoop01 ~]$ hadoop fs -ls /bigdata/hadoop
Found 3 items
-rw-rw-r-- 2 hadoopdeploy hadoopdeploy 4 2023-02-28 12:31 /bigdata/hadoop/1-new-name.txt
-rw-rw-r-- 2 hadoopdeploy hadoopdeploy 8 2023-02-28 12:55 /bigdata/hadoop/2.txt
-rw-rw-r-- 2 hadoopdeploy hadoopdeploy 4 2023-02-28 12:31 /bigdata/hadoop/3.txt
[hadoopdeploy@hadoop01 ~]$
5.12 setrep 修改指定文件的副本数
语法: Usage: hadoop fs -setrep [-R] [-w] <numReplicas> <path>
更改文件的副本数。如果path是一个目录,则该命令递归更改以path为根的目录树下所有文件的副本数。执行此命令时,EC文件将被忽略。
-R -R标志是为了向后兼容。它没有影响。
-w -w标志请求命令等待复制完成。这可能需要很长时间。
# 修改1-new-name.txt文件为3个副本
[hadoopdeploy@hadoop01 ~]$ hadoop fs -setrep -w 3 /bigdata/hadoop/1-new-name.txt
Replication 3 set: /bigdata/hadoop/1-new-name.txt
Waiting for /bigdata/hadoop/1-new-name.txt .... done
[hadoopdeploy@hadoop01 ~]$
5.13 df显示可用空间
语法: Usage: hadoop fs -df [-h] URI [URI ...]
[hadoopdeploy@hadoop01 ~]$ hadoop fs -df /bigdata/hadoop
Filesystem Size Used Available Use%
hdfs://hadoop01:8020 27697086464 1228800 17716019200 0%
# -h 显示人类可读的
[hadoopdeploy@hadoop01 ~]$ hadoop fs -df -h /bigdata/hadoop
Filesystem Size Used Available Use%
hdfs://hadoop01:8020 25.8 G 1.2 M 16.5 G 0%
5.14 du统计文件夹或文件的大小
语法: Usage: hadoop fs -df [-h] URI [URI ...]
[hadoopdeploy@hadoop01 ~]$ hadoop fs -du /bigdata/hadoop
4 12 /bigdata/hadoop/1-new-name.txt
8 16 /bigdata/hadoop/2.txt
4 8 /bigdata/hadoop/3.txt
[hadoopdeploy@hadoop01 ~]$ hadoop fs -du -s /bigdata/hadoop
16 36 /bigdata/hadoop
[hadoopdeploy@hadoop01 ~]$ hadoop fs -du -s -h /bigdata/hadoop
16 36 /bigdata/hadoop
# 16 表示/bigdata/hadoop目录下所有文件的总大小
# 36 表示/bigdata/hadoop目录下所有文件占据所有副本的总大小
[hadoopdeploy@hadoop01 ~]$ hadoop fs -du -s -h -v /bigdata/hadoop
SIZE DISK_SPACE_CONSUMED_WITH_ALL_REPLICAS FULL_PATH_NAME
16 36 /bigdata/hadoop
[hadoopdeploy@hadoop01 ~]$
5.15 chgrp chmod chown改变文件的所属权限
[hadoopdeploy@hadoop01 ~]$ hadoop fs -ls /bigdata/hadoop/2.txt
-rw-rw-r-- 2 hadoopdeploy hadoopdeploy 8 2023-02-28 12:55 /bigdata/hadoop/2.txt
# 给2.txt增加可执行的权限
[hadoopdeploy@hadoop01 ~]$ hadoop fs -chmod +x /bigdata/hadoop/2.txt
[hadoopdeploy@hadoop01 ~]$ hadoop fs -ls /bigdata/hadoop/2.txt
-rwxrwxr-x 2 hadoopdeploy hadoopdeploy 8 2023-02-28 12:55 /bigdata/hadoop/2.txt
[hadoopdeploy@hadoop01 ~]$
5.16 rm删除文件或目录
语法: Usage: hadoop fs -rm [-f] [-r |-R] [-skipTrash] [-safely] URI [URI ...]
如果启用了回收站,文件系统会将已删除的文件移动到垃圾箱目录。
目前,默认情况下禁用垃圾桶功能。用户可以通过为参数fs. trash.interval(在core-site.xml中)设置大于零的值来启用回收站。
-f 如果文件不存在,将不会显示诊断消息或修改退出状态以反映错误。
-R 选项递归删除目录及其下的任何内容。
-r 选项等价于-R。
-skipTrash 选项将绕过回收站,如果启用,并立即删除指定的文件。当需要从大目录中删除文件时,这很有用。
-safely 在删除文件总数大于 hadoop.shell.delete.limited.num.files的文件时(在core-site.xml中,默认值为100)之前,需要进行安全确认
# 删除2.txt,因为我本地启动了回收站,所以文件删除的文件进入了回收站
[hadoopdeploy@hadoop01 ~]$ hadoop fs -rm /bigdata/hadoop/2.txt
2023-02-28 22:04:51,302 INFO fs.TrashPolicyDefault: Moved: 'hdfs://hadoop01:8020/bigdata/hadoop/2.txt' to trash at: hdfs://hadoop01:8020/user/hadoopdeploy/.Trash/Current/bigdata/hadoop/2.txt
[hadoopdeploy@hadoop01 ~]$
6、界面操作
可能有些人会说,这么多的命令,怎么记的住,如果我们可以操作hdfs的界面,则可以在界面上进行操作。
7、参考链接
1、https://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-common/FileSystemShell.html#appendToFile