Spark Join大大表
- 分而治之
- 拆分内表
- 外表的重复扫描
- 案例
- 负隅顽抗
- 数据分布均匀
- 数据倾斜
- Task 数据倾斜
- Executor 数据倾斜
- 两阶段 Shuffle
- Executors 调优案例
Join 大大表 :
- Join 的两张体量较大的事实表,尺寸相差在 3 倍内,且无法广播变量
- 用大表 Join 大表才能实现业务逻辑,说明 : 数据仓库在设计初时,考虑不够完善
- 大表 Join 大表的调优思路:分而治之/ 负隅顽抗
分而治之
分而治之的调优思路:把复杂任务拆解成多个简单任务,再合并多个简单任务的计算结果
分而治之的计算过程:
- 根据两表的大小区分:外表/ 内表(较小)
- 对内表进行过滤,并把内表划分为多个不重复的完整子集
- 把外表和这些子集做关联,得到部分计算结果
- 最后用 Union 把所有结果合并到一起,得到完整的计算结果
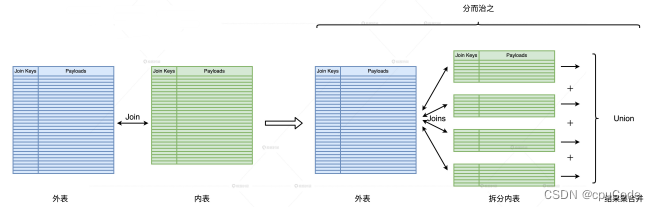
拆分内表
内表拆分:要求每个子表的尺寸相对均匀, 且都小到进行广播变量
拆分的关键 : 选取的列,要让子表足够小 :
- 基数低 : 内表的拆分列是性别(男/女),性别基数是 2。这拆出来的子表还是很大,远远超出广播阈值
- 基数大 : 拆分:身份证号。缺点:不易拆分,开发成本高 ; 过滤条件很难触发优化机制(谓词下推)
- 拆分:时间。一般事实表都与时间相关。既能享受分区剪裁(Partition Pruning),又降低开发成本
外表的重复扫描
外表的重复扫描 :
- 内表拆分后,外表会和所有子表做关联,但每次关联都要重新扫描外表的全量数据
- 外表扫描的次数 = 内表拆分的份数
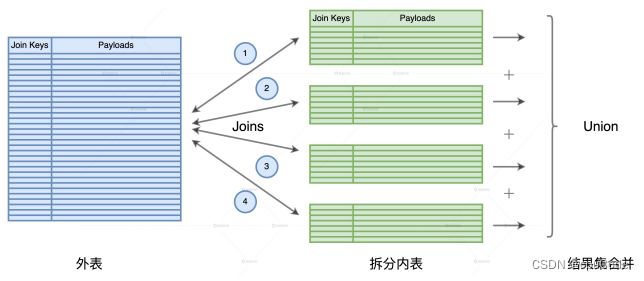
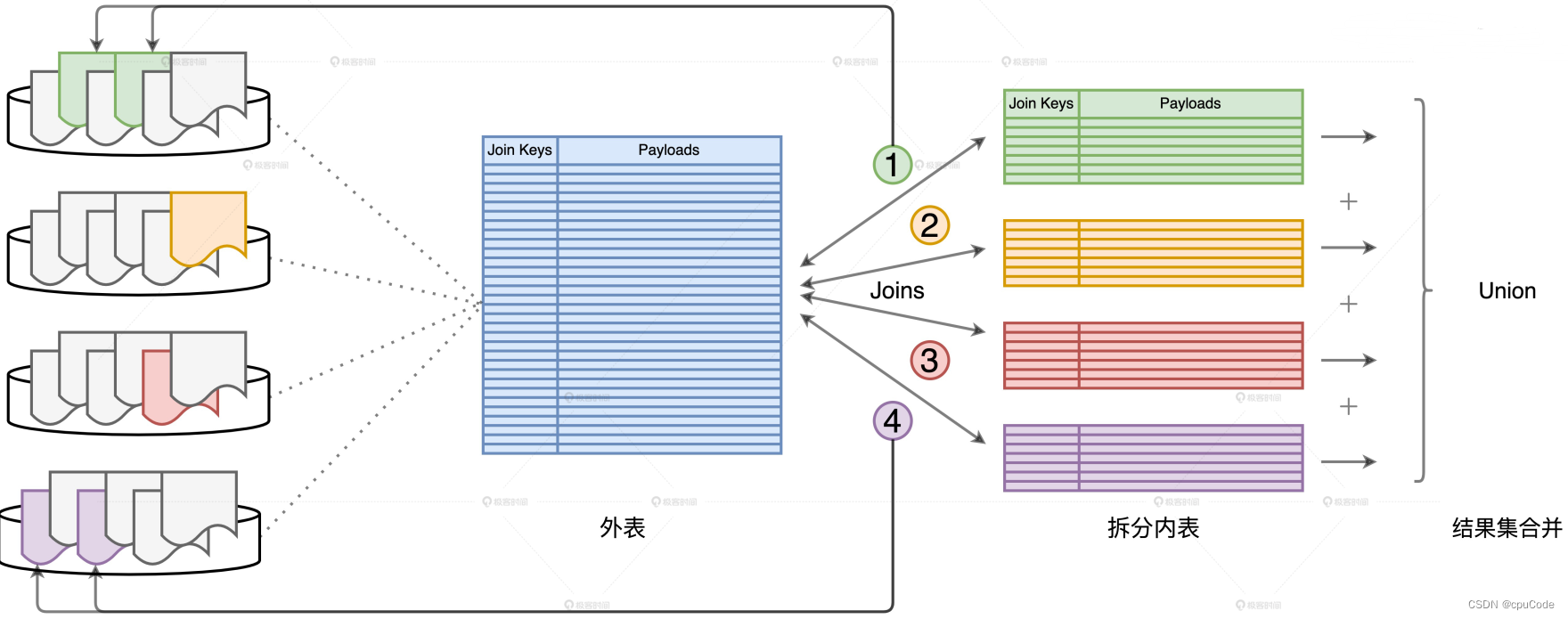
解决数据重复扫描:
- Cache,要求资源非常吊
- 用 DPP 机制,对外表进行分区过滤
DPP 机制:
- 每个子查询只扫描外表的子集,把所有子集加起来,就是外表的全量数据
