1. 前提准备
-
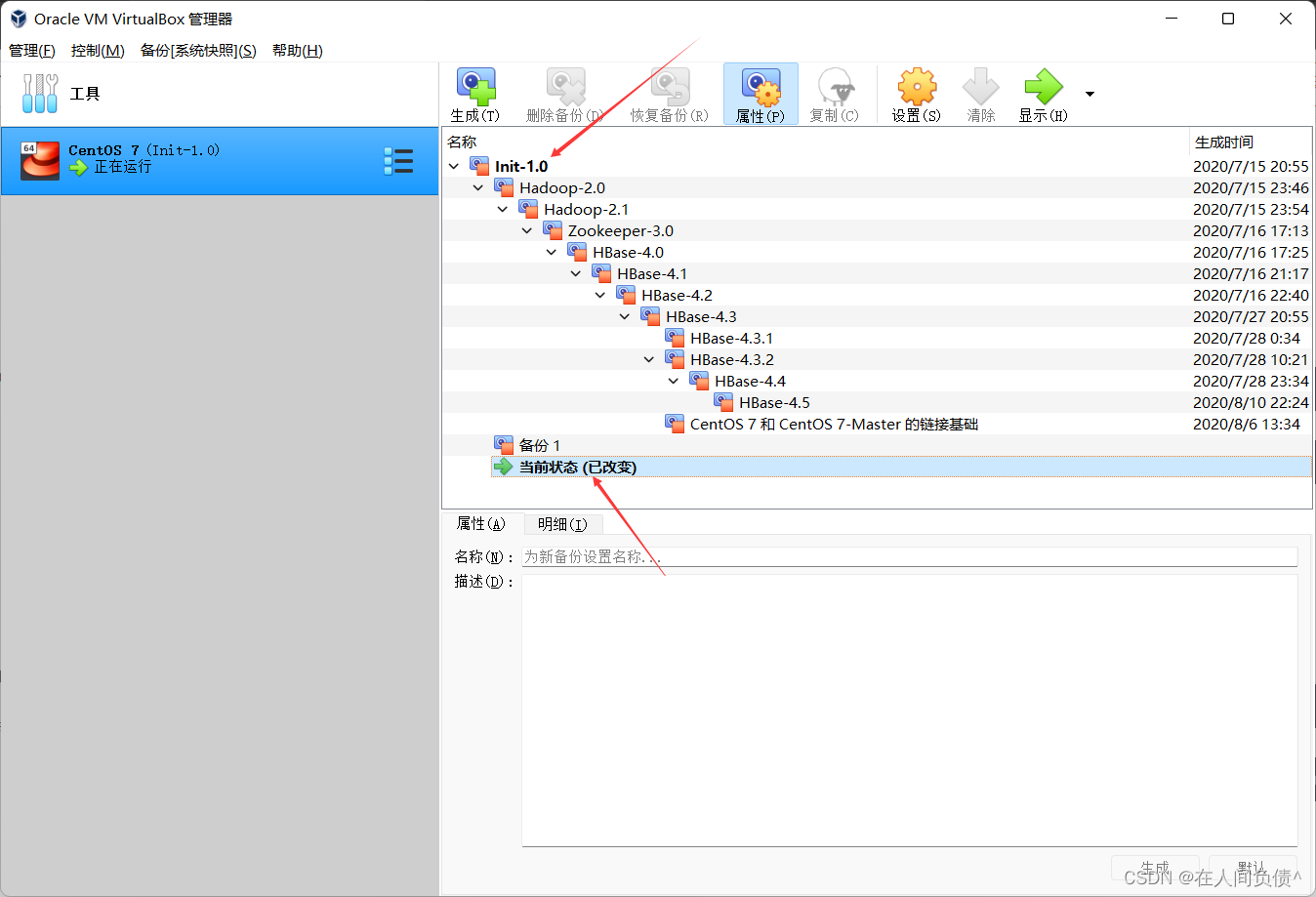
启动镜像 Init1.0
-
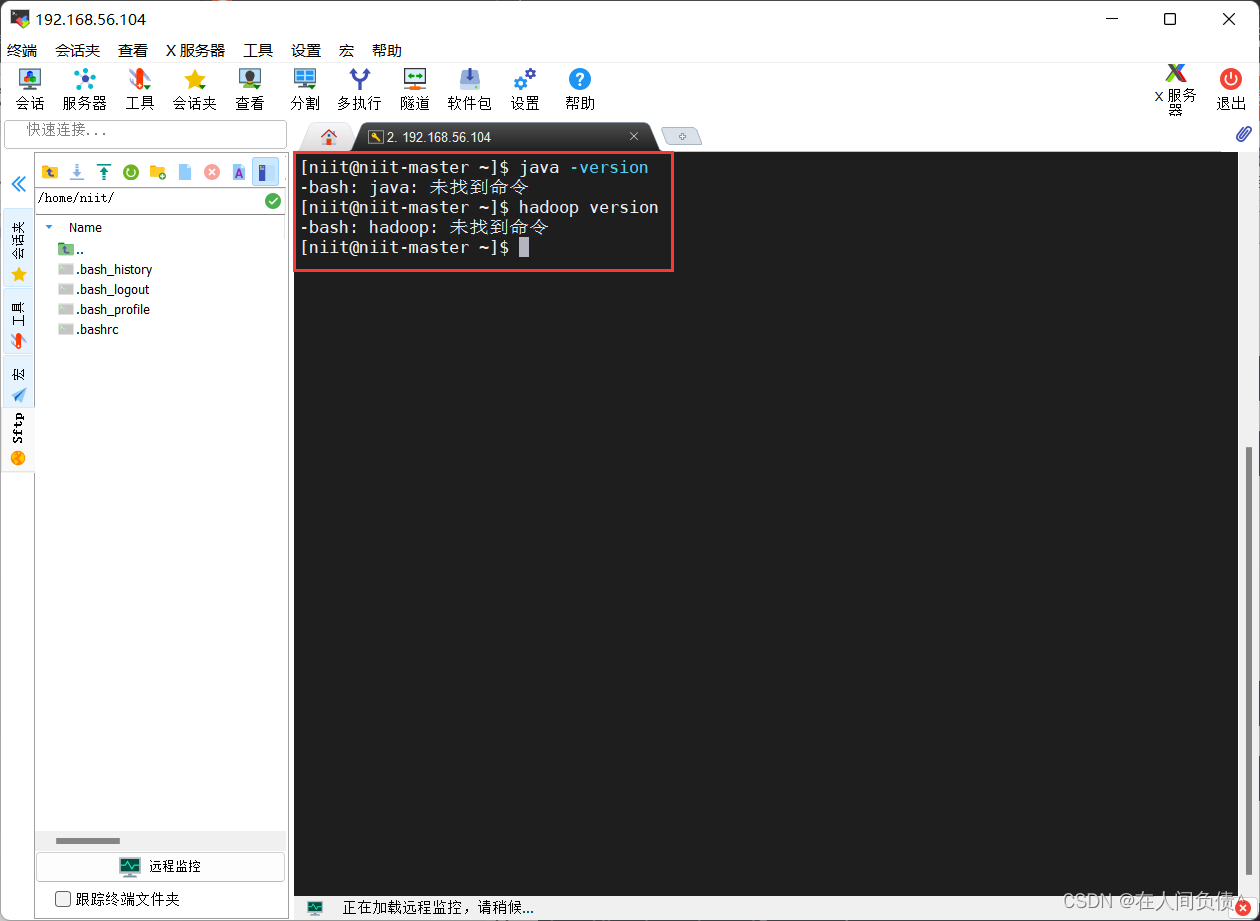
检查是否安装 Hdoop 和 jdk
[niit@niit-master ~]$ java -version
[niit@niit-master ~]$ hadoop version
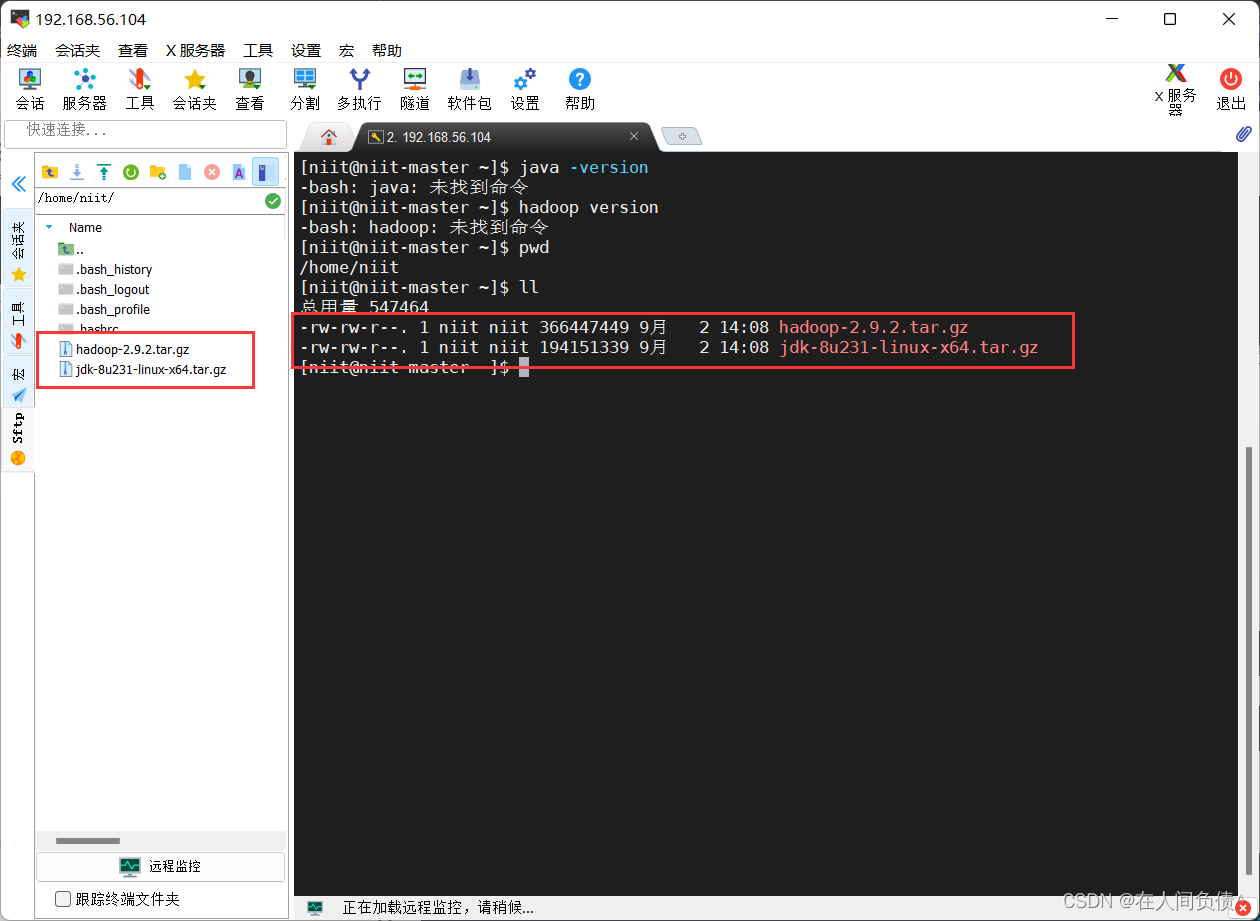
hadoopjdk_17">2. 安装hadoop和jdk
[niit@niit-master ~]$ tar -zxvf hadoop-2.9.2.tar.gz
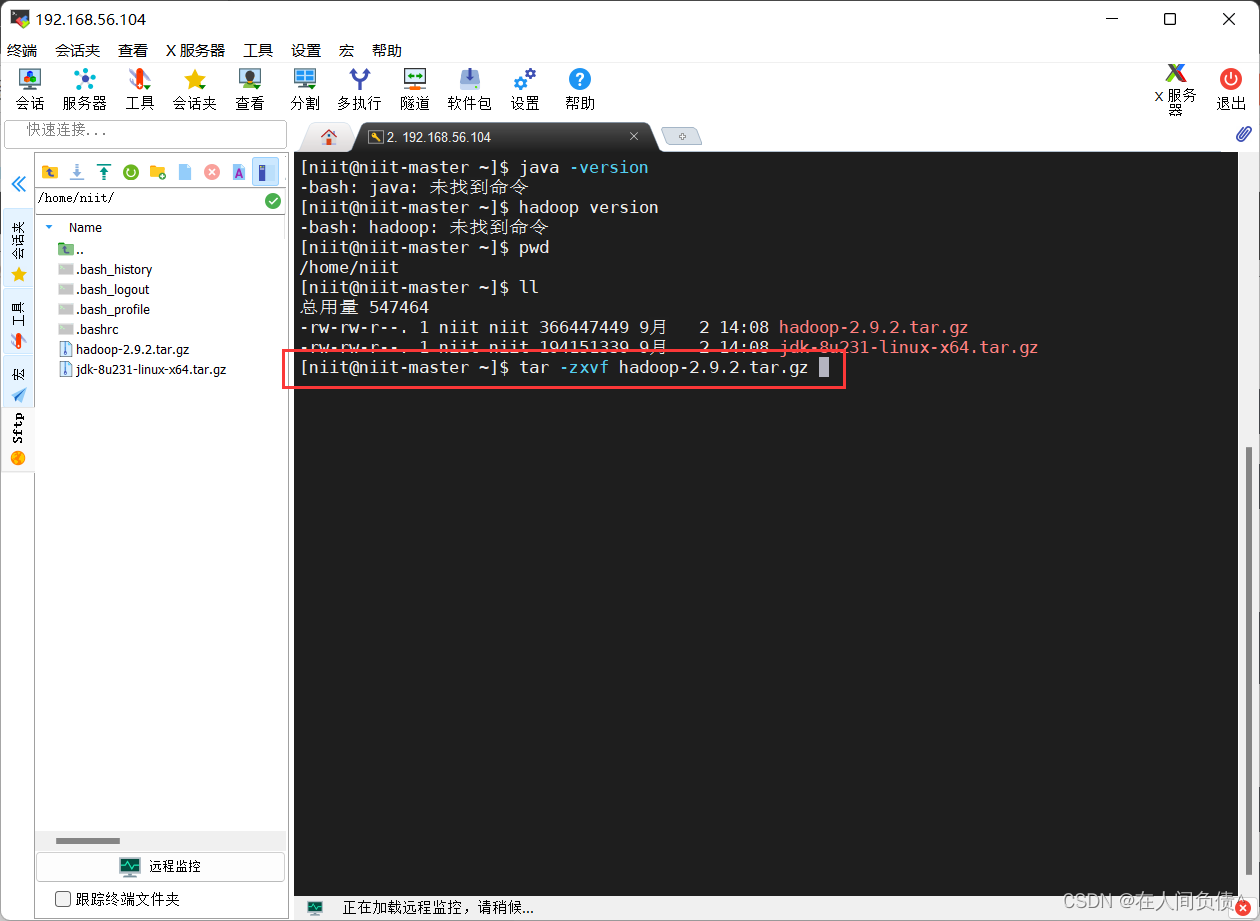
解压完毕
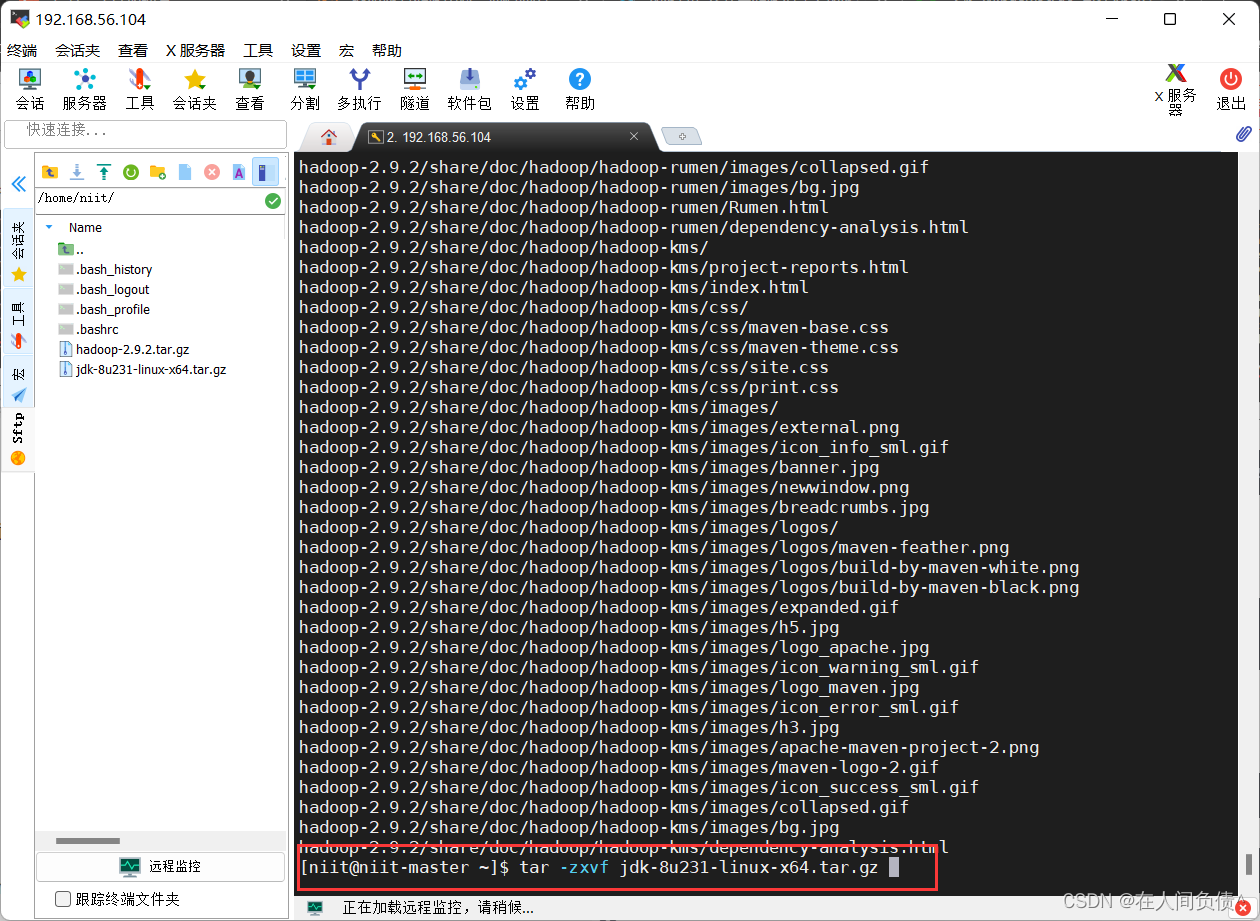
[niit@niit-master ~]$ tar -zxvf jdk-8u231-linux-x64.tar.gz
