引言—HDFS的重要性:
Hadoop的定义:适合大数据的分布式存储与计算的一个平台,其中大数据的分布式存储就是由HDFS来完成的,因此掌握好HDFS的相关概念与应用非常重要!
本篇博客将从以下几个方面讲述HDFS:
1、分布式文件系统与HDFS
2、HDFS的体系结构
3、HDFS----NameNode相关概念
4、HDFS----DataNode相关概念
5、HDFS----block块相关概念
6、HDFS----副本数相关概念
7、HDFS的具体操作方式
(一)分布式文件系统与HDFS
①分布式文件系统DFS的由来:
随着我们的数据量越来越大,在一个操作系统中存放数据就放不下了,因此如果数据在一台电脑上放不下只能放到另外一台电脑上,此时问题就有了:如果把数据分散到多台电脑上的话,我们对数据的管理也就变得越来越麻烦了,这个问题如何解决?
期待一个管理系统能够让我们无缝的管理多台操作系统上面的数据,在操作多台电脑上数据的时候,就好像是在一台电脑上操作一样,这就是分布式文件系统的由来。
②分布式文件系统的优点:
1、是一种允许文件通过网络在多台主机上分享的文件系统,可以让多台机器上的多户户分享文件和存储空间。
2、通透性:让实际上是通过网络来访问文件的动作,由程序与用户看来,就像是访问本地磁盘一样。
3、容错:即使系统中有某些节点挂掉,整体来说系统仍然可以继续运作而不会有数据的丢失。
分布式文件管理系统有很多,HDFS只是其中的一种。适合于一次写入多次查询的的情况,不支持并发写情况,小文件不合适。
一句话描述HDFS:把客户端的大文件存放在很多节点(服务器)的数据块中。
(二)HDFS的体系结构
HDFS的体系结构是一个主从结构,主节点Namenode只有一个,从节点Datanode有很多个.主节点Namenode与从节点Datanode实际上指的是不同的物理机器,即有一个机器跑的进程是Namenode.很多机器上跑的进程是Datanode。
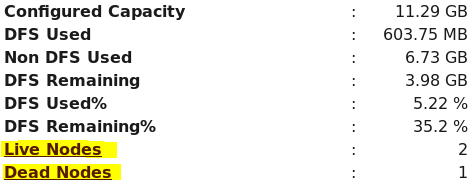
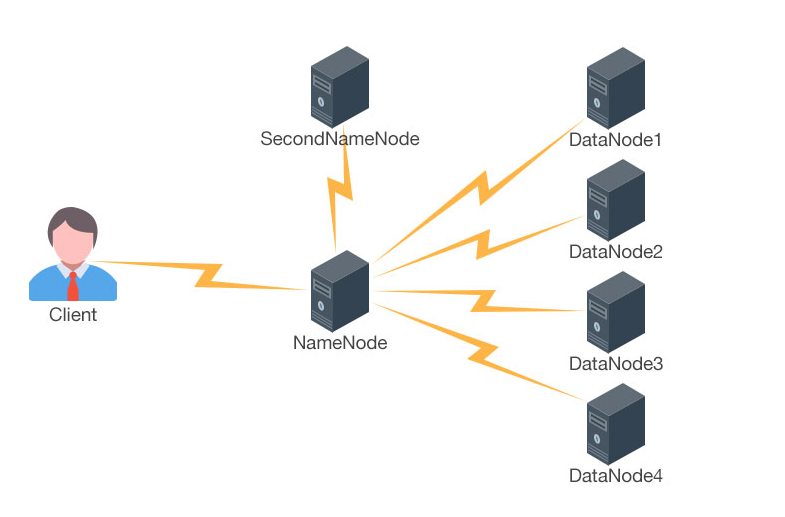
HDFS体系结构——NameNode
从上面的源码可以看出,在任何分布式文件系统的部署当中只存在一个运行的NameNode,除非存在第二个备份或故障转移NameNode。

NameNode重要性:
1>Namenode负责接收用户的操作请求,是整个文件系统的管理节点
2>维护着整个文件系统的目录结构,所谓目录结构类似于windows文件夹的体系结构
3>还保管着我们文件或目录的元数据信息(metadata),所谓元数据信息指的是除了数据本身之外涉及到文件自身的相关信息:修改时间、大小、访问权限、副本数等等
命令:du -sh *
4>知道文件与block块序列之间的对应关系、负责记录文件是如何被分割成数据块的,以及这些数据块分别存储到哪些节点上等.