案例
orders 和 transactions 都是事实表,都是 TB 级别 :
scala">//orders 订单表
orderId: Int
customerId: Int
status: String
date: Date //分区键
//lineitems 交易明细表
orderId: Int //分区键
txId: Int
itemId: Int
price: Float
quantity: Int
每隔一段时间 ,计算上个季度所有订单的交易额 :
scala">val query: String = "
select sum(tx.price * tx.quantity) as revenue,
o.orderId
from transactions as tx
inner join orders as o on tx.orderId = o.orderId
where o.status = 'COMPLETE'
and o.date between '2020-01-01' and '2020-03-31'
group by o.orderId
"
transactions 是外表,orders 是内表(较小)
- 对 date 字段进行以天拆分
scala">//以date字段拆分内表
val query: String = "
select sum(tx.price * tx.quantity) as revenue,
o.orderId
from transactions as tx
inner join orders as o on tx.orderId = o.orderId
where o.status = 'COMPLETE'
and o.date = '2020-01-01'
group by o.orderId
"
内表拆分后,外表与所有子表做关联,把全部子关联的结果合并
scala">//循环遍历 dates
val dates: Seq[String] = Seq("2020-01-01", "2020-01-02",..."2020-03-31")
for (date <- dates) {
val query: String = s"
select sum(tx.price * tx.quantity) as revenue,
o.orderId
from transactions as tx inner
join orders as o on tx.orderId = o.orderId
where o.status = 'COMPLETE'
and o.date = ${date}
group by o.orderId
"
val file: String = s"${outFile}/${date}"
spark.sql(query).save.parquet(file)
}
负隅顽抗
负隅顽抗 : 当内表没法均匀拆分,或外表没有分区键,不能利用 DPP,只能依赖 Shuffle Join,来完成 Join 大大表
数据分布均匀
默认 Shuffle Sort Merge Join 转为 Shuffle Hash Join 条件:
- 两表数据分布均匀
- 内表所有数据分片,能放入内存
每个数据分片的切分 :
- 根据并发度/执行内存,计算每个 Task 消耗的内存上下限
- 结合分布式数据集尺寸与上下限,计算出并行度
利用 Join Hints 选择 Shuffle Hash Join
select /*+ shuffle_hash(orders) */
sum(tx.price * tx.quantity) as revenue,
o.orderId
from transactions as tx inner
join orders as o on tx.orderId = o.orderId
where o.status = 'COMPLETE'
and o.date between '2020-01-01' and '2020-03-31'
group by o.orderId
数据倾斜
Join 大大表数据倾斜情况 :
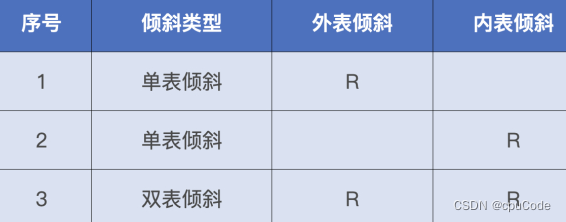
Task 数据倾斜
