Spark Catalyst
- 逻辑计划
- 逻辑计划解析
- 逻辑计划优化
- Catalyst 规则优化过程
- 物理计划
- Spark Plan
- JoinSelection
- 生成 Physical Plan
- EnsureRequirements
Spark SQL 端到端的优化流程:
- Catalyst 优化器 : 包含逻辑优化/物理优化
- Tungsten :
Spark SQL的优化过程 :

逻辑计划
val userFile: String = _
val usersDf = spark.read.parquet(userFile)
val txFile: String = _
val txDf = spark.read.parquet(txFile)
val users = usersDf
.select("name", "age", "userId")
.filter($"age" < 30)
.filter($"gender".isin("M"))
val result = txDF.select("price", "volume", "userId")
.join(users, Seq("userId"), "inner")
.groupBy(col("name"), col("age"))
.agg(sum(col("price") * col("volume")).alias("sum")
result.write.parquet("_")
计算逻辑 :
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EkAXwKmc-1678098435847)(../../png/Catalyst/image-20230213212938895.png)]](https://img-blog.csdnimg.cn/8acd1864ebf84ca6a21dc306551e54f0.png)
Catalyst 逻辑优化阶段:
- 逻辑计划解析 : 把 Unresolved Logical Plan 换为 Analyzed Logical Plan
- 逻辑计划优化 : 基于启发式规则(Heuristics Based Rules) ,把 Analyzed Logical Plan 转为 Optimized Logical Plan
