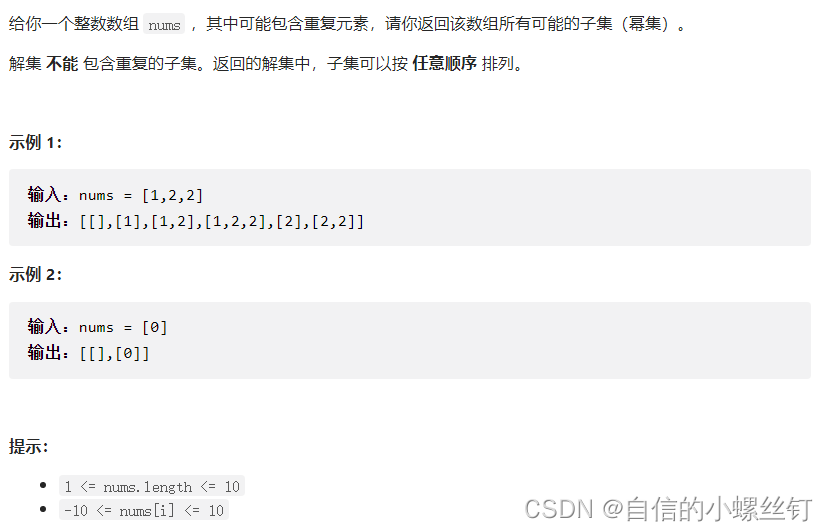
1、原始位置的默认配置
hive中的Default(默认)数据仓库的最原始位置是在hdfs上的 /user/hive/warehouse(以下默认Hive的HDFS根目录为/user/hive)路径下,这个原始位置是本地的/usr/local/hive/conf/hive-default.xml.template文件默认配置的,
2、库表关系
1)默认情况下:
在hdfs目录下,没有对默认的数据库default创建文件夹。如果某张表属于default数据库,直接在数据仓库目录下创建一个文件夹。
下图中abc,bonus,department,dept,emp为缺省库default下的几张表,目录名与表名一致。

2)指定库情况下
如果创建了数据库,并指定表为该库下的表,Hive会在/user/hive/warehouse/下创建一个以库名命名的目录(如上图的a.db,b.db分别代表数据库a,b),该库的表目录在库目录下。

3)制定分区的情况下:
如果为表设定了分区,则会在表目录下增加分区目录,目录名以“分区键名=分区值”的形式命名。如下图,表dept1中,设置了v1和v2两个名为a的分区。

3、修改数据仓库的原始位置只需在hive-site.xml自定义配置文件中设置如下信息即可:
<property>
<name>hive.metastore.warehouse.dir</name>
<value>目录</value>
<description>location of default database for the warehouse</description>
</property>
需要为该目录配置同组可写:
hdfs dfs -chmod g+w 目录
,另外也可以顺便在这个自定义配置文件中设置如下参数
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
这样每次select返回结果信息就会显示有表头字段名了。