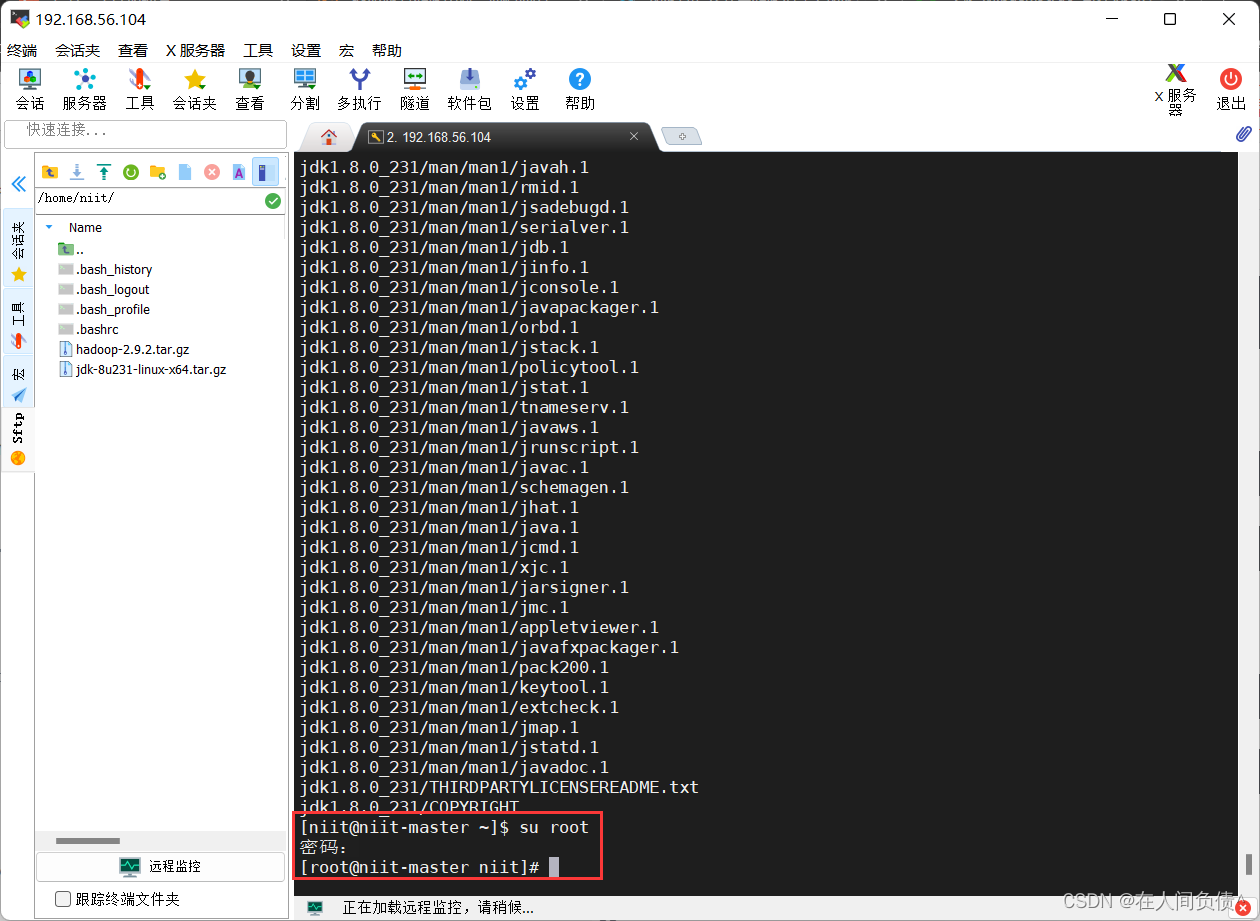
- 切换到 root
[niit@niit-master ~]$ su root
密码:
- 将解压的 hadoop 和 jdk 移动到 /usr/local/
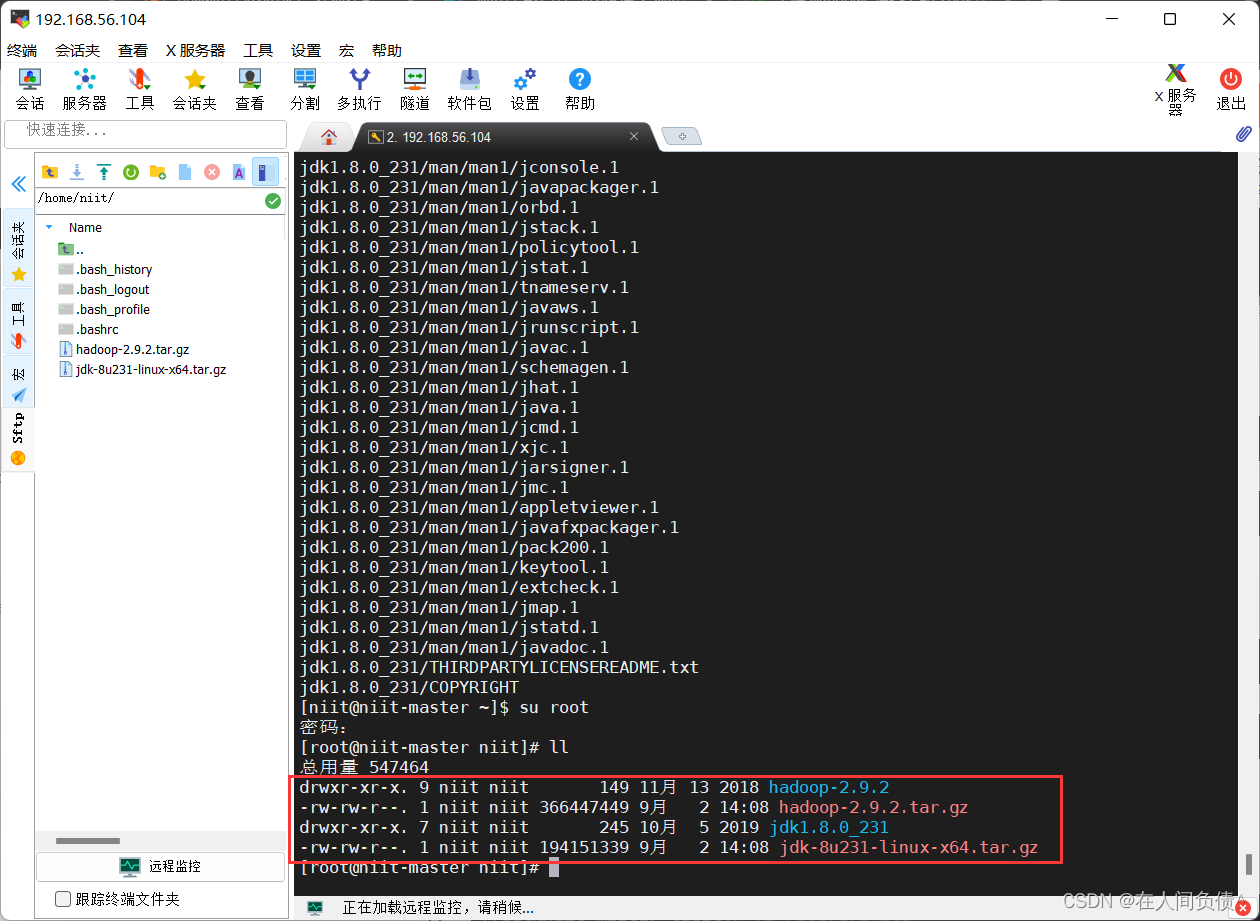
[root@niit-master niit]# mv jdk1.8.0_231/ /usr/local/
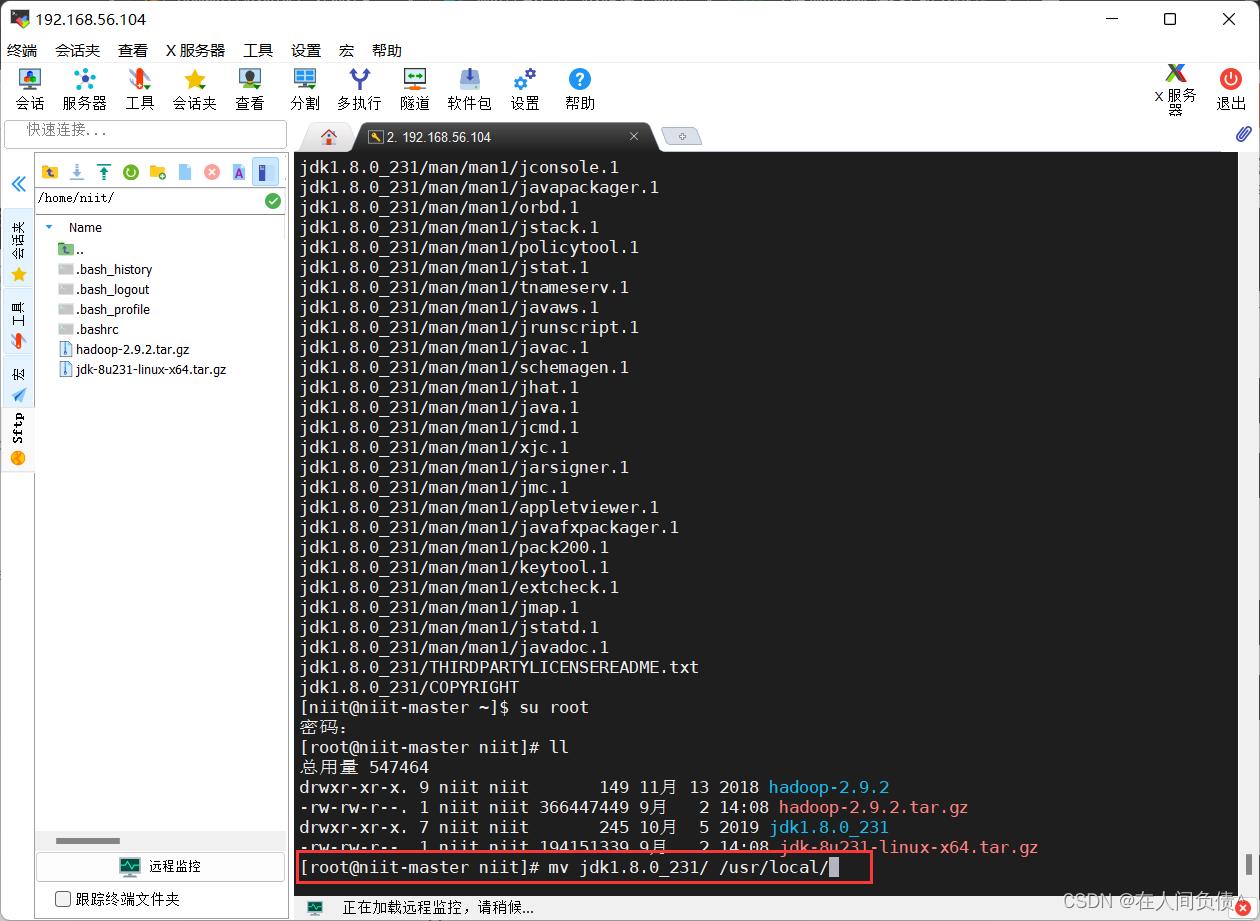
[root@niit-master niit]# mv hadoop-2.9.2 /usr/local/

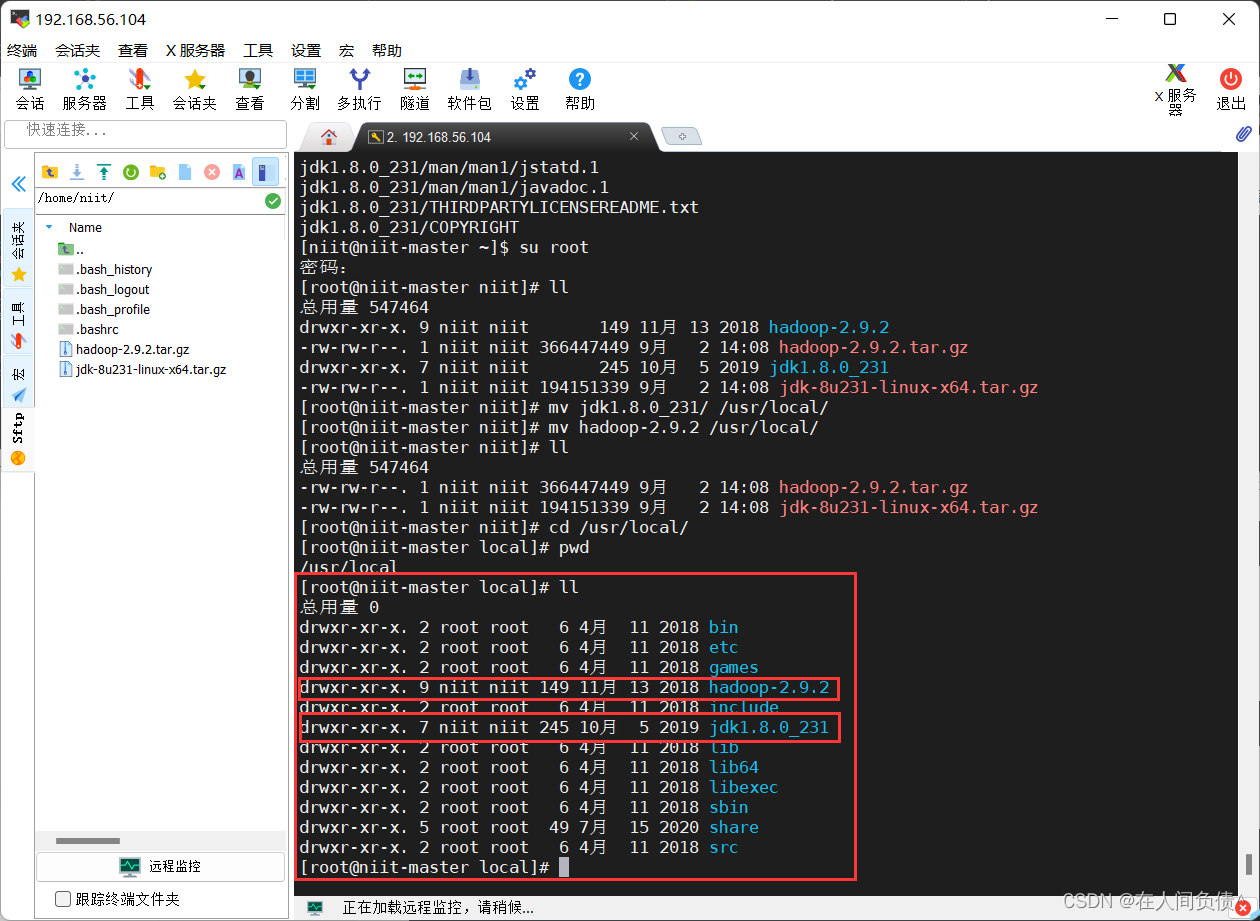
- 进入 /usr/local 查看
[root@niit-master niit]# cd /usr/local/
[root@niit-master local]# ll