Catalyst 逻辑优化阶段
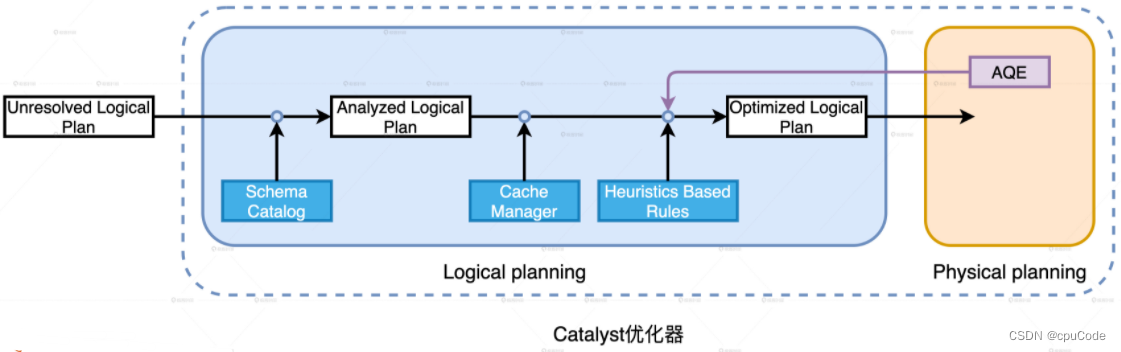
Unresolved Logical Plan :

逻辑计划解析
逻辑计划解析 : 结合 DataFrame 的 Schema ,确认计划中的表名、字段名、字段类型和实际数据是否一致。确认后,就生成 Analyzed Logical Plan
Analyzed Logical Plan :

逻辑计划优化
同种计算逻辑的多种实现方式 :
- 按照不同的顺序对算子做排列组合
- 最好顺序:能省则省、能拖则拖的开发原则,选择所有实现方式中最优
Catalyst 优化规则范畴 :
- 谓词下推(Predicate Pushdown):把谓词 (过滤条件
age < 30) 推到离数据源最近 - 列剪裁(Column Pruning): 只扫描与查询相关的字段
- 常量替换 (Constant Folding): 如 :
age <12 + 18优化成age < 30
Cache Manager 优化 :
- Cache Manager :维护与缓存相关信息。即:维护 Mapping 映射字典,Key :逻辑计划,Value :对应的 Cache 元信息
- 当 Catalyst 进行逻辑计划优化时,先在 Cache Manager 查找,当该逻辑计划分支在 Cache Manager 时,就进行替换该计划
Optimized Logical Plan :

Catalyst 规则优化过程
逻辑计划(Logical Plan),物理计划(Physical Plan)都继承 QueryPlan
QueryPlan 父类: TreeNode
- TreeNode :语法树中对节点的抽象
- TreeNode 有个字段 children ,类型是 Seq[TreeNode]
- 利用 TreeNode 类型,能构建出树结构
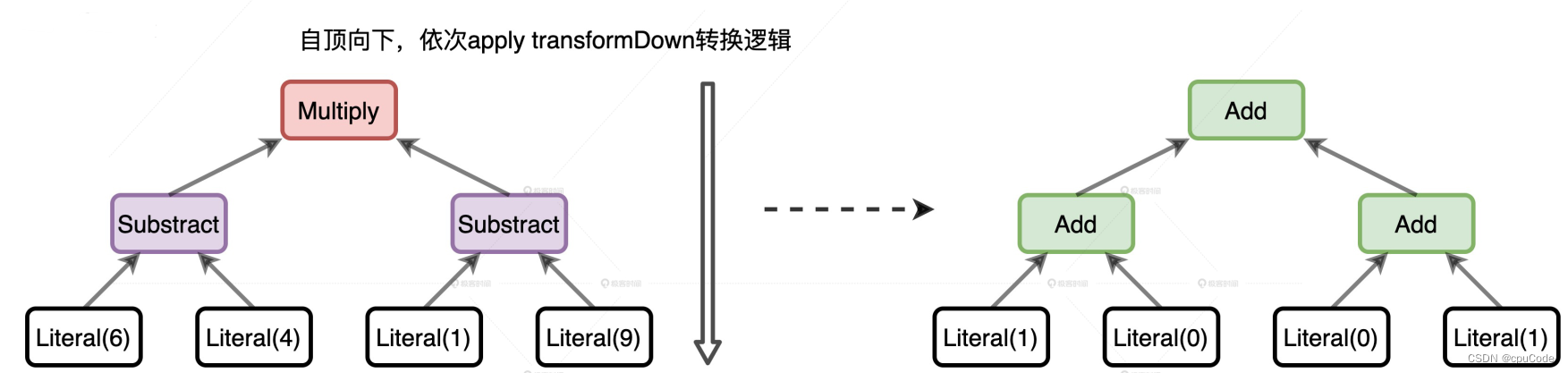
TreeNode 定义了很多高阶函数,如:transformDown
- transformDown 的形参: 各种优化规则,返回类型是 TreeNode
