HDFS__0">HDFS 伪分布式环境搭建
作者:Grey
原文地址:
博客园:HDFS 伪分布式环境搭建
CSDN:HDFS 伪分布式环境搭建
相关软件版本
-
Hadoop 2.6.5
-
CentOS 7
-
Oracle JDK 1.8
安装步骤
在CentOS 下安装 Oracle JDK 1.8
下载地址
将下载好的 JDK 的安装包 jdk-8u202-linux-x64.tar.gz 上传到应用服务器的/tmp目录下
执行以下命令
cd /usr/local && mkdir jdk && tar -zxvf /tmp/jdk-8u202-linux-x64.tar.gz -C ./jdk --strip-components 1
执行下面两个命令配置环境变量
echo "export JAVA_HOME=/usr/local/jdk" >> /etc/profile
echo "export PATH=\$PATH:\$JAVA_HOME/bin" >> /etc/profile
然后执行
source /etc/profile
验证 JDK 是否安装好,输入
java -version
显示如下内容
'java version "1.8.0_202"
Java(TM) SE Runtime Environment (build 1.8.0_202-b08)
Java HotSpot(TM) 64-Bit Server VM (build 25.202-b08, mixed mode)
JDK 安装成功。
创建如下目录:
mkdir /opt/bigdata
将 Hadoop 安装包下载至/opt/bigdata目录下
下载方式一
执行:yum install -y wget
然后执行如下命令:cd /opt/bigdata/ && wget https://archive.apache.org/dist/hadoop/common/hadoop-2.6.5/hadoop-2.6.5.tar.gz
下载方式二
如果报错或者网络不顺畅,可以直接把下载好的安装包上传到/opt/bigdata/目录下
下载地址
配置静态ip
vi /etc/sysconfig/network-scripts/ifcfg-ens33
内容参考如下内容修改
修改BOOTPROTO="static"
新增:
IPADDR="192.168.150.137"
NETMASK="255.255.255.0"
GATEWAY="192.168.150.2"
DNS1="223.5.5.5"
DNS2="114.114.114.114"
然后执行service network restart
设置主机名vi /etc/sysconfig/network
设置为
NETWORKING=yes
HOSTNAME=node01
注:HOSTNAME 自己定义即可,主要要和后面的 hosts 配置中的一样。
设置本机的ip到主机名的映射关系:vi /etc/hosts
192.168.150.137 node01
注:IP 根据你的实际情况来定
重启网络service network restart
执行如个命令,关闭防火墙
systemctl stop firewalld.service
systemctl disable firewalld.service
firewall-cmd --reload
service iptables stop
chkconfig iptables off
关闭 selinux:执行vi /etc/selinux/config
设置
SELINUX=disabled
做时间同步yum install ntp -y
修改配置文件vi /etc/ntp.conf
加入如下配置:
server ntp1.aliyun.com
启动时间同步服务
service ntpd start
加入开机启动
chkconfig ntpd on
SSH 免密配置,在需要远程到这个服务器的客户端中
执行ssh localhost
依次输入:yes
然后输入:本机的密码
生成本机的密钥和公钥:
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
在服务器上配置免密:
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
在客户端再次执行ssh localhost
发现可以免密登录,不需要输入密码了
接下来安装 hadoop 安装包,执行
cd /opt/bigdata && tar xf hadoop-2.6.5.tar.gz
然后执行:
mv hadoop-2.6.5 hadoop
添加环境变量vi /etc/profile
加入如下内容:
export JAVA_HOME=/usr/local/jdk
export HADOOP_HOME=/opt/bigdata/hadoop
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
然后执行source /etc/profile
Hadoop 配置
执行vi $HADOOP_HOME/etc/hadoop/hadoop-env.sh
配置 JAVA_HOME
export JAVA_HOME=/usr/local/jdk
执行vi $HADOOP_HOME/etc/hadoop/core-site.xml
在<configuration></configuration>节点内配置:
<property>
<name>fs.defaultFS</name>
<value>hdfs://node01:9000</value>
</property>
执行vi $HADOOP_HOME/etc/hadoop/hdfs-site.xml
在<configuration></configuration>节点内配置
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name> <value>/var/bigdata/hadoop/local/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/var/bigdata/hadoop/local/dfs/data</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node01:50090</value>
</property>
<property>
<name>dfs.namenode.checkpoint.dir</name> <value>/var/bigdata/hadoop/local/dfs/secondary</value>
</property>
执行vi $HADOOP_HOME/etc/hadoop/slaves
配置为node01
初始化和启动 HDFS,执行
hdfs namenode -format
创建目录,并初始化一个空的fsimage
如果你使用windows作为客户端,那么需要配置 hosts 条目
进入C:\Windows\System32\drivers\etc
在 host 文件中增加如下条目:
192.168.241.137 node01
注:ip 地址要和你的服务器地址一样
启动 hdfs
执行start-dfs.sh
输入: yes
第一次启动,datanode 和 secondary 角色会初始化创建自己的数据目录
访问:http://node01:50070
并在命令行执行:
hdfs dfs -mkdir /bigdata
hdfs dfs -mkdir -p /user/root
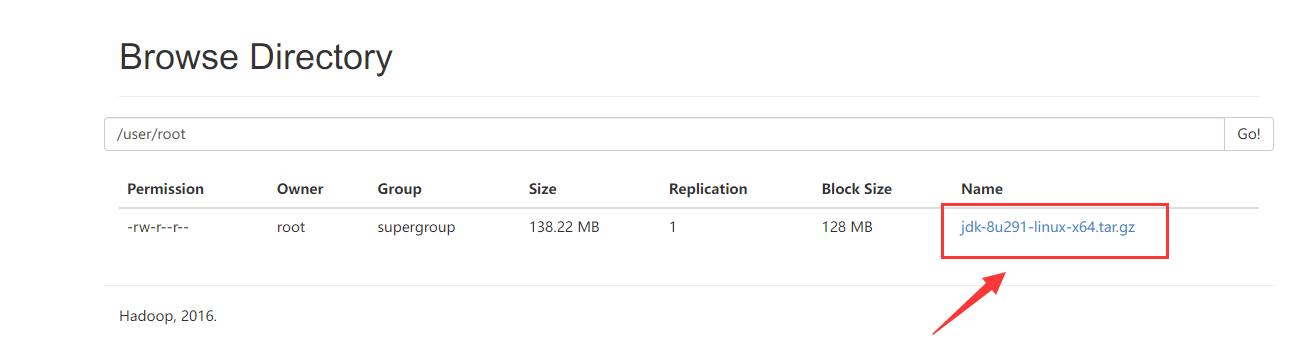
通过 hdfs 上传文件:
hdfs dfs -put jdk-8u291-linux-x64.tar.gz /user/root
通过:http://node01:50070/explorer.html#/user/root
可以看到上传的文件
参考资料
Hadoop MapReduce Next Generation - Setting up a Single Node Cluster.



![bzoj 3597: [Scoi2014]方伯伯运椰子[分数规划]](http://www.lydsy.com/JudgeOnline/upload/201503/f1.PNG)