- 配置 hadoop 和 jdk 的环境配置
进入/etc/profile文件
[root@niit-master local]# vi /etc/profile
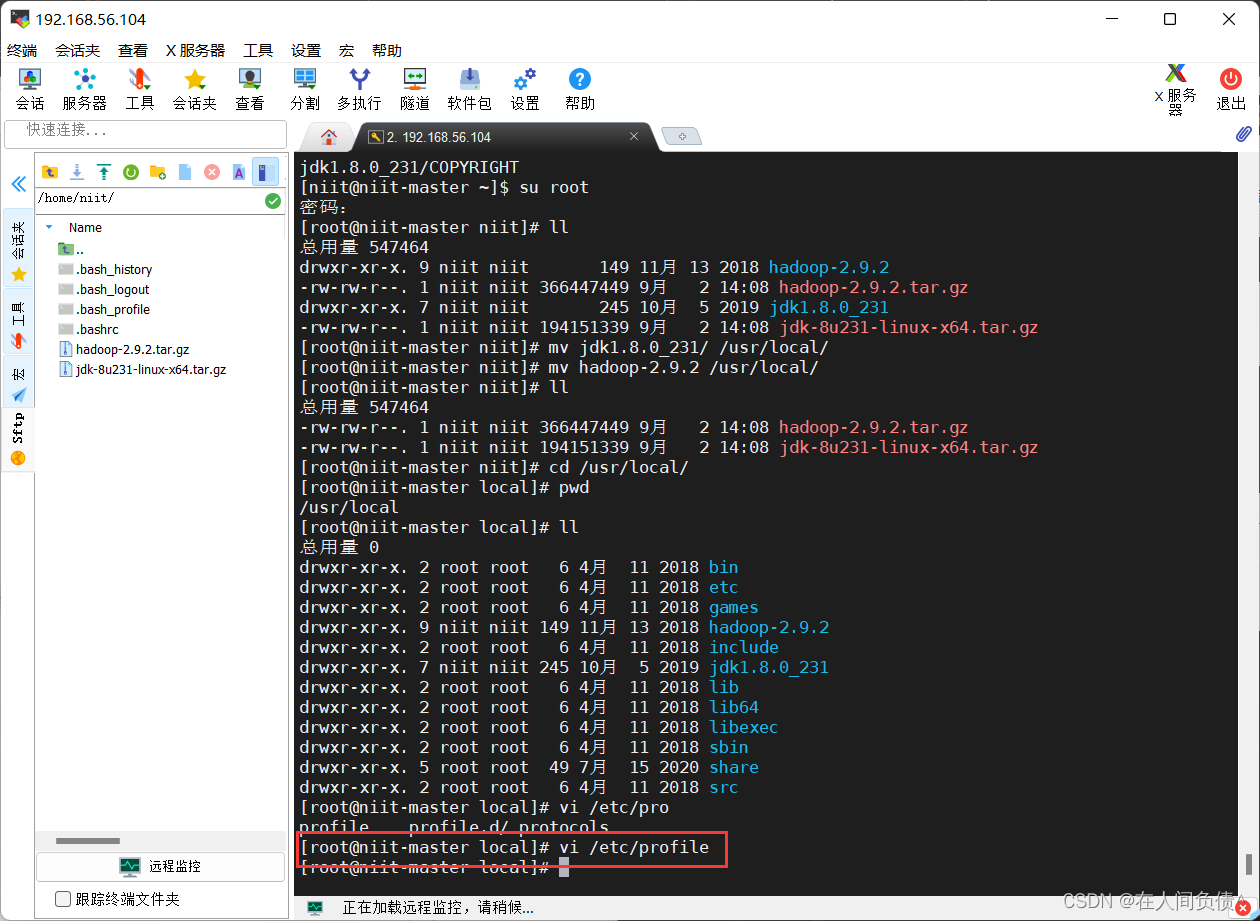
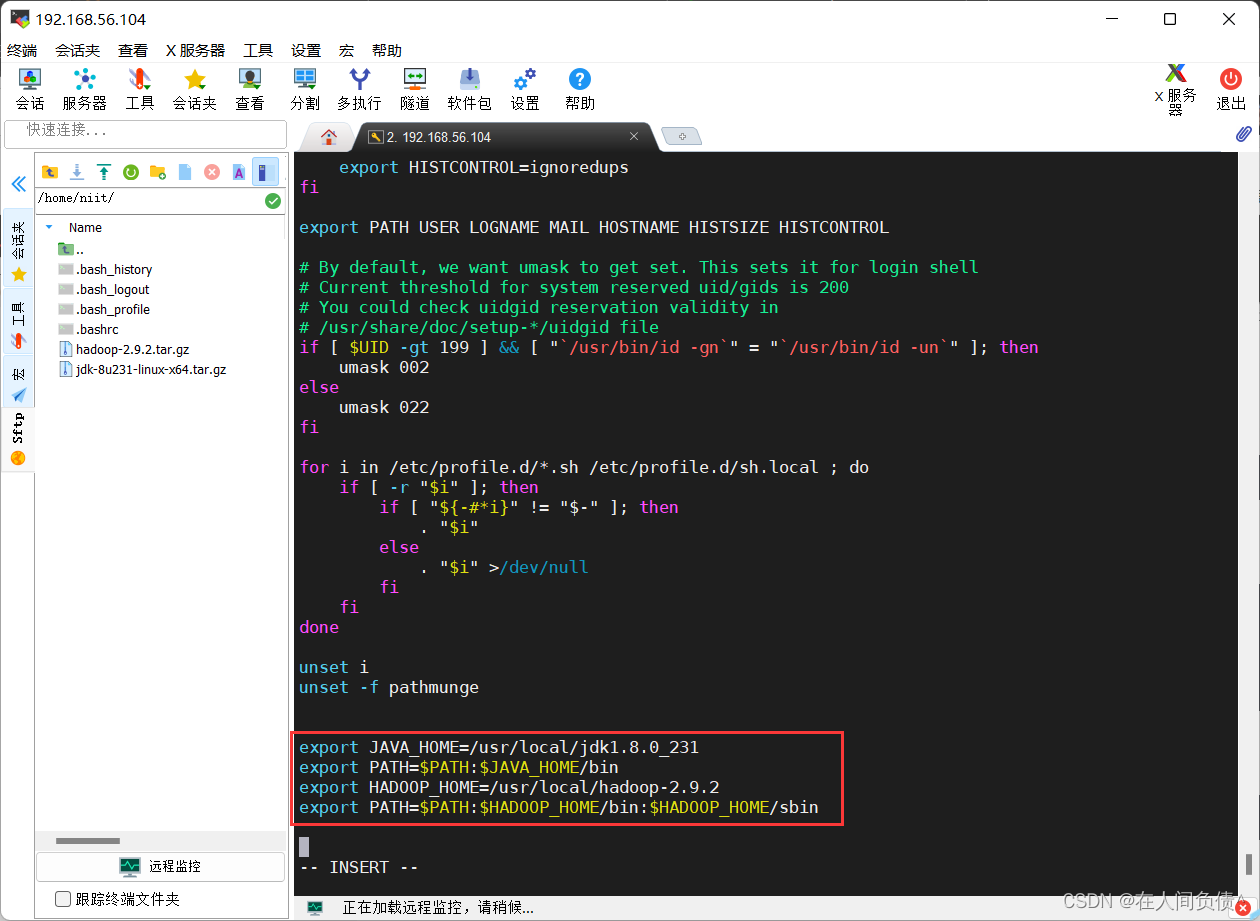
在文件最下面输入下述内容
export JAVA_HOME=/usr/local/jdk1.8.0_231
export PATH=$PATH:$JAVA_HOME/bin
export HADOOP_HOME=/usr/local/hadoop-2.9.2
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
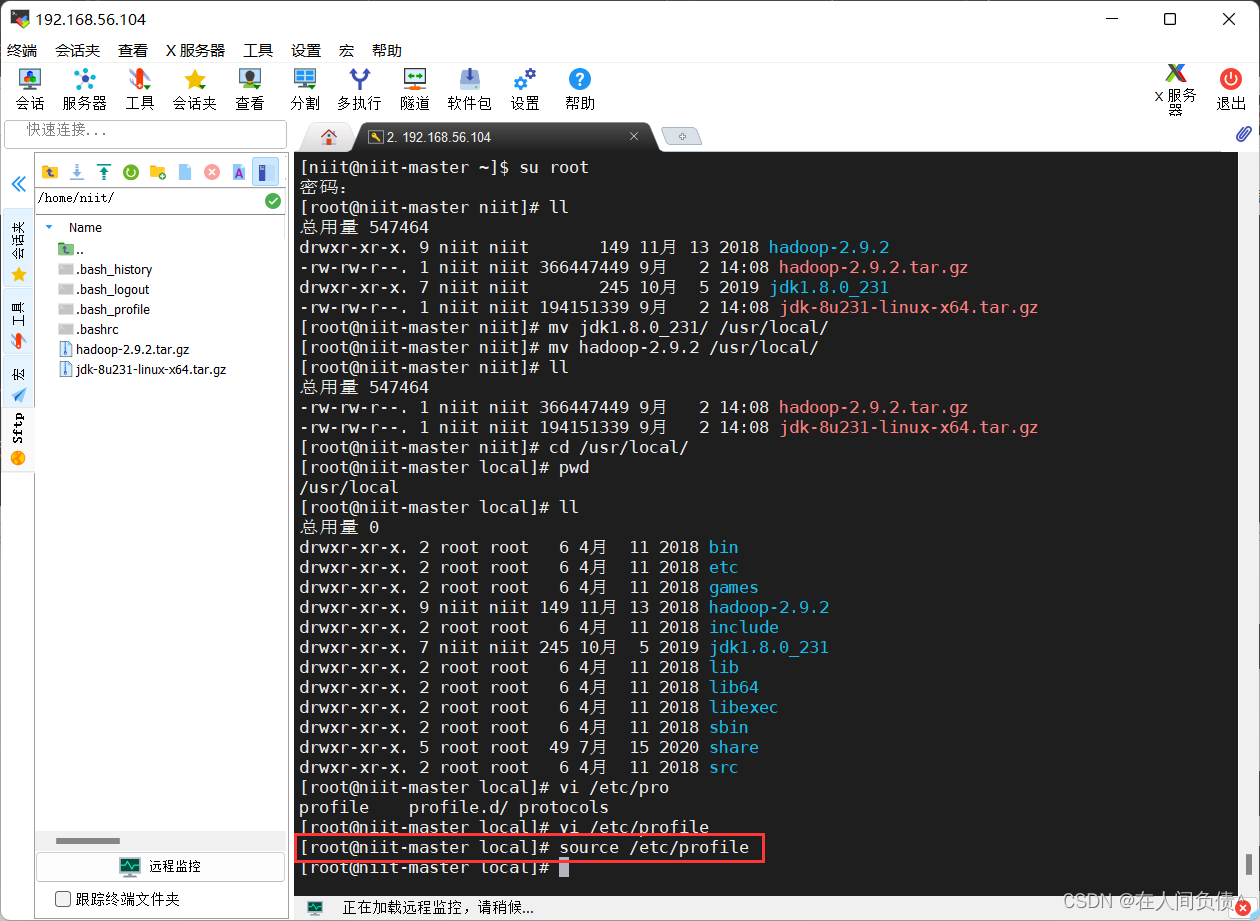
更新配置文件到系统中
[root@niit-master jdk1.8.0_231]# source /etc/profile