- transformDown 是递归函数,先优化当前节点,再依次优化 children 中的子节点,直到整棵树的叶子节点
transformDown 类似转换过程:
//Expression的转换
import org.apache.spark.sql.catalyst.expressions._
val myExpr: Expression =
Multiply(Subtract(Literal(6), Literal(4)),
Subtract(Literal(1), Literal(9)))
val transformed: Expression = myExpr transformDown {
// 二元操作符,转成加法操作
case BinaryOperator(l, r) => Add(l, r)
// 大于 5 ,转成 1
case IntegerLiteral(i) if i > 5 => Literal(1)
// 小于 5 ,转成转成 0
case IntegerLiteral(i) if i < 5 => Literal(0)
}
转换过程意图:
物理计划
物理计划阶段(Physical Planning) :
- 优化 Spark Plan :根据优化策略 (Strategies),把逻辑计划的关系操作符映射成物理操作符
- 生成 Physical Plan :根据 Preparation Rules,对 Spark Plan 进行完善
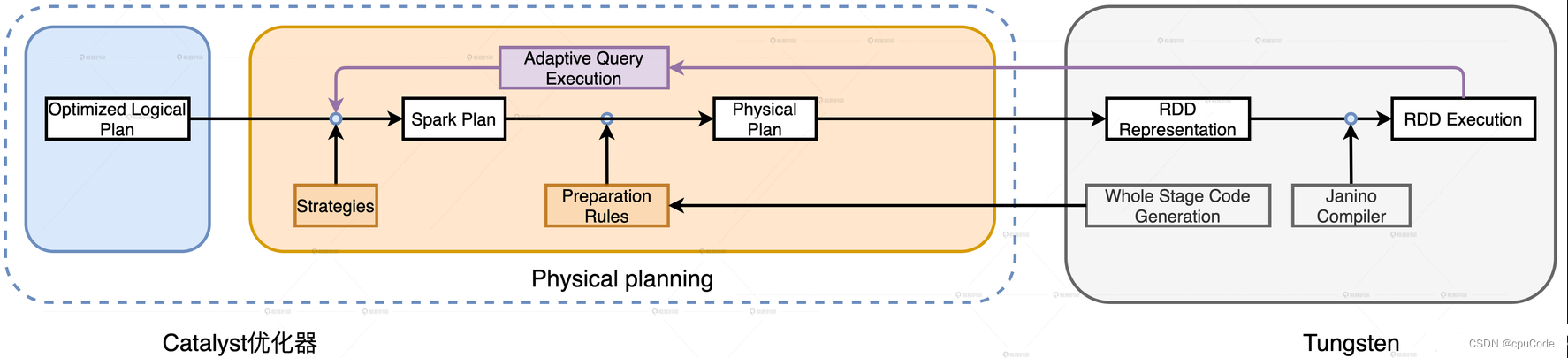
Spark Plan
Spark Plan 优化策略 :
- 基于模式匹配的偏函数(Partial Functions),把逻辑计划中的操作符平行映射为 Spark Plan 中的物理算子
| 类型 | 优化策略 | 含义&作用 |
|---|---|---|
| 通用 | BasicOperators | 逻辑到物理的基本映射:如Project/Filter/Sort |
| JoinSelection | 静态 Joln 策略选择 | |
| InMemoryScans | 缓存策略,对应逻辑优化阶段的 Cache Manager | |
| Aggregation | 聚合策路 | |