总结来说:NameNode就是负责管理工作的。
NameNode核心源码分析:
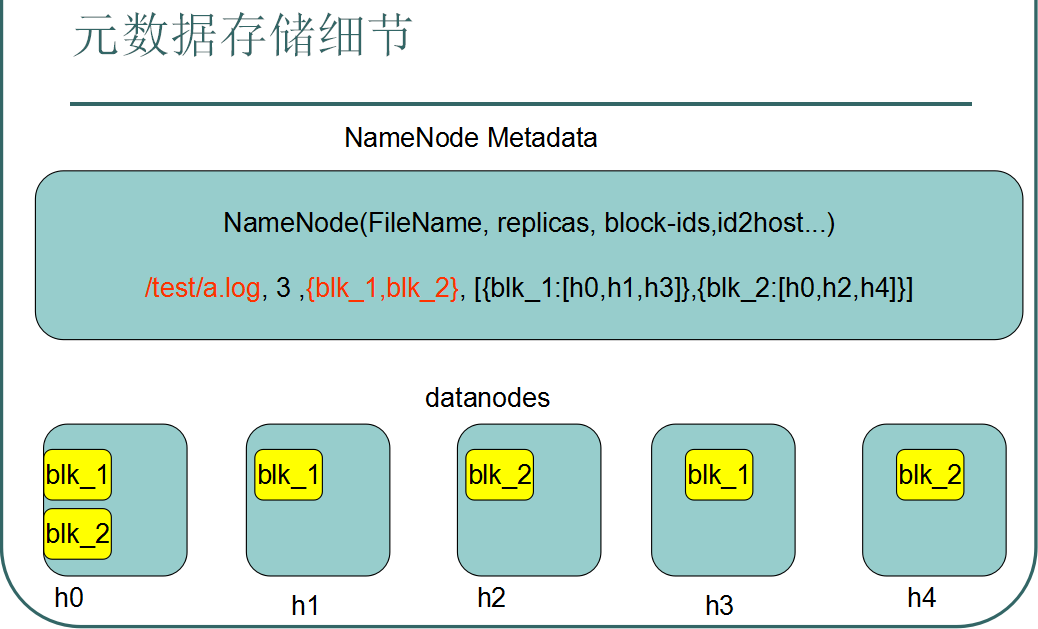
通过源码可以发现:NameNode这个节点管理着两张核心的表,第一张表管理着文件与block块序列之间的对应关系,第二张表管理着block块与DataNode节点之间的对应关系。
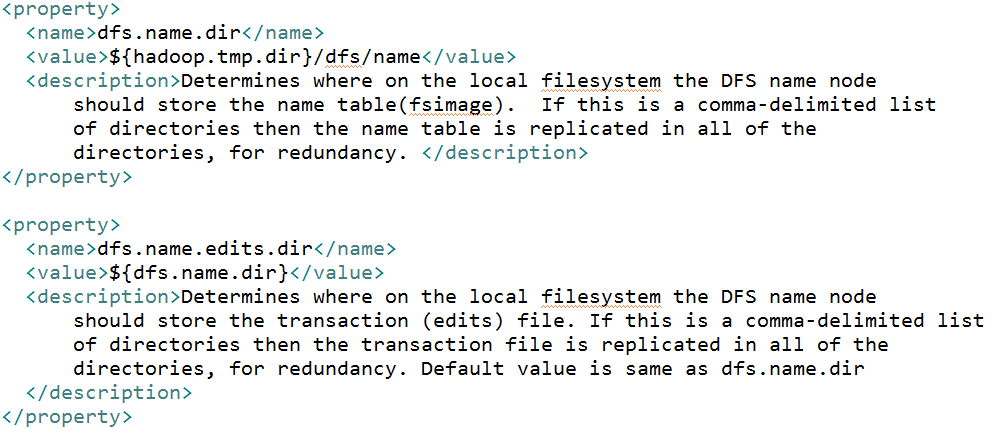
其中前一张表是静态的,是存放在磁盘上的,通过fsimage和edits文件来维护,后一张表是动态的,每当集群启动的时候会自动建立这个信息。
下面通过一个具体的实例阐述具体含义:
此时NameNode的两张核心表中将记载着如下信息:
即第一张表中管理着文件与block块序列之间的对应关系,第二张表中管理着block块与DataNode节点之间的对应关系。


fsimage与edits存放的路径:
HDFS体系结构-----SecondaryNameNode