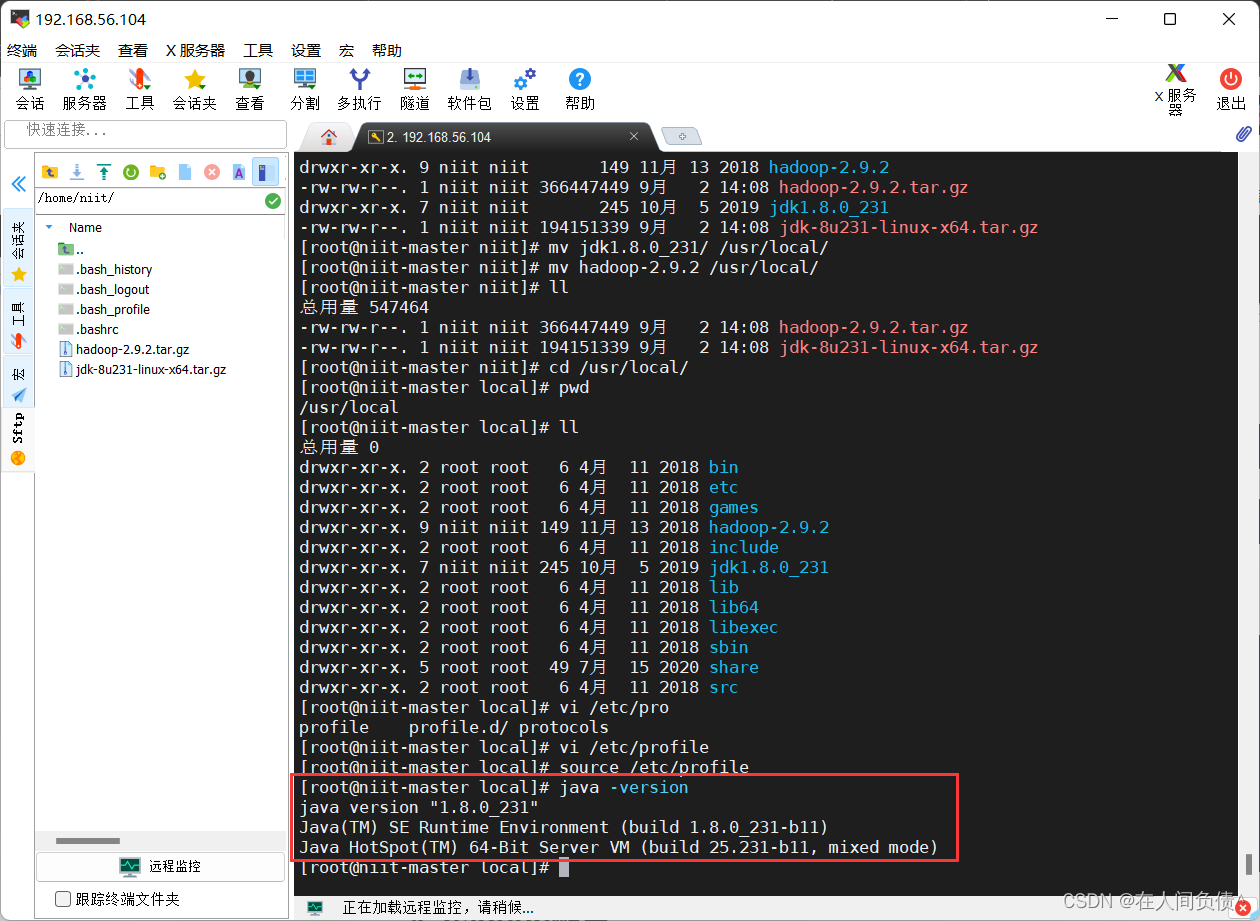
- 检查 jdk 和 hadoop 是否安装成功
[root@niit-master jdk1.8.0_231]# java -version
[root@niit-master jdk1.8.0_231]# hadoop version
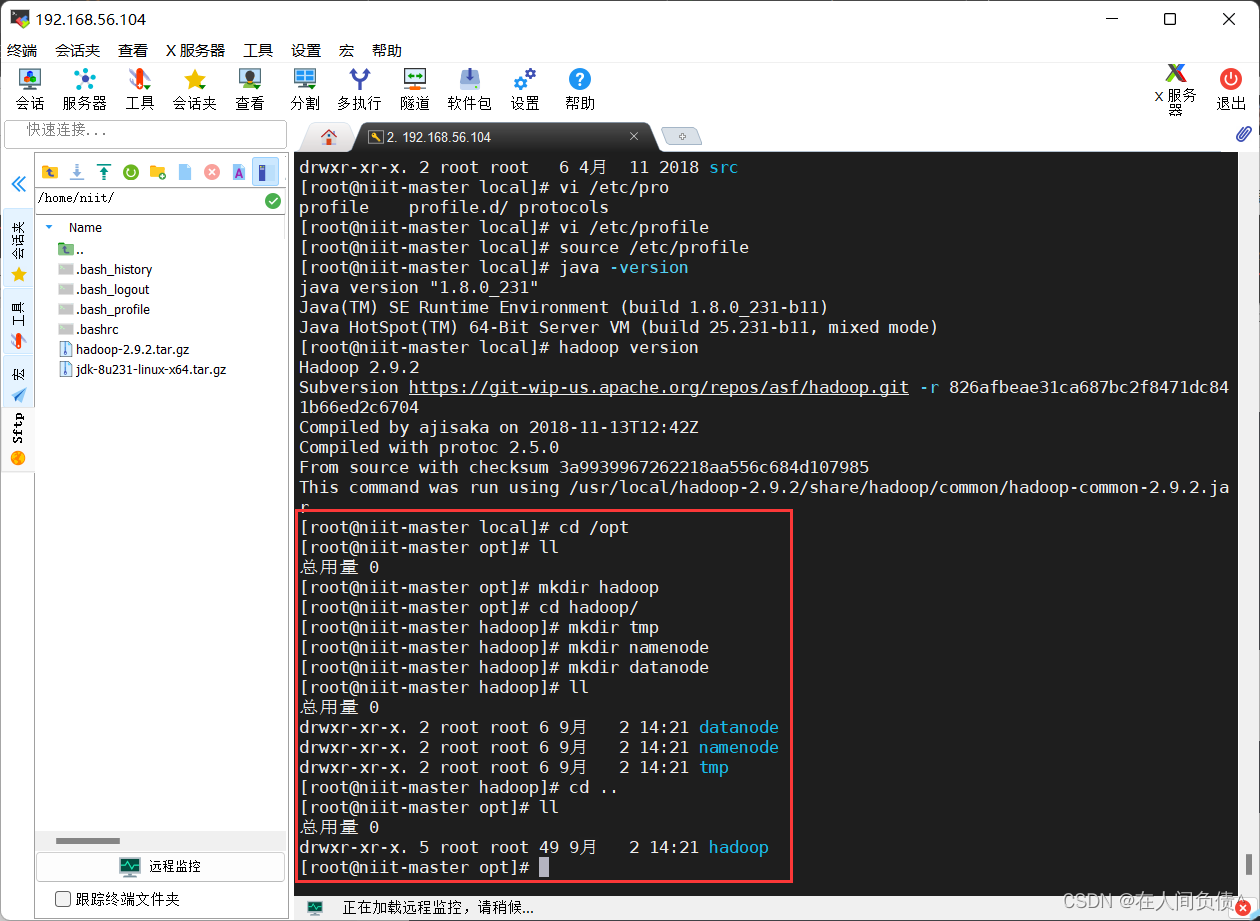
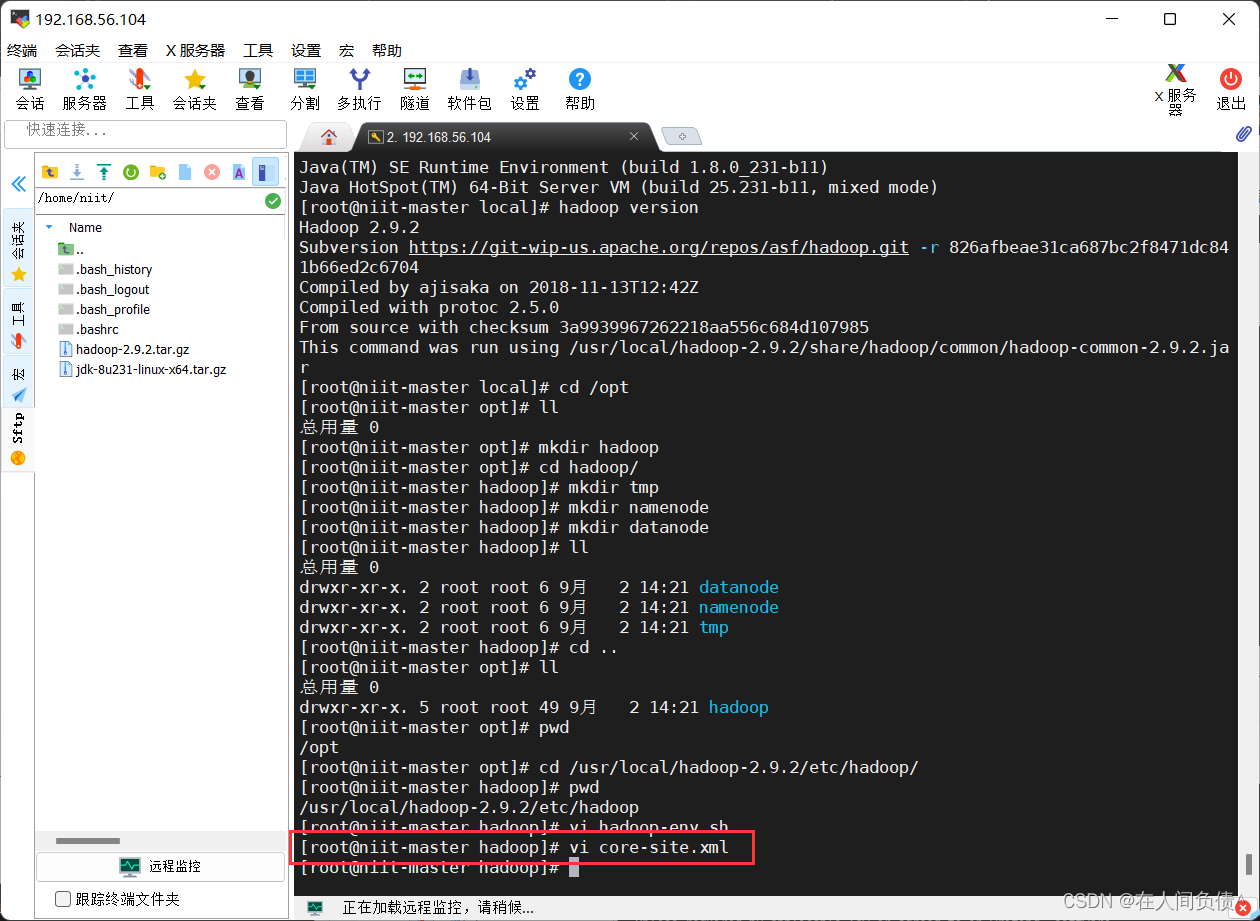
3. 创建相关文件
[root@niit-master hadoop]# cd /opt
[root@niit-master opt]# ll
总用量 0
[root@niit-master opt]# mkdir hadoop
[root@niit-master opt]# cd hadoop/
[root@niit-master hadoop]# mkdir tmp
[root@niit-master hadoop]# mkdir namenode