| Window | 窗口计算策酪 | |
| SpecialLimits | 与 Limit 相关的优化策路 | |
| PythonEvals | Python UDF 优化策路 | |
| SparkScripts | Transformation 脚本优化策略 | |
| Streaming | StatefulAggregationStrategy | 有状态的聚合策略 |
| StreamingDeduplicationStrategy | 流处理中的去重策路 | |
| StreamingGlobalLimitStrategy | 流处理中的 Limit 处理策略 | |
| StreamingJoinStrategy | 流处理中的 Join 策略 | |
| StreamingRelationStrategy | 数据源读取策酪 | |
| FlatMapGroupsWithStateStrategy | 流处理中的 FlatMap 优化 |
JoinSelection
Catalyst 运行时的 Join 策略:
| Join 策略 | 执行效率排序 | 含义 |
|---|---|---|
| Broadcast Hash Join (BHJ) | 最优 | 小表构建哈希表,把小表广播进行关联 |
| Shuffle Sort Merge Join (SMJ) | 次优 | 先 Shuffle , 再排序进行关联 |
| Shuffle Hash Join (SHJ) | 次优 | 先 Shuffle , 再构建哈希表进行关联 |
| Broadcast Nested Loop Join (BNLJ) | 最差 | 将小表广播进行关联 |
| Shuffle Cartesian Product Join (CPJ) | 最差 | 先 Shuffle 进行关联 |
数据分发与 Join 实现机制的组合 :
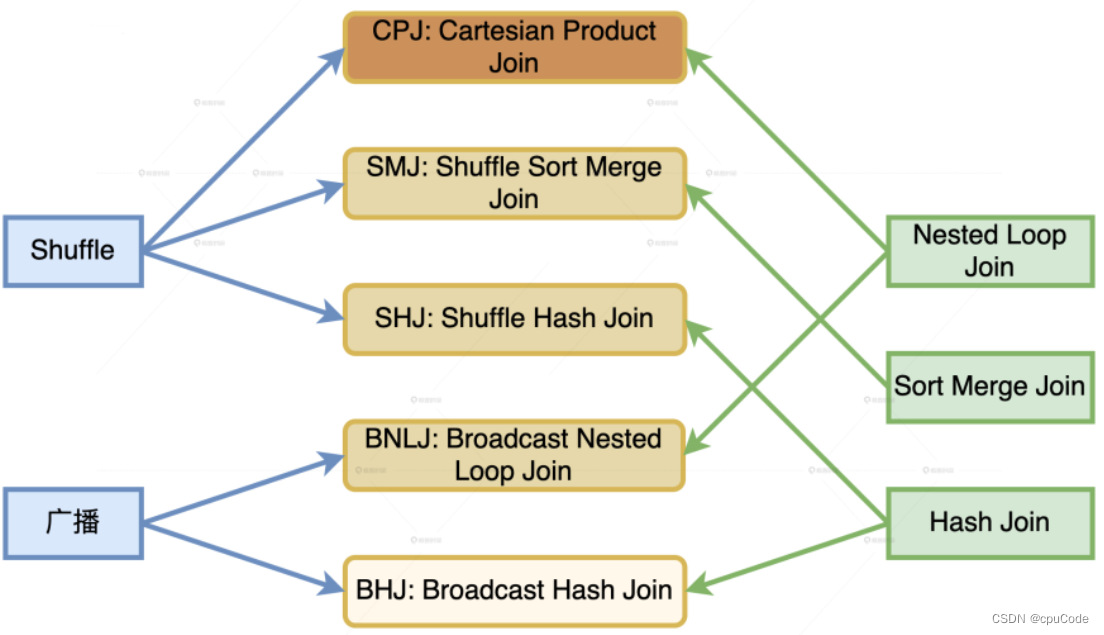
Join 策略的先决条件 :
- 条件型 : 判决 5 大 Join 策略的先决条件
- 指令型:开发者提供的 Join Hints
5 种 Join 策略的先决条件:
| 选择顺序 | Join 策略 | Join 类型 | 表大小 | ||