SecondaryNameNode的重要性:
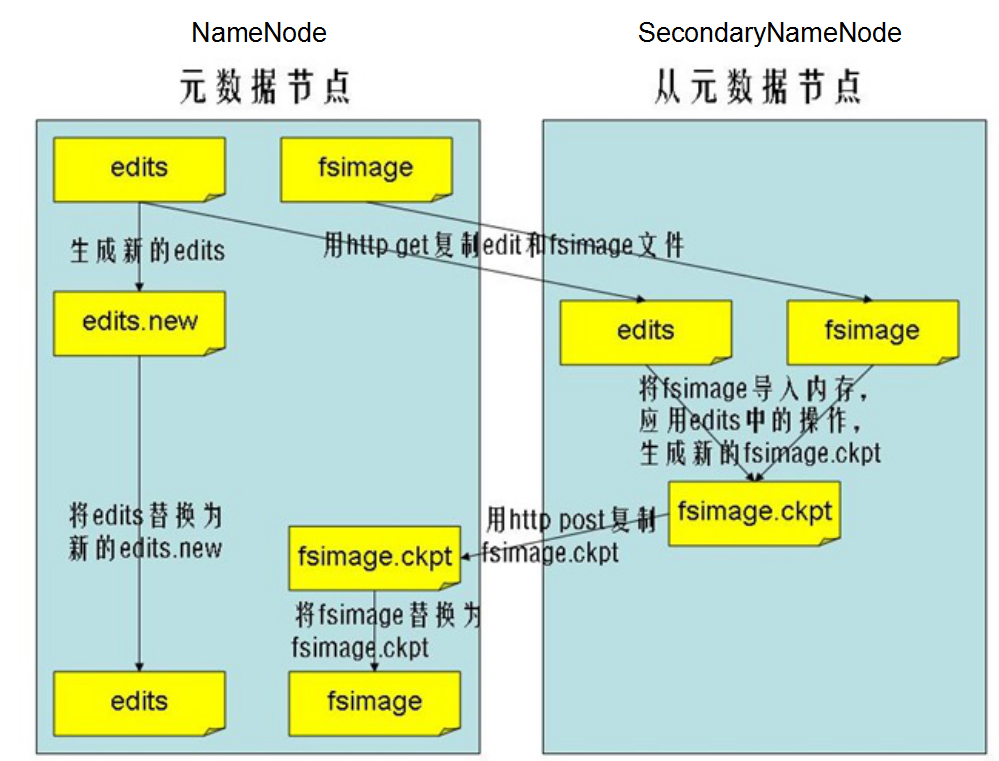
Secondnamenode作为老二,只做一件事情:合并Namenode中的fsimage+edits
Namenode与Secondnamenode本身是两个独立的java进程,它们之间数据的交换是通过网络http走的.
合并的执行过程:Secondnamenode会先把Namenode中的fsimage+edits这些元数据先拷贝到自己进程的那一块.然后将fsimage与edits进行合并,生成新的fsimage,随后将新的fsimage送回到Namenode中.同时重置Namenode中的edits.即将原来的edits中的数据清空。
HDFS体系结构——DataNode
DataNode重要性
1>Datanode只做一件事情:存储数据,HDFS之所以可以存储海量数据实际上指的是Datanode这个节点可以进行扩展.