[root@niit-master hadoop]# mkdir datanode
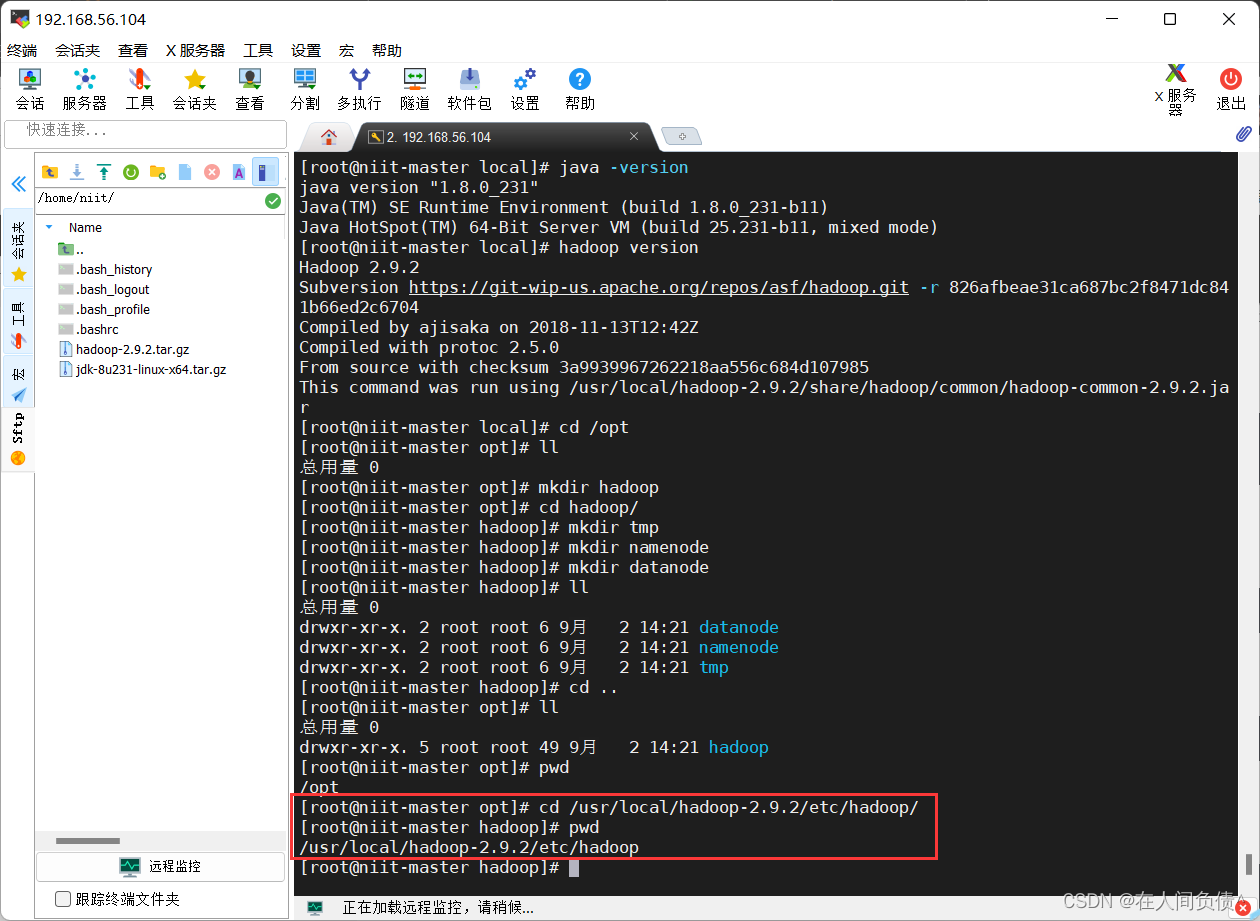
hadoop_121">4. hadoop配置
[root@niit-master hadoop]# pwd
/usr/local/hadoop-2.9.2/etc/hadoop
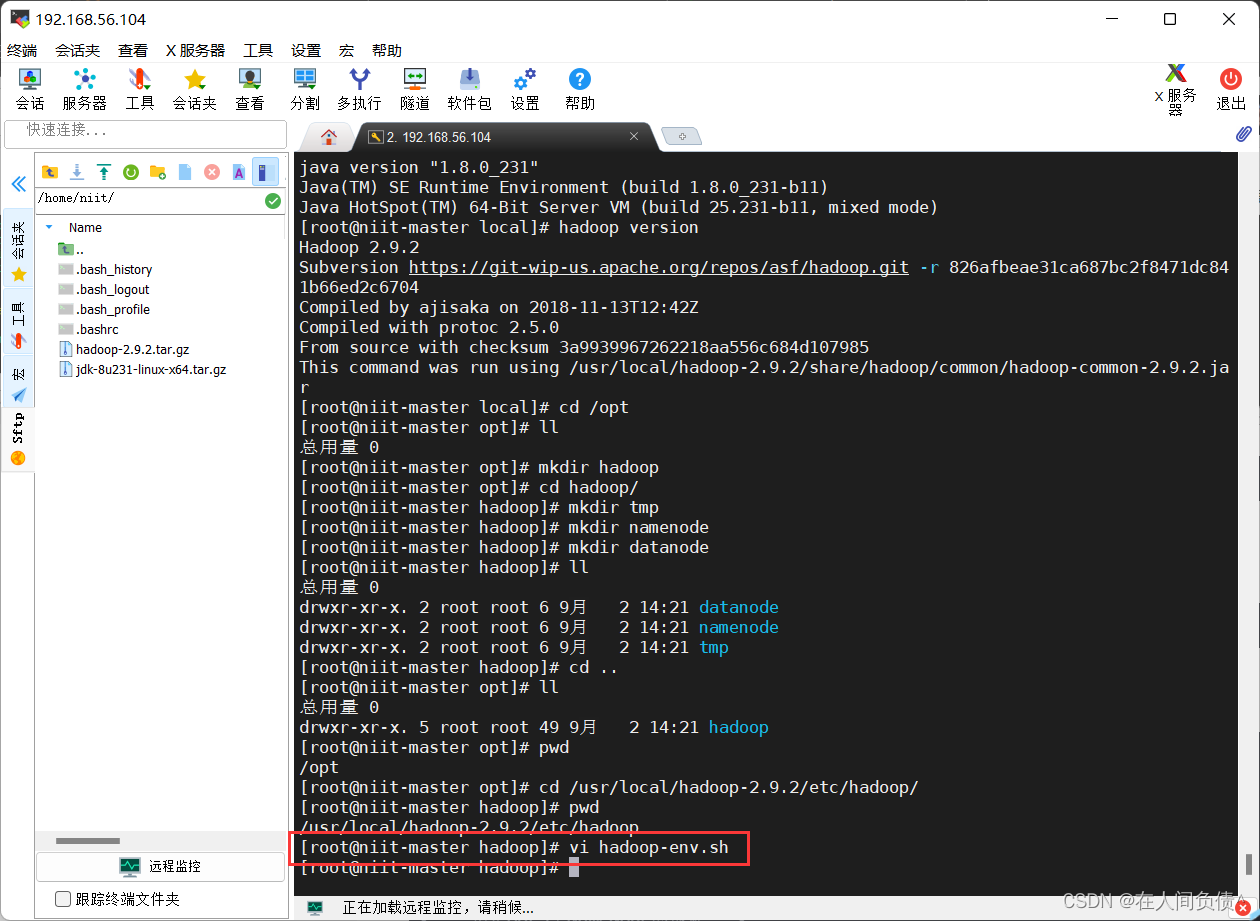
- 配置
hadoop-env.sh文件
[root@niit-master hadoop]# vi hadoop-env.sh
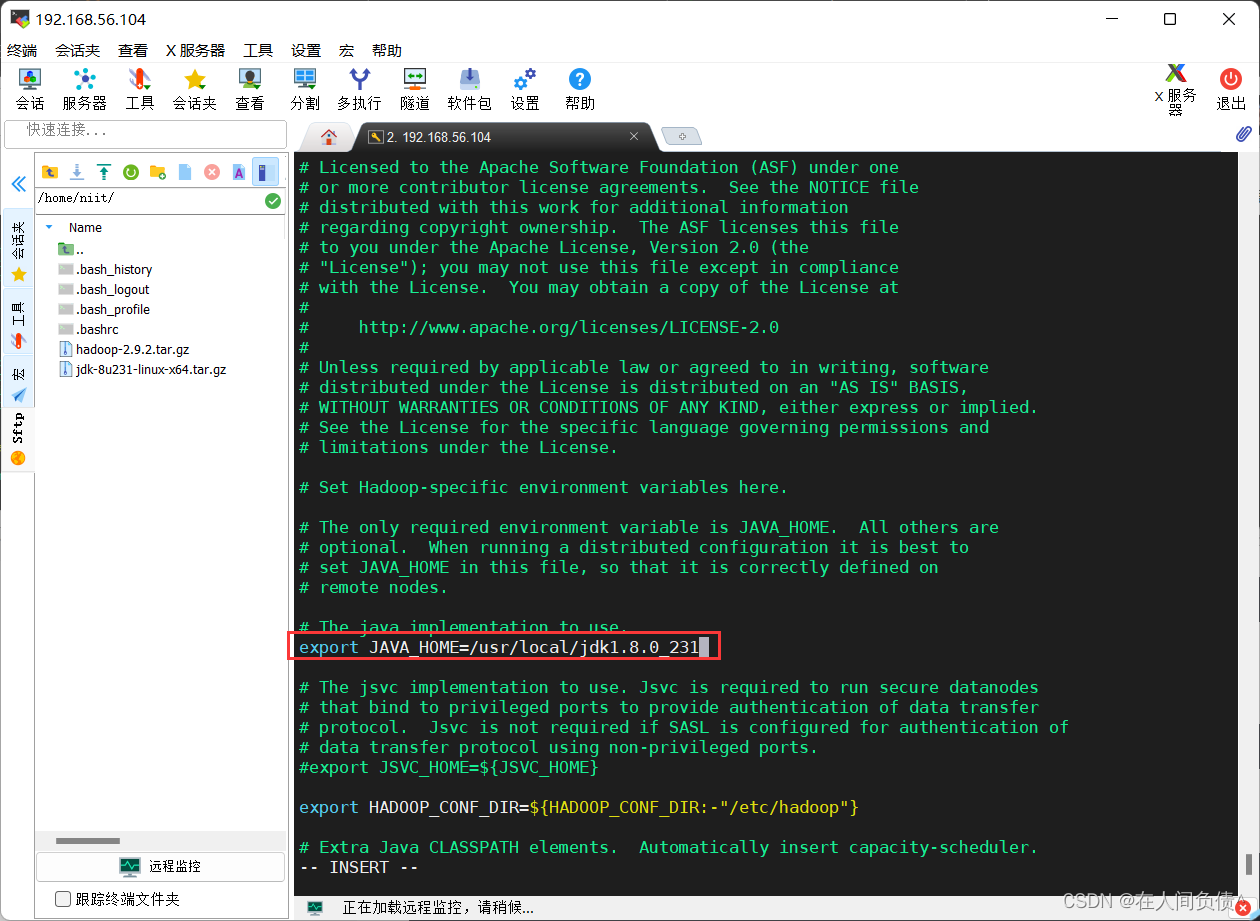
将 export JAVA_HOME={JAVA_HOME} 更改为
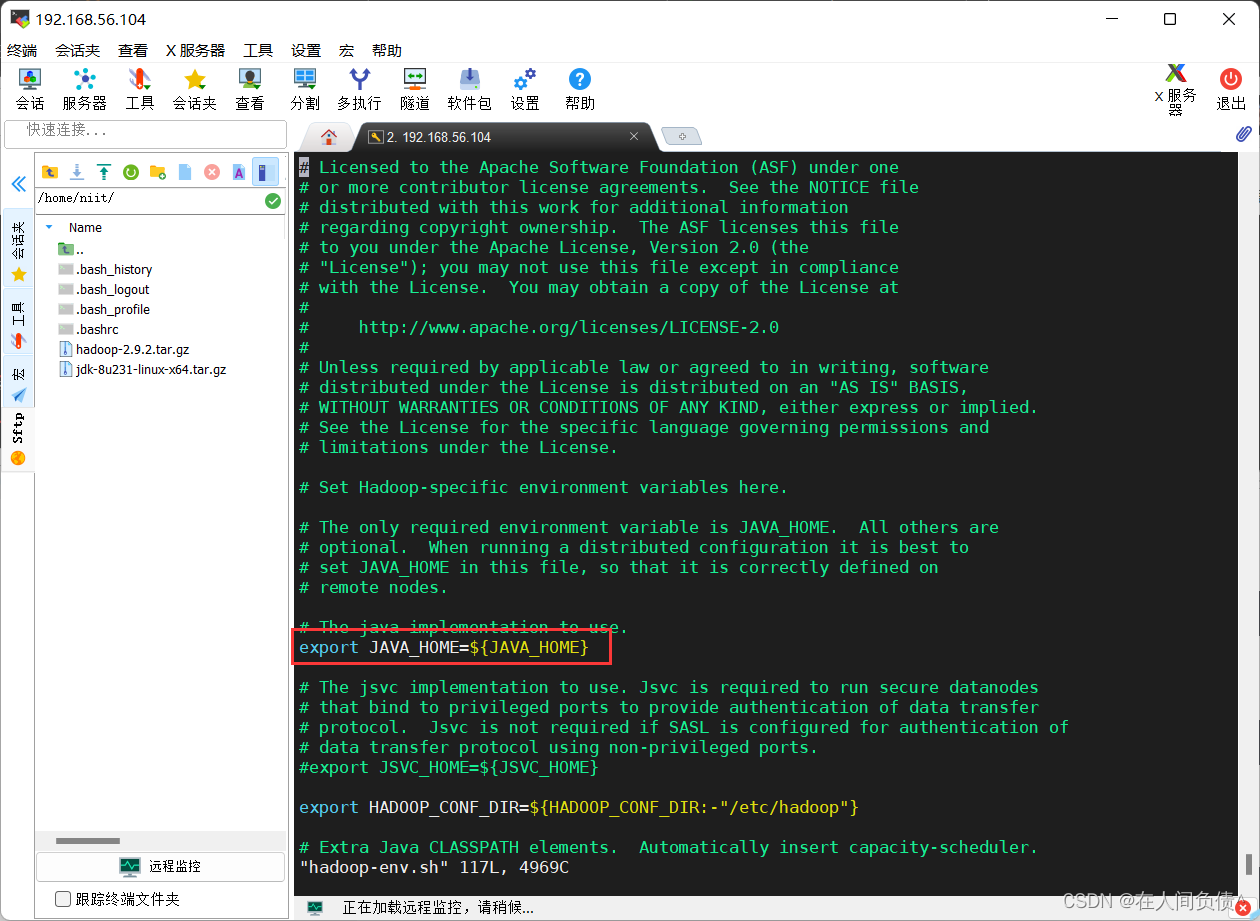
export JAVA_HOME=/usr/local/jdk1.8.0_231
- 配置
core-site.xml文件