利用 AQE 解决自动倾斜处理。配置参数 :
spark.sql.adaptive.skewJoin.skewedPartitionFactor: 判定倾斜的膨胀系数spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes: 判定倾斜的最低阈值spark.sql.adaptive.advisoryPartitionSizeInBytes: 定义拆分粒度 (字节)
AQE 自动倾斜处理 :
- 外表的倾斜分区,以
spark.sql.adaptive.advisoryPartitionSizeInBytes把倾斜分区拆分为多个数据分区 - 对内表的数据分区进行复制
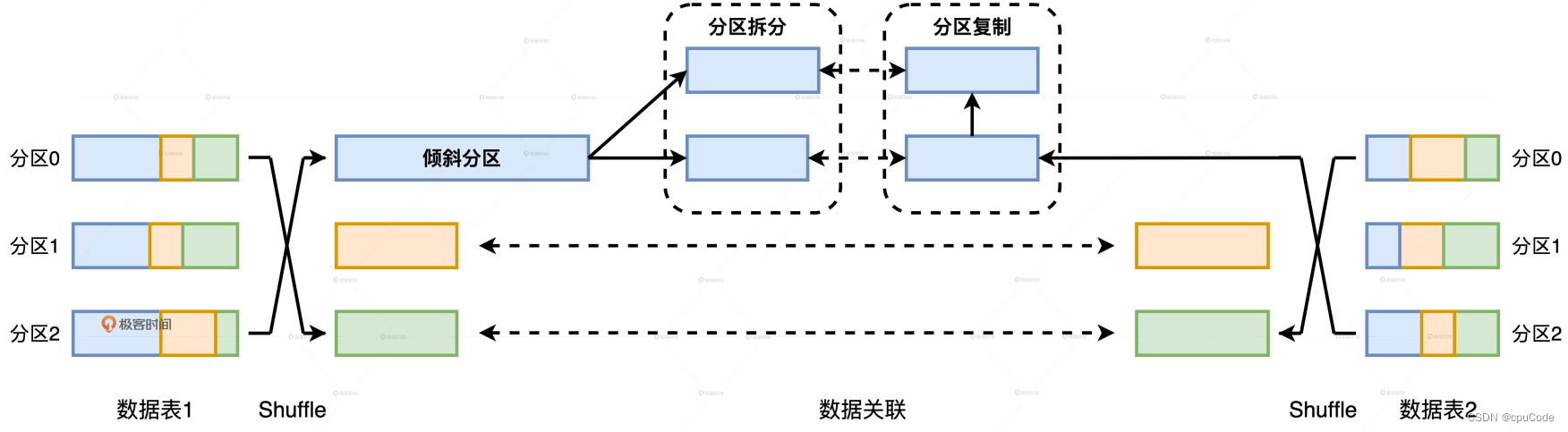
Task 的负载均衡 :
- AQE 只能处理 Task 倾斜,Executors 的负载倾斜并没有改善
Executor 数据倾斜
解决 Executors 的数据倾斜的方法 :分而治之/ 两阶段 Shuffle
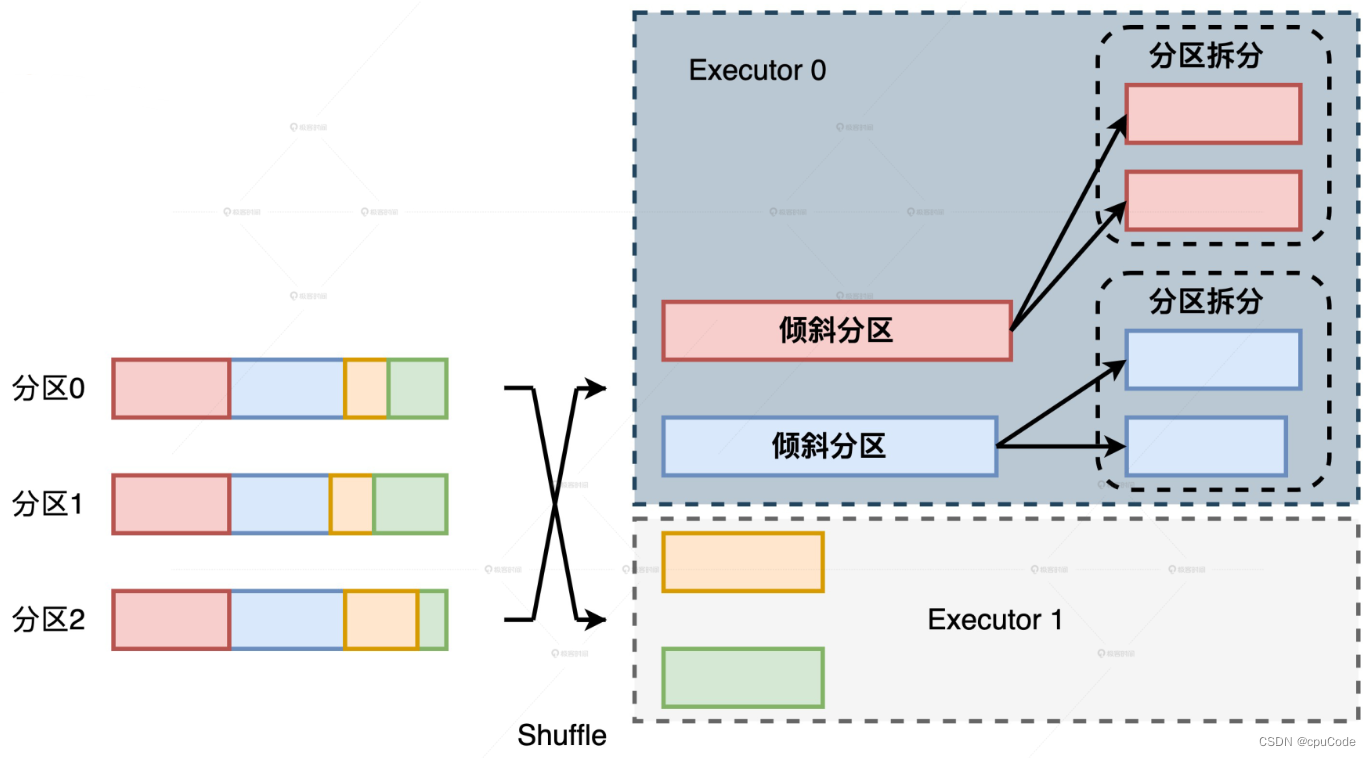
分而治之 :
- 对外表中所有 Join Keys,按照倾斜分为两组 (倾斜的 Join Keys / 分布均匀的 Join Keys)
- 按照两组 Join Keys,对内表分为两份
- 对内外表的两组数据,分别用不同方法做关联计算
- 分布均匀的数据,把
Shuffle Sort Merge Join转为Shuffle Hash Join - 倾斜数据,用两阶段 Shuffle,平衡 Executors 之间的工作负载
- 再把两个关联结果集进行 Union
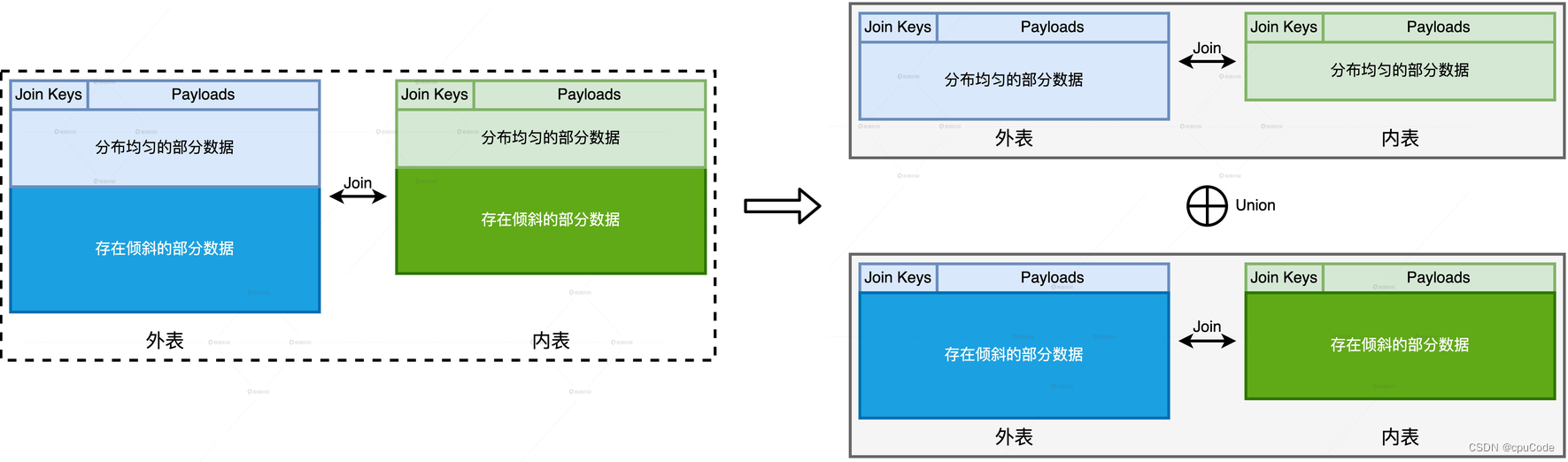
两阶段 Shuffle
两阶段 Shuffle:
- 第一阶段 :目的将数据打散、平衡计算负载,通过
加盐、Shuffle、关联、聚合 - 第二阶段 :计算结果,通过
去盐化、Shuffle、聚合 - 不破坏原有关联关系下,平衡 Executors 之间的计算负载