2>Datanode是以block块的方式来存储数据的.这一点不同于我们的windows操作系统,HDFS中的文件是被切成block块来进行存储的。之所以将文件切分成小块来进行存储,也是为了便于维护与管理.为保证数据安全,block块会有多个副本,并且这些副本会被存储到不同的机器上面。
DataNode中的block块到底是存放到哪里呢?我们可以通过配置文件hdfs-default.xml进行查看:
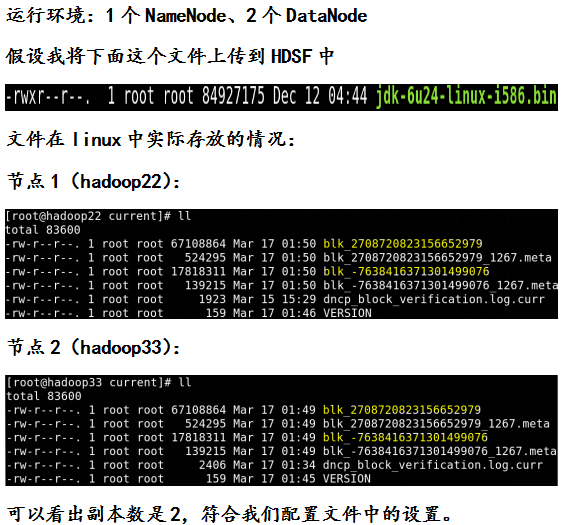
其中参数dfs.data.dir的数值就是block块存放在linux文件系统中的位置,参数${hadoop.tmp.dir}的数值我们自己可以进行配置,我配置的路径为:/usr/local/hadoop/tmp,因此block块存放的具体路径是:
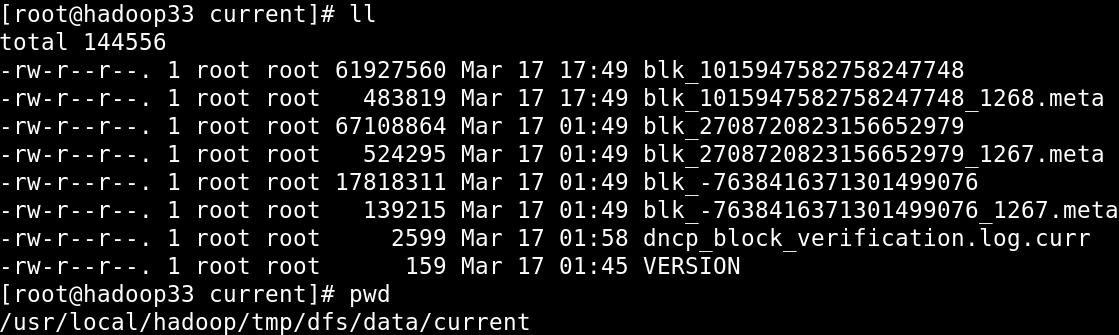
/usr/local/hadoop/tmp/dfs/data.因此通过linux命令我们可以对数据块进行相应的查看:
思考:既然将数据通过linux上传到HDFS之后,Datanode最终还是把数据放到了linux文件系统的目录下,为什么不直接将数据放到/usr/local/hadoop/tmp/dfs/data这个目录下面?
1>换角度思考:数据库Oracle是存储数据的,就好像HDFS也是存储数据的一样,但是数据库的数据最终还是存放在了windows上面.我们之所以使用数据库仅仅是为了解决数据领域中的一个问题:查询,而HDFS和数据库一样,也仅仅是为了解决数据领域中的一个问题:海量数据的存储
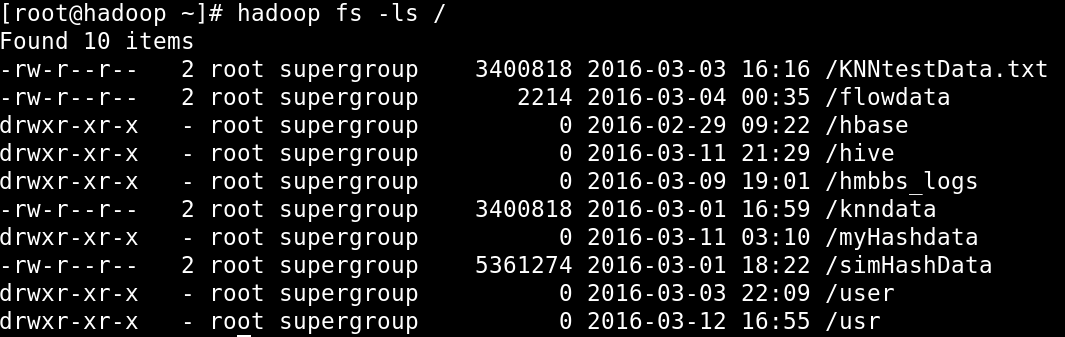
2>如果直接通过手工将数据上传到Datanode中存放数据的那个目录下面,那么通过hadoop fs -ls /这个命令是查不到这个文件的.因为若手工上传,Namenode是不知道的,即手工上传的数据HDFS是不认的.