|---|---|---|---|---|---|
| 等值 Join | Inner Join | 不能 Full Outer Join | 能广播 | ||
| 1 | BHJ | √ | √ | √ | |
| 2 | SMJ | √ | |||
| 3 | SHJ | √ | |||
| 4 | BNLJ | √ | |||
| 5 | CPJ | √ |
指令型信息: Join Hints,允许个人选择 Join 策略
- 选择 SHJ :
val result = txDF.select("price", "volume", "userId")
.join(users.hint("shuffle_hash"), Seq("userId"), "inner")
.groupBy(col("name"), col("age"))
.agg(sum(col("price") * col("volume")).alias("revenue"))
Spark Plan :Join 策略是 SMJ
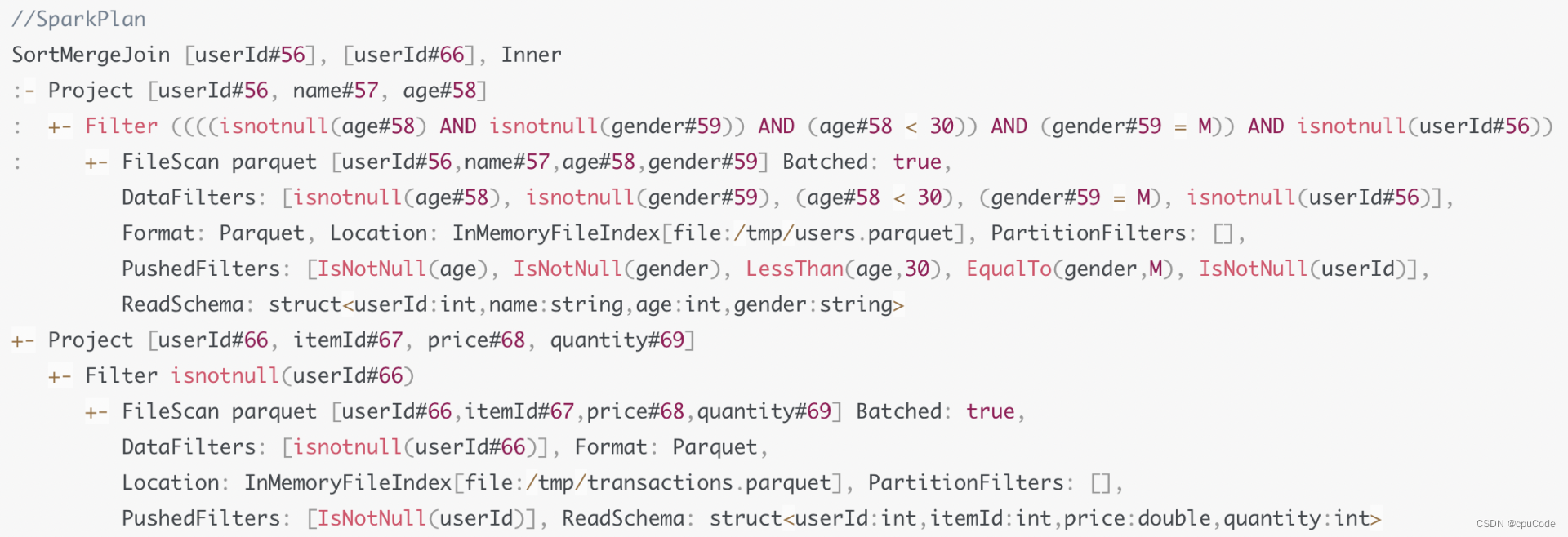
生成 Physical Plan
从 Spark Plan 到 Physical Plan 的转换,需要 Preparation Rules 规则
Preparation Rules :
| Preparation Rules | 含义 | 作用 |
|---|---|---|
| EnsureRequirements | 确保每个操作符的输入要求,必要时添加 Shuffle/Sort | 为 Physical Plan 补充必要的操作,保证 Spark Plan 计划的每个步骤能够顺利执行 |
| CollapseCodegenStages | Tungsten 优化机制:全阶段代码生成(Whole Stage Code Generation) | 在同个 Stage 内部,尽可能地把所有操作和计算捏合成一个函数,提升计算效率 |
| ReuseExchange | 内存或磁盘中的存储复用 | 同样的执行计划能共享广播变量或 Shuffle 的中间结果,避免重复的 Shuffle 操作 |
| ReuseSubquery | 子查询复用 | 复用同样的查询结果,避免重复计算 |