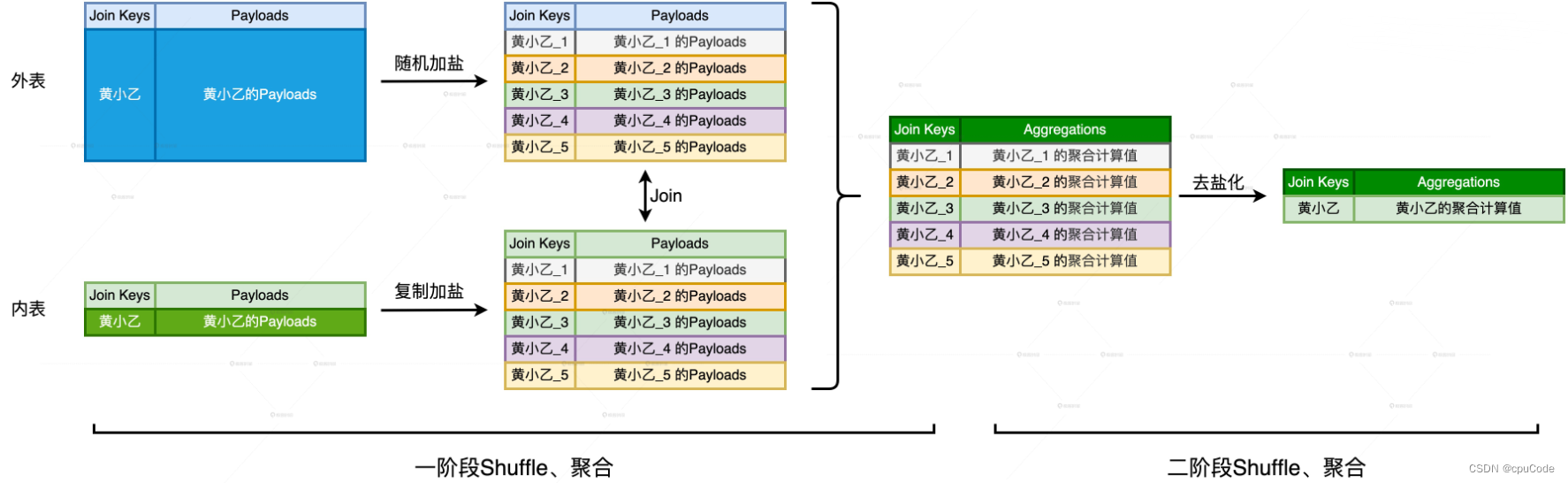
第一阶段:对倾斜 Join Keys 加盐 (粒度 : Executors 总数)
- 外表/内表做不同加盐处理
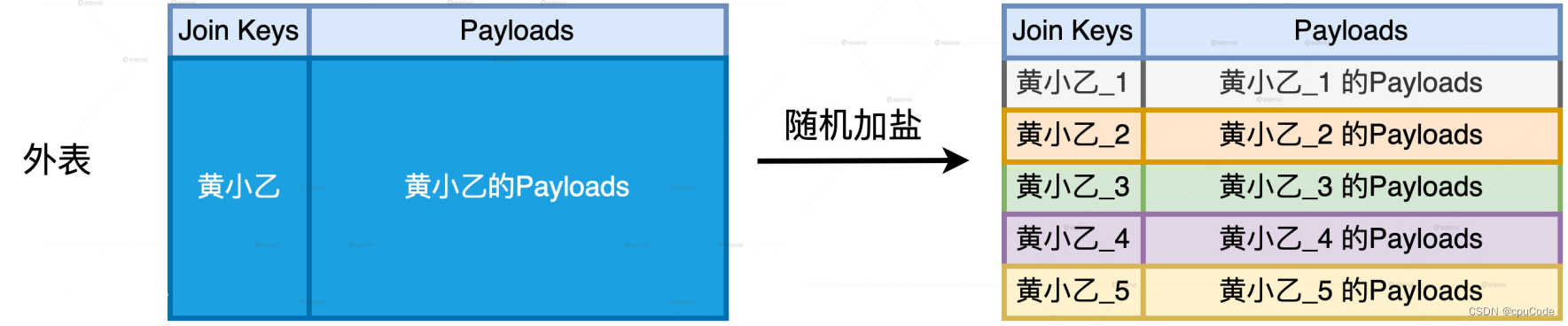
对外表进行随机加盐 :
- 对倾斜的 Join Key,都 + 随机后缀 (1 - #N)
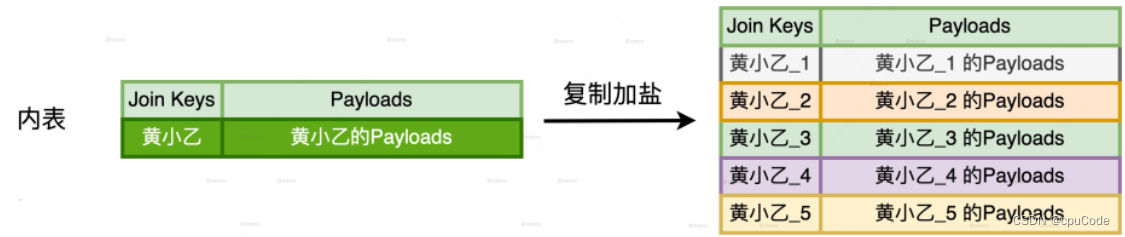
内表进行复制加盐 :
- 对倾斜的 Join Key,把原数据复制 (Executors 总数 – 1),得到 (Executors 总数) 份数据副本
- 对每份副本,按 Join Key +固定后缀 (1 - #N) ,与打散后的外表数据保持一致
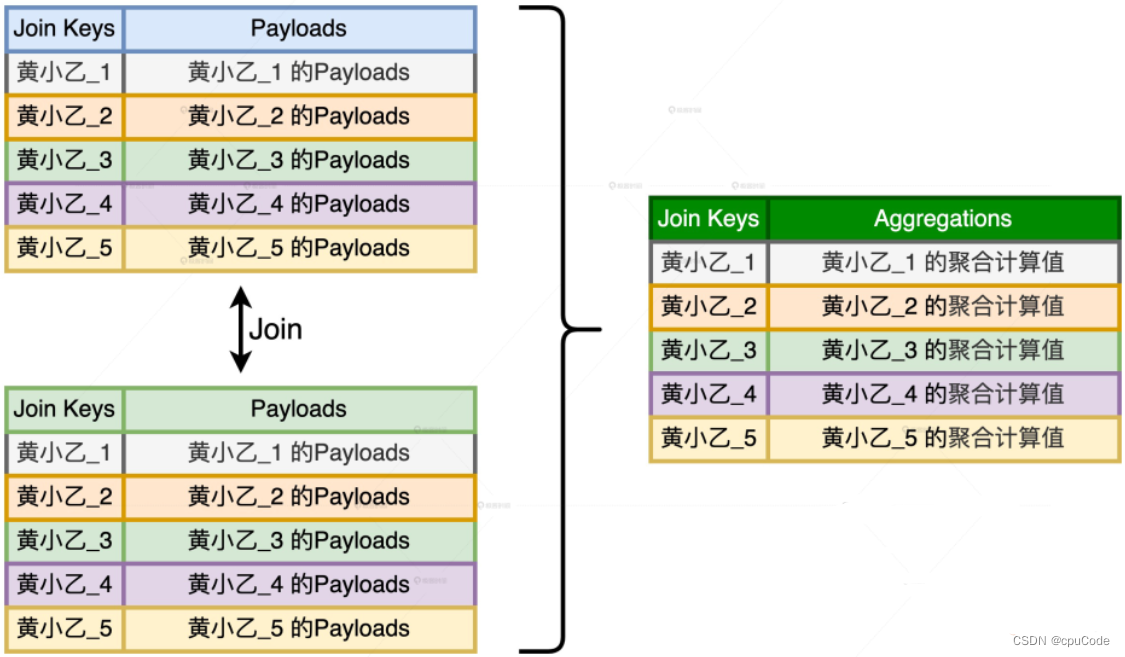
第二阶段 :
- 把每个 Join Key 的后缀去掉 (去盐化)
- 按照原来的 Join Key 进行 Shuffle 和聚合计算,得出倾斜组的计算结果
- 将倾斜的结果和均匀的结果进行合并
Executors 调优案例
orders 和 transactions 都 TB 级别的事实表,计算上个季度所有订单的交易额
scala">//统计订单交易额的代码实现
val txFile: String = _
val orderFile: String = _
val transactions: DataFrame = spark.read.parquent(txFile)
val orders: DataFrame = spark.read.parquent(orderFile)
transactions.createOrReplaceTempView("transactions")
orders.createOrReplaceTempView(“orders”)
val query: String = "
select sum(tx.price * tx.quantity) as revenue,
o.orderId