HDFS——block相关概念
block块是HDFS最基本的存储单位,HDFS会将文件切分成block块来进行存储,默认的block块大小是64M,以一个256M文件大小为例,共会被切分成256/64=4个block
block块的默认大小:
<property>
<name>dfs.block.size</name>
<value>67108864</value>
<description>The default block size for new files.</description>
</property>
HDFS----副本数相关概念
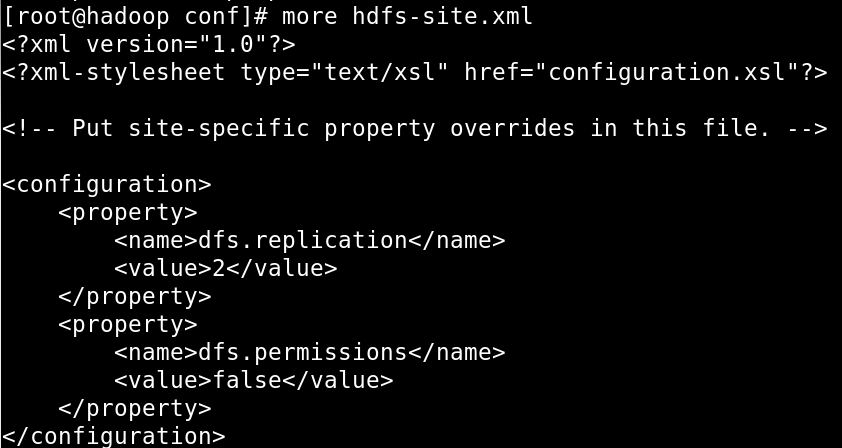
在HDFS存储数据时为了确保数据的安全性,引入了副本的机制,默认的副本数为3,我们在配置文件hdfs-defaule.xml中可以进行查看:
当然副本的数量我们可以在hdfs-site.xml中进行修改的:

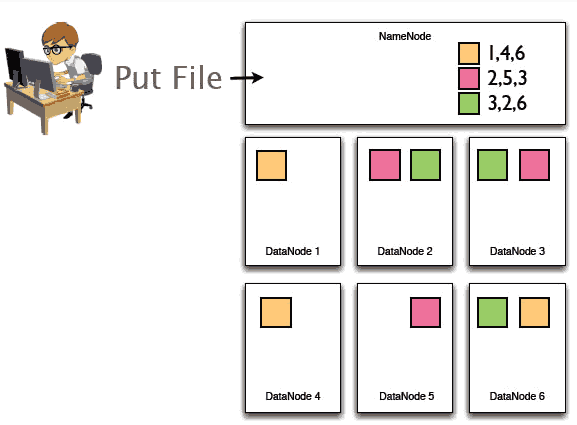
下面我们通过一个具体的实例阐述HDFS存储原理:
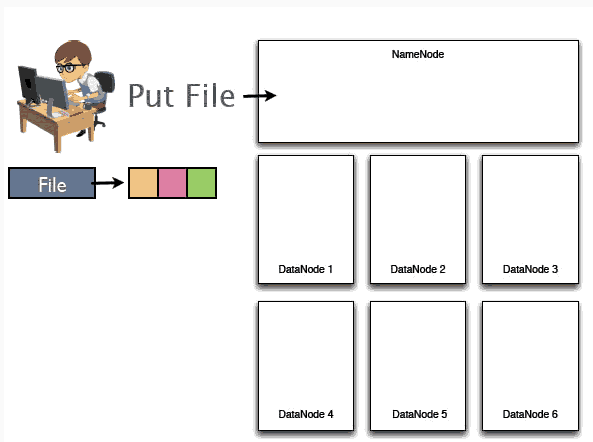
1、假设某个用户要上传一个大小是192M的文件,首先NameNode将会接收到用户上传数据的请求:
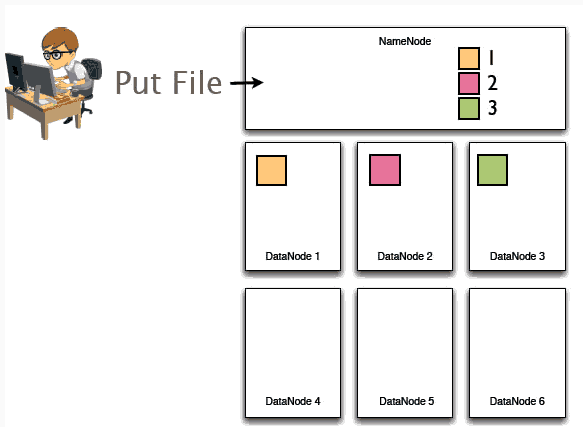
2、随后192M的整个文件将会被切成3个block块分别存储在3台不同的机器上,即DataNode上面。与此同时NameNode将会记录这些数据块存储到哪些Datanode上面、文件与block序列之间的对应关系等等。
3、然后HDFS在节点之间复制这些数据块,最后这三块在多个节点中分布如下:每一个block块被拷贝成了3个副本,保证了数据的安全性。
正如上面实例所示:
1>NameNode记载着文件与block序列之间的对应关系、记录着block块存储在哪些节点上等等
2>DataNode就是存储数据的,即block块的
3>副本机制确保了数据的安全性
(三)HDFS的操作方式
HDFS的具体操作方式:shell操作与JavaApi操作两种方式
shell操作:https://www.linuxidc.com/Linux/2013-09/89658.htm
通过eclipse关联Hadoop源码的详细操作:https://blog.csdn.net/a2011480169/article/details/52751729
https://blog.csdn.net/a2011480169/article/details/51758200
hadoop fs -ls / :查看HDFS的目录结构
hadoop fs -lsr / :递归查看HDFS的目录结构
hadoop fs -mkdir /d1 :在HDFS上面创建文件夹
hadoop fs -put :上传数据文件