| PlanSubquery | 生成子查询 | 对子查询应用 Preparation Rules |
| ExtractPythonUDFs | 提取 Python 的 UDF 函数 | 把 Python UDF 分发到单独的 Python 进程 |
EnsureRequirements
EnsureRequirements (满足前提条件) : 对执行计划中的每个操作符节点,都有 4 个属性用来描述数据输入/ 输出的分布状态
| 操作符属性 | 含义 |
|---|---|
| outputPartitioning | 输出数据的分区规则 |
| outputOrdering | 输出数据的排序规则 |
| requireChildDistribution | 要求输入数据满足某种分区规则 |
| requireChildOrdering | 要求输入数据满足某种排序规则 |
Project 不满足 SortMergeJoin 的 Requirements:
- outputPartitioning 属性 :Unknow,未 Shuffle
- outputOrdering 属性: None ,未排序
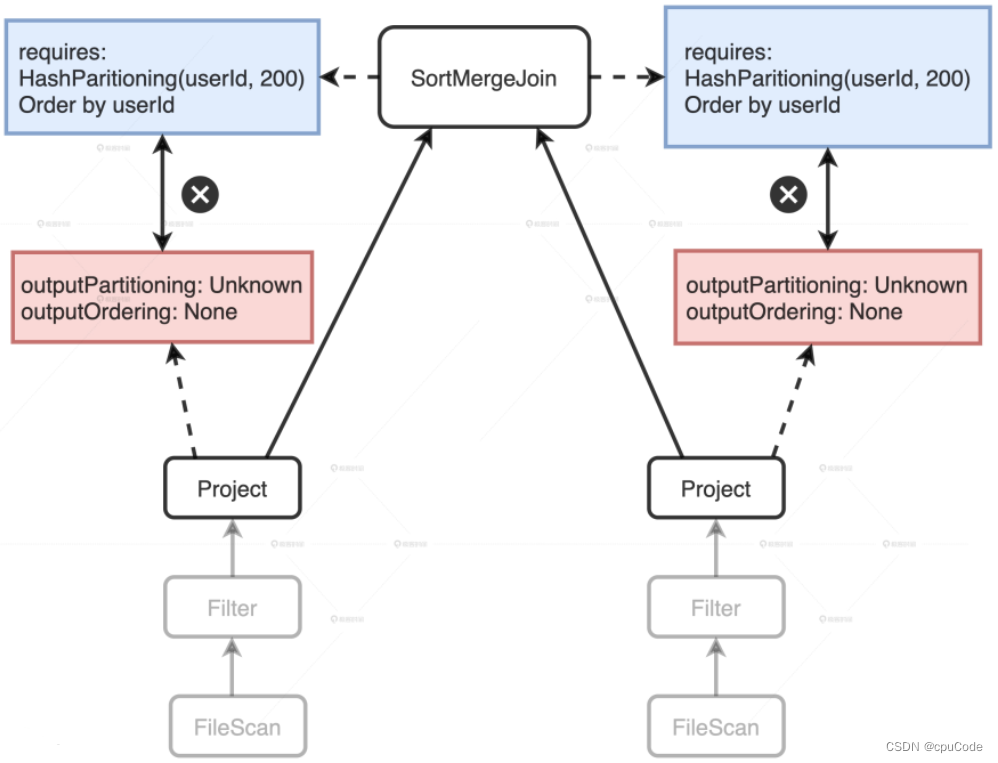
EnsureRequirements 规则添加 Exchange/Sort :
- Exchange : Shuffle 操作,满足 SortMergeJoin 对数据分布的要求
- Sort :排序,满足 SortMergeJoin 对数据有序的要求
- 调用 Physical Plan 的 doExecute 方法,把结构化查询的计算结果,转换成
RDD[InternalRow] - InternalRow :Tungsten 设计的定制化二进制数据结构
- 调用 RDD[InternalRow] 上的 Action 算子,Spark 就触发 Physical Plan 执行
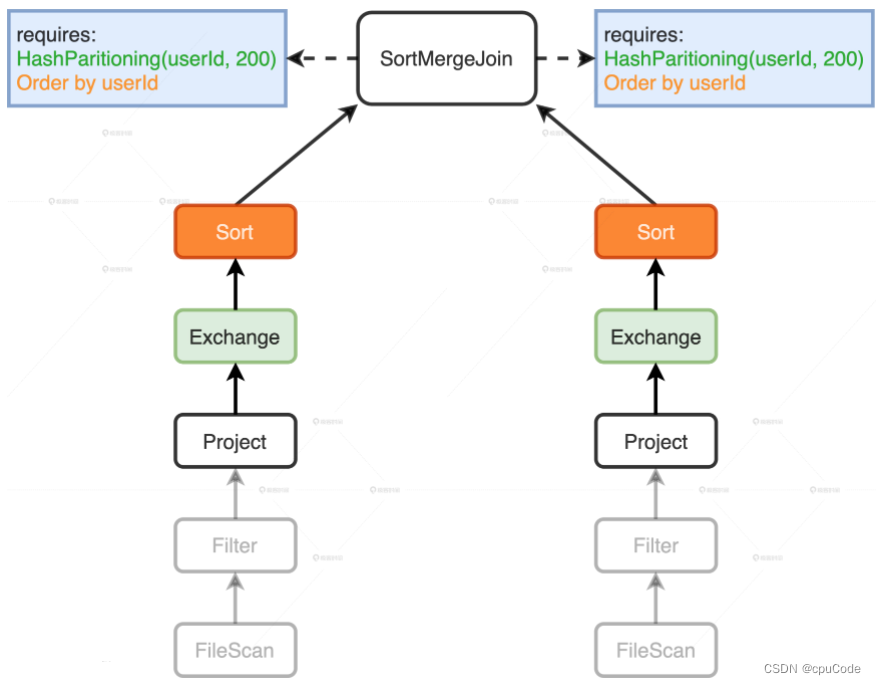
Physical Plan :
- EnsureRequirements 在两个分支上添加 Exchange/Sort
*(数字):*: WSCG,数字 : Stage 编号- 数字相同会 WSCG 合成