from transactions as tx
inner join orders as o on tx.orderId = o.orderId
where o.status = 'COMPLETE'
and o.date between '2020-01-01' and '2020-03-31'
group by o.orderId
"
val outFile: String = _
spark.sql(query).save.parquet(outFile)
把倾斜的 orderId 保存在数组 skewOrderIds 中,把均匀的 orderId 保持在数组 evenOrderIds 中
scala">//根据Join Keys是否倾斜、将内外表分别拆分为两部分
import org.apache.spark.sql.functions.array_contains
//将Join Keys分为两组,存在倾斜的、和分布均匀的
val skewOrderIds: Array[Int] = _
val evenOrderIds: Array[Int] = _
val skewTx: DataFrame =
transactions.filter(array_contains(lit(skewOrderIds), $"orderId")
val evenTx: DataFrame =
transactions.filter(array_contains(lit(evenOrderIds), $"orderId")
val skewOrders: DataFrame =
orders.filter(array_contains(lit(skewOrderIds), $"orderId"))
val evenOrders: DataFrame =
orders.filter(array_contains(lit(evenOrderIds), $"orderId"))
对均匀数据,转为 Shuffle Hash Join:
scala">//将分布均匀的数据分别注册为临时表
evenTx.createOrReplaceTempView("evenTx")
evenOrders.createOrReplaceTempView("evenOrders")
val evenQuery: String = "
select /*+ shuffle_hash(orders) */
sum(tx.price * tx.quantity) as revenue,
o.orderId
from evenTx as tx
inner join evenOrders as o on tx.orderId = o.orderId
where o.status = 'COMPLETE'
and o.date between '2020-01-01' and '2020-03-31'
group by o.orderId
"
val evenResults: DataFrame = spark.sql(evenQuery)
对外表做随机加盐,对内表做复制加盐
scala">import org.apache.spark.sql.functions.udf
//定义获取随机盐粒的UDF
val numExecutors: Int = _
val rand = () => scala.util.Random.nextInt(numExecutors)
val randUdf = udf(rand)
//第一阶段的加盐。注意:保留 orderId 字段,用于二阶段的去盐化
//外表随机加盐
val saltedSkewTx =
skewTx.withColumn("joinKey", concat($"orderId", lit("_"), randUdf()))
//内表复制加盐
var saltedskewOrders =
skewOrders.withColumn("joinKey", concat($"orderId", lit("_"), lit(1)))
for (i <- 2 to numExecutors) {