hadoop fs -get :下载数据文件
hadoop fs -rmr :删除HDFS中的文件夹或者文件
-mkdir path:在HDFS中创建一个名为path的目录,如果它的上级目录不存在,使用mkidr –p递归的进行创建。
-du -s path:显示path下文件磁盘使用情况,单位是字节。
-du -s -h path:显示path下文件磁盘使用情况,单位可视化。
-mv src dest:在HDFS中,将文件或目录从HDFS的源路径移动到目标路径。
-setrep [-R] [-w] rep path :设置目标文件的复制数。
查看hadoop配置文件中属性:hdfs getconf -confKey dfs.replication(不是–confKey)

[root@hadoop11 local]# hadoop fs -du -s /user/dd_edw/hadoop-2.4.1-x64.tar.gz
124191203 /user/dd_edw/hadoop-2.4.1-x64.tar.gz
[root@hadoop11 local]# hadoop fs -du -s -h /user/dd_edw/hadoop-2.4.1-x64.tar.gz
118.4 M /user/dd_edw/hadoop-2.4.1-x64.tar.gz
[root@hadoop11 hadoop]# hdfs dfs -help setrep
-setrep [-R] [-w] <rep> <path> ...: Set the replication level of a file. If <path> is a directory
then the command recursively changes the replication factor of
all files under the directory tree rooted at <path>.
The -w flag requests that the command wait for the replication
to complete. This can potentially take a very long time.
The -R flag is accepted for backwards compatibility. It has no effect.
JavaApi操作:https://blog.csdn.net/a2011480169/article/details/51758200
JavaApi对HDFS的操作只要或得一个fileSystem对象就可以了。
FileSystem fileSystem = FileSystem.get(new URI(path0) , new Configuration());
通过FileSystem用户可以与NameNode进行通信。