[root@niit-master hadoop]# vi core-site.xml
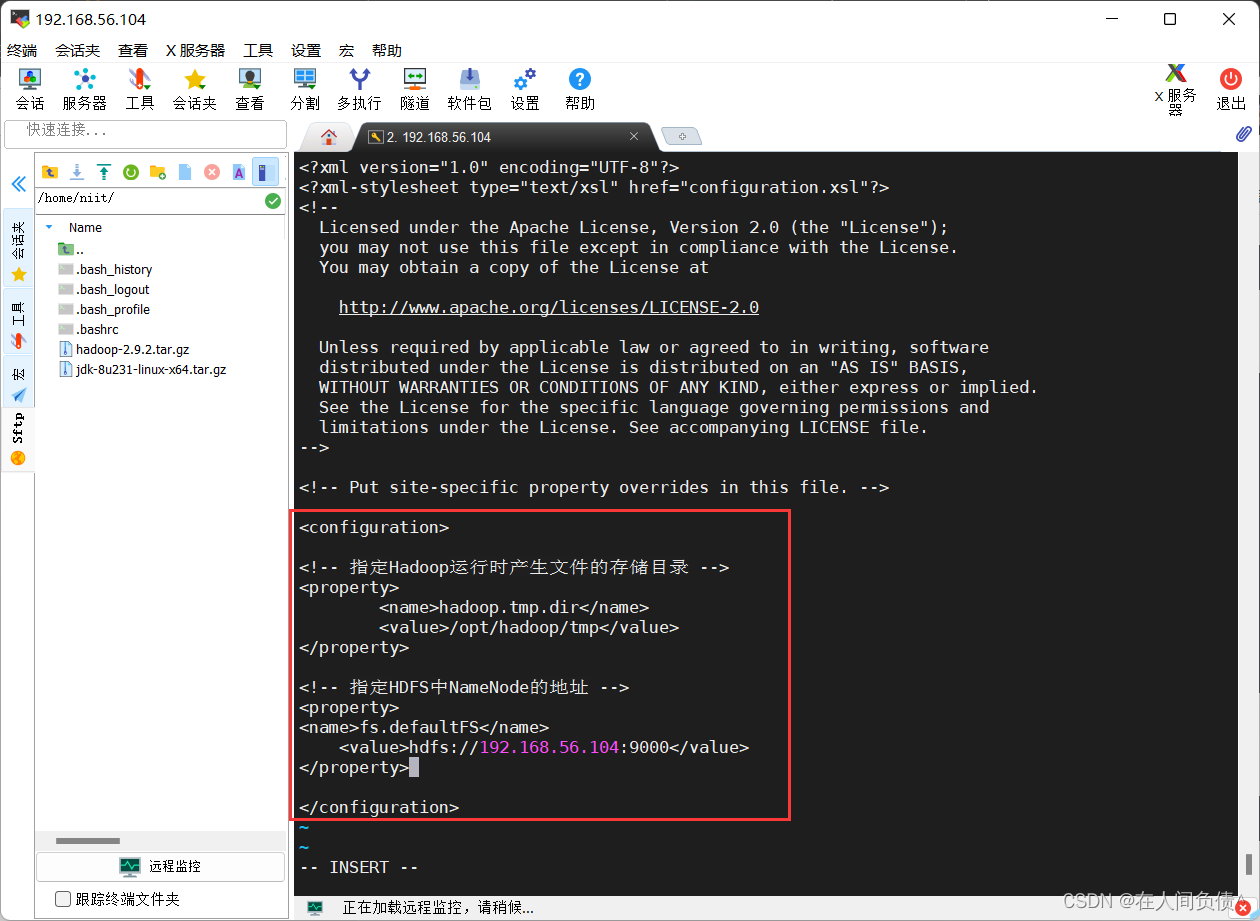
在 <configuration></configuration> 中间加入下面代码
<!-- 指定Hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop/tmp</value>
</property>
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.56.104:9000</value>
</property>
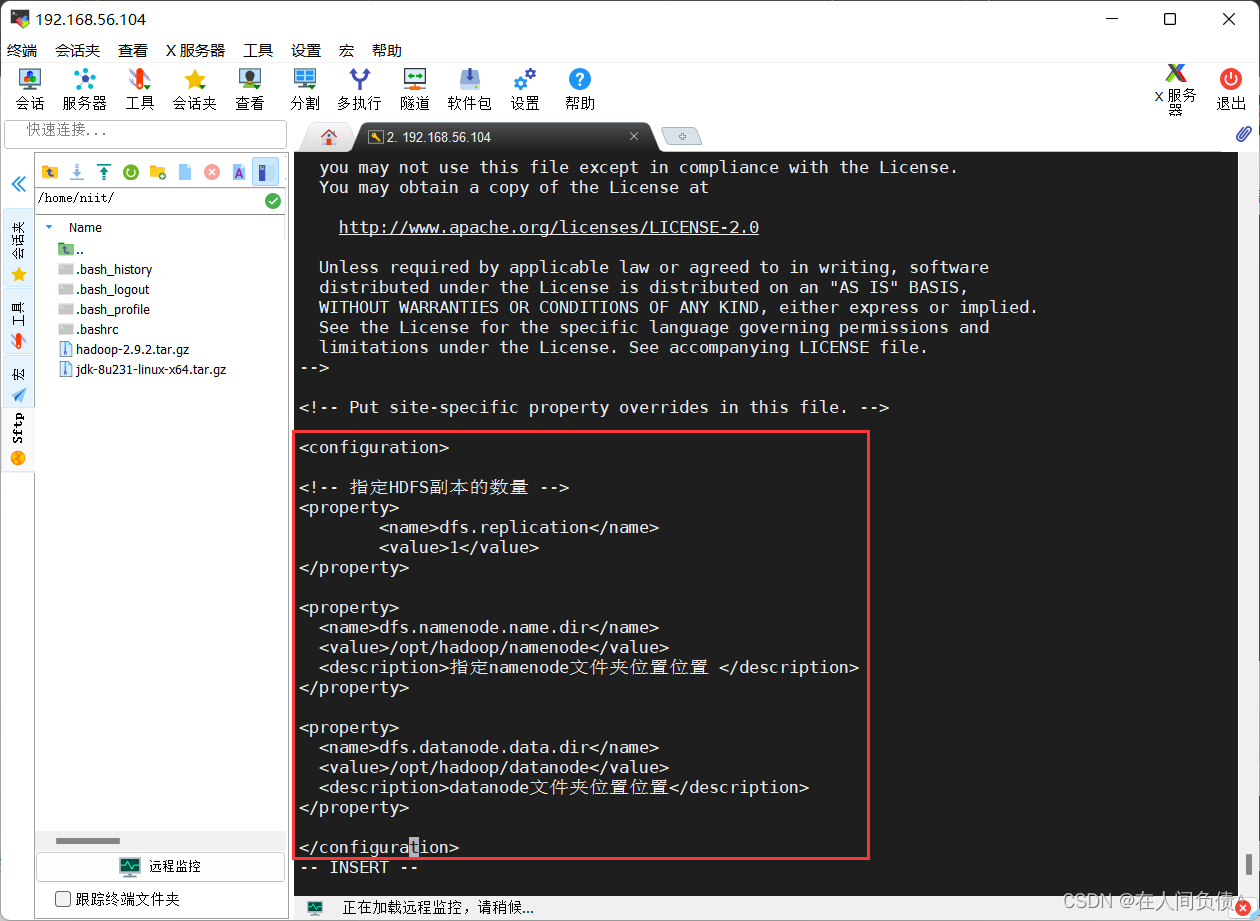
- 配置
hdfs-site.xml文件
[root@niit-master hadoop]# vi hdfs-site.xml

在 <configuration></configuration> 中间加入下面代码
