1 大数据的概念
大数据:指无法在一定的时间范围内用常规的软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
主要解决海量数据的存储和海量数据的分析计算问题。
2 大数据的特点
大数据的特点简称 4V 特征:
- Volume(数据量大)
- Velocity(速度快)
- Variety(种类繁多)
- Value(价值密度低)
3 大数据生态圈
3.1 Hadoop 是什么
Hadoop是一个由Apache基金会所开发的分布式系统基础架构,主要解决海量数据的存储和海量数据的分析计算问题。从广义来说,Hadoop通常指的是一个更广泛的概念——Hadoop生态圈。
3.2 Hadoop 的来源
Google是Hadoop的思想之源,(Google在大数据方面的三篇论文)
- GFS ——> HDFS
- MapReduce ——> MR
- BigTable ——> HBase
3.3 Hadoop的特点
- 高容错性 :能够自动将失败的任务重新分配
- 高可靠性:Hadoop底层维护多个数据副本,所以即使Hadoop某个计算元素或存储出现故障,也不会导致数据的丢失
- 高扩展性:在集群间分配任务数据,可方便的扩展数以千计的节点
- 高效性:在MapReduce的思想下,Hadoop并行工作,以加快任务处理速度
3.4 Hadoop的组成
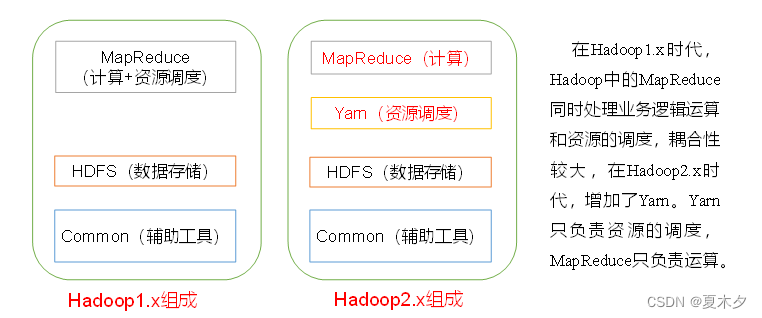
注意:
模块间联系越多,其耦合性越强,同时表明其独立性越差
3.4.1 HDFS
HDFS架构:
- NameNode(nn):存索引,存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间、副本数、文件权限),以及每个文件的块列表和块所在的DataNode等。
- DataNode(dn):存数据,在本地文件系统存储文件块数据,以及块数据的校验和
- Secondary NameNode(2nn):NameNode的助手,但不能说是其备份,用来监控HDFS状态的辅助后台程序,每隔一段时间获取HDFS元数据地快照
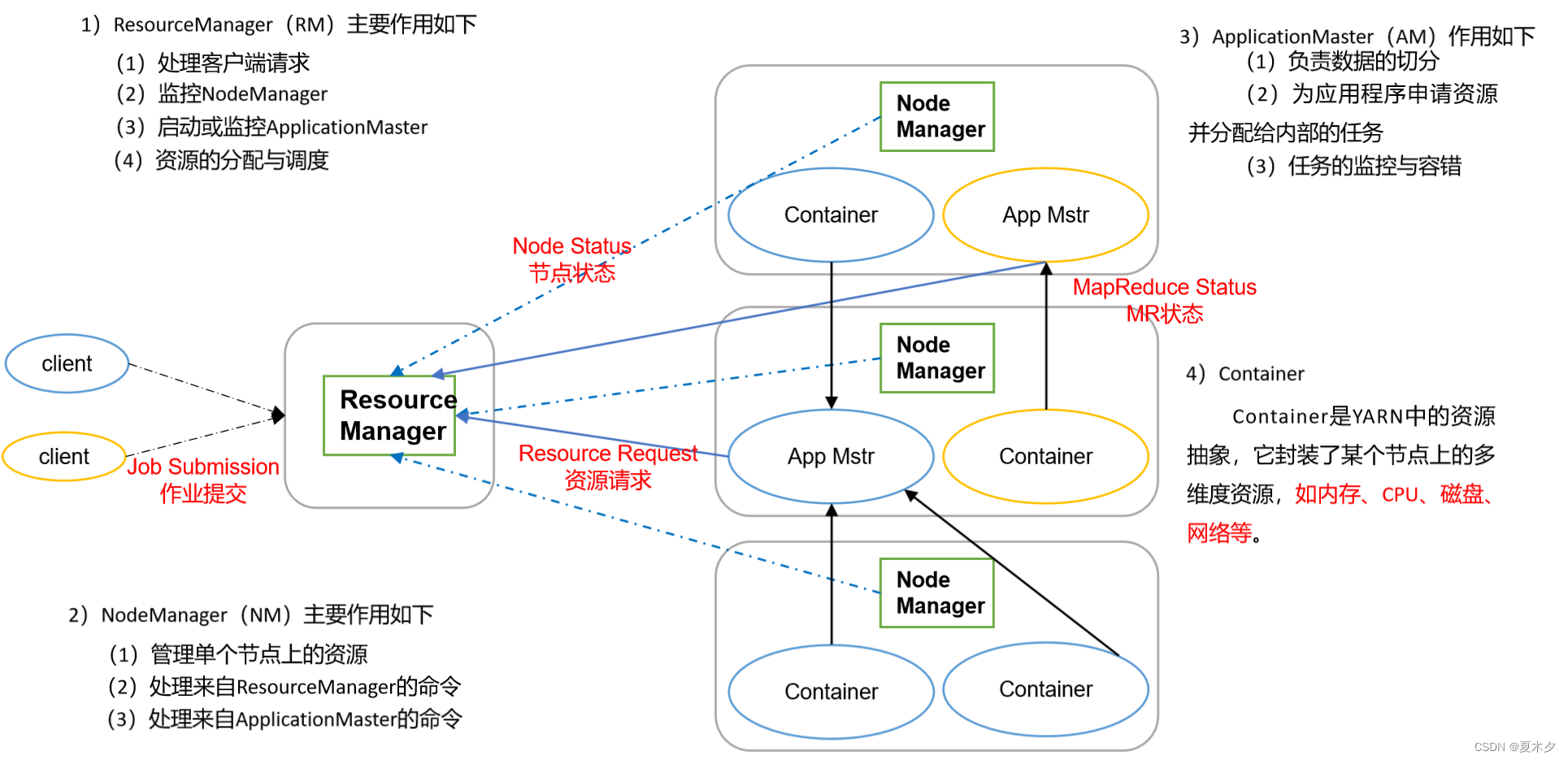
3.4.2 YARN
3.4.3 MapReduce
MapReduce将计算过程分为两个阶段:Map和Reduce
- Map阶段并行处理输入数据
- Reduce阶段对Map结果进行汇总