saltedskewOrders = saltedskewOrders union skewOrders.withColumn("joinKey", concat($"orderId", lit("_"), lit(i)))
}
对加盐的两张表,进行查询 :
scala">//将加盐后的数据分别注册为临时表
saltedSkewTx.createOrReplaceTempView(“saltedSkewTx”)
saltedskewOrders.createOrReplaceTempView(“saltedskewOrders”)
val skewQuery: String = "
select /*+ shuffle_hash(orders) */
sum(tx.price * tx.quantity) as initialReven,
o.orderId,
o.joinKey
from saltedSkewTx as tx
inner join saltedskewOrders as o on tx.joinKey = o.joinKey
where o.status = 'COMPLETE'
and o.date between '2020-01-01' and '2020-03-31'
group by o.joinKey
"
//第一阶段: 加盐、Shuffle、关联、聚合后的初步结果
val skewInitialResults: DataFrame = spark.sql(skewQuery)
去盐化目的 :把计算的粒度,从加盐 joinKey 恢复为原来的 orderId
- 只要在 orderId 上进行聚合,就能去盐化
scala">val skewResults: DataFrame =
skewInitialResults.select("initialRevenue", "orderId")
.groupBy(col("orderId"))
.agg(sum(col("initialRevenue")).alias("revenue"))
把倾斜结果和均匀结果进行合并,就能平衡 Executors 计算负载
scala">evenResults union skewResults