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/hadoop/namenode</value>
<description>指定namenode文件夹位置位置 </description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/hadoop/datanode</value>
<description>datanode文件夹位置位置</description>
</property>
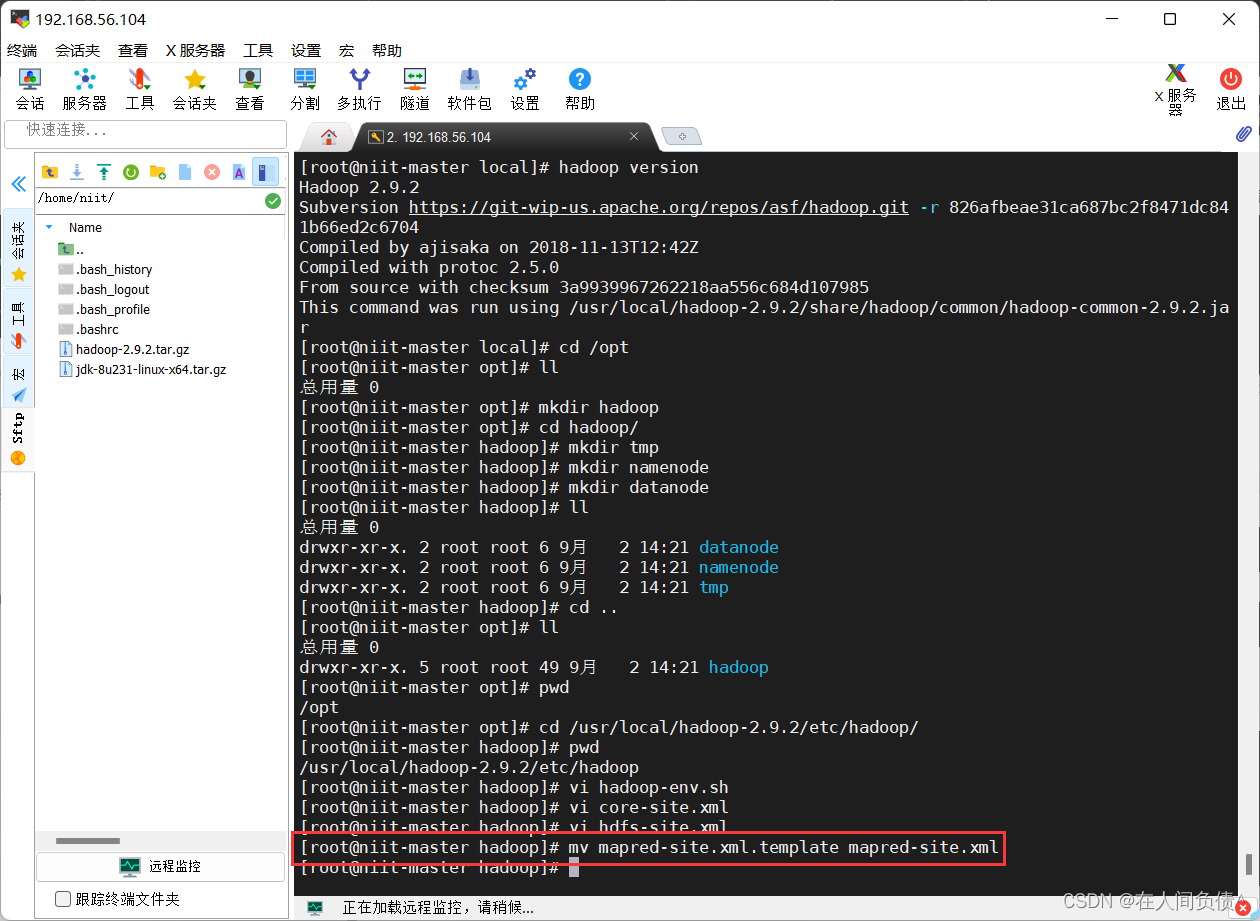
- 配置
mapred-site.xml文件
没有mapred-site.xml文件,需要mapred-site.xml.template重命名为mapred-site.xml
[root@niit-master hadoop]# mv mapred-site.xml.template mapred-site.xml
[root@niit-master hadoop]# vi mapred-site.xml
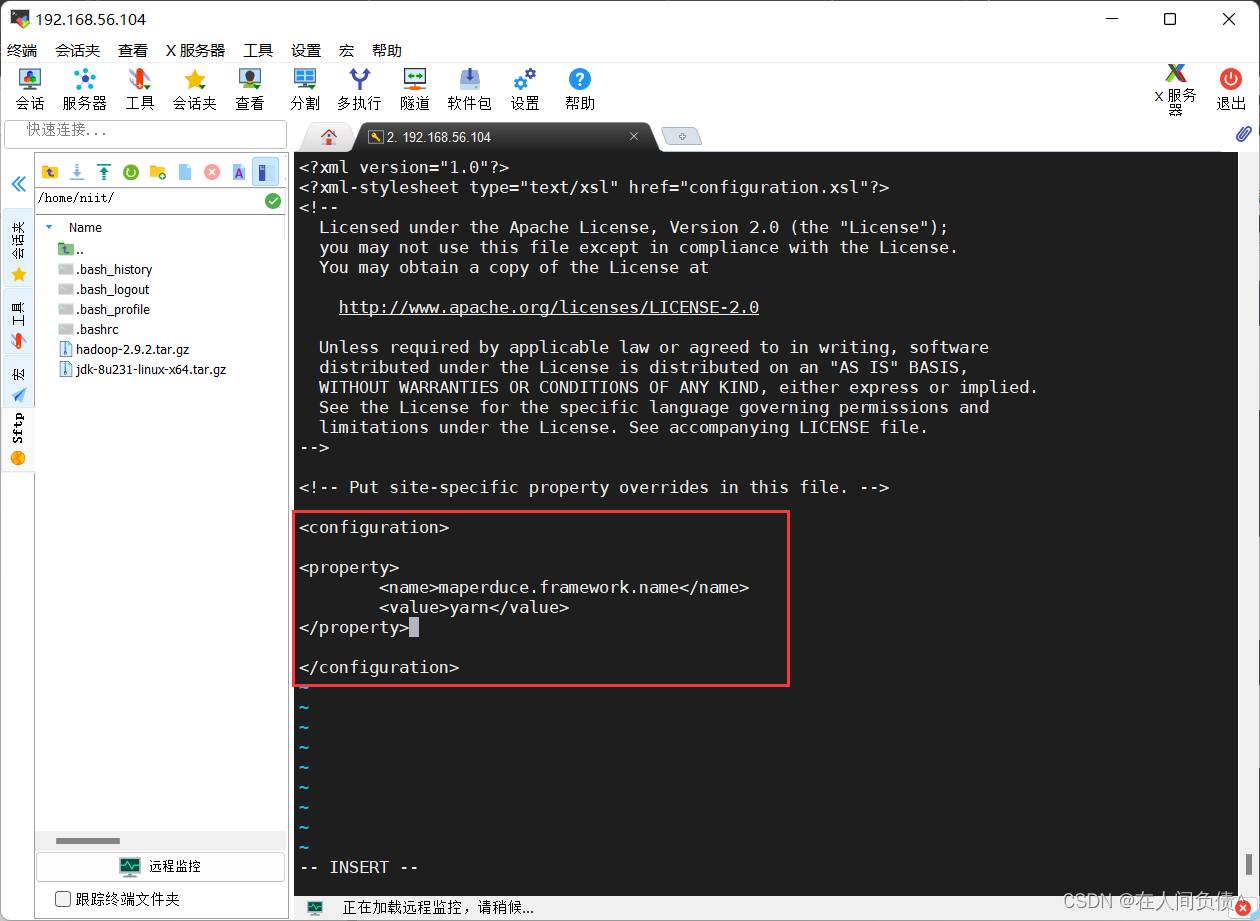
在 <configuration></configuration> 中间加入下面代码
<property>
<name>maperduce.framework.name</name>
<value>yarn</value>
</property>
- 配置
yarn-site.xml文件
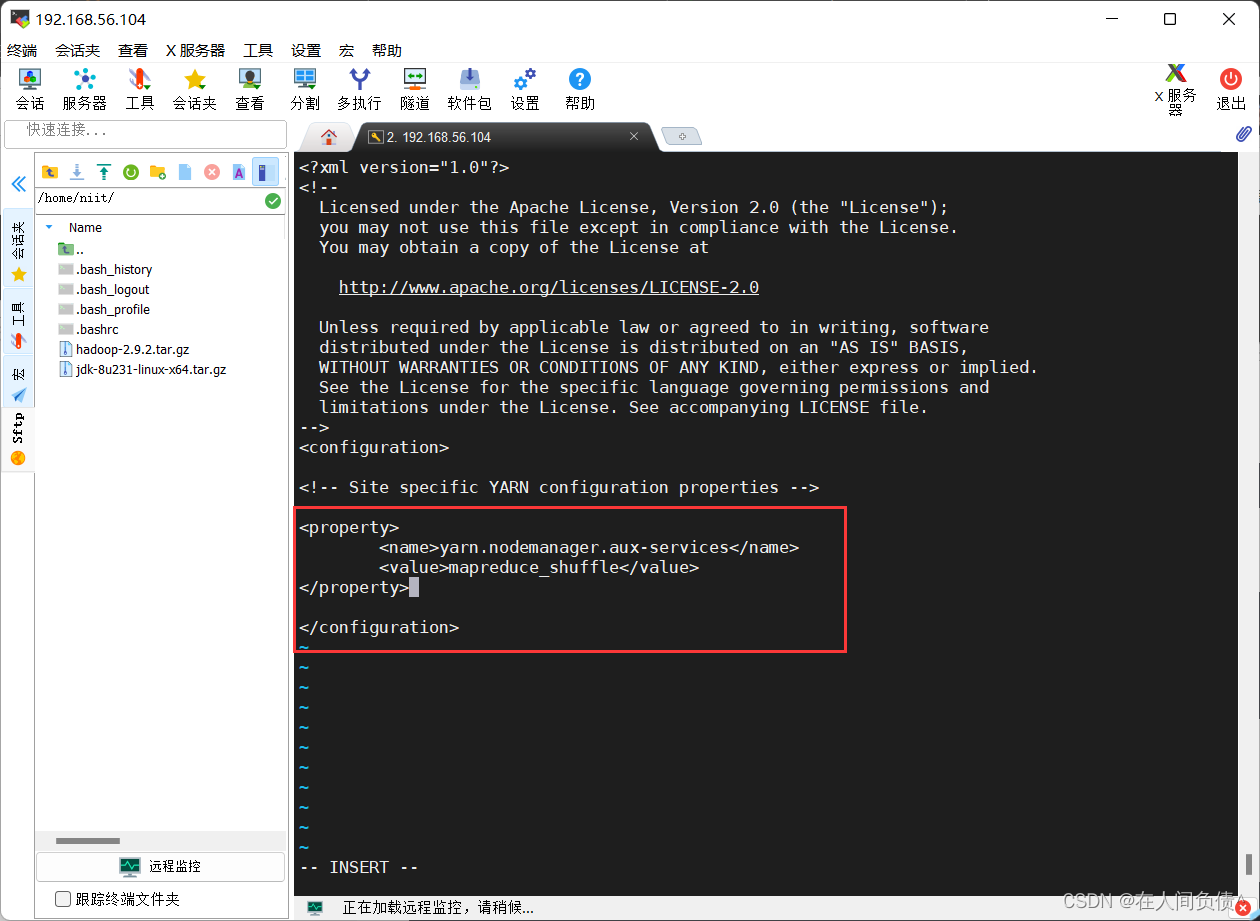
[root@niit-master hadoop]# vi yarn-site.xml
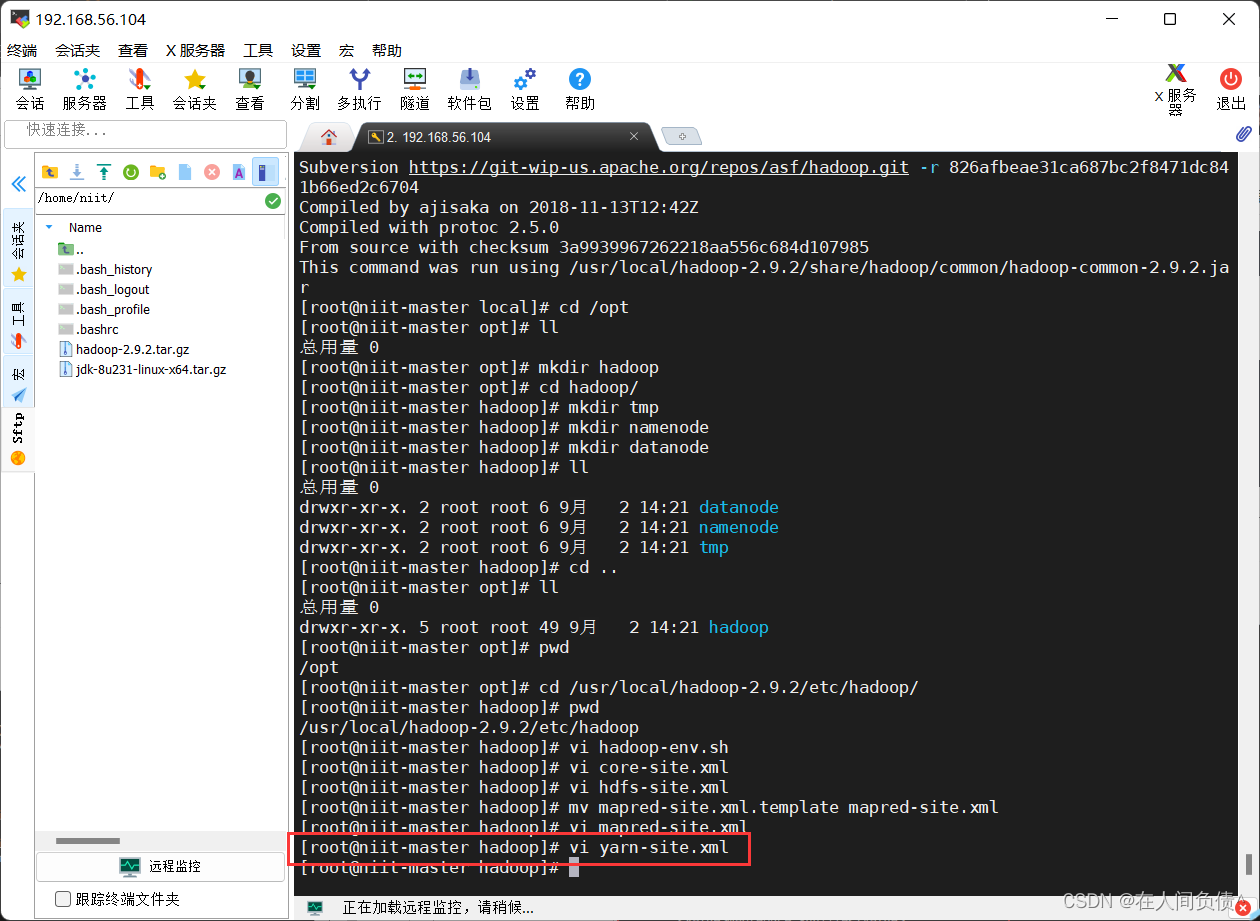
在 <configuration></configuration> 中间加入下面代码
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
hadoop_234">5. 启动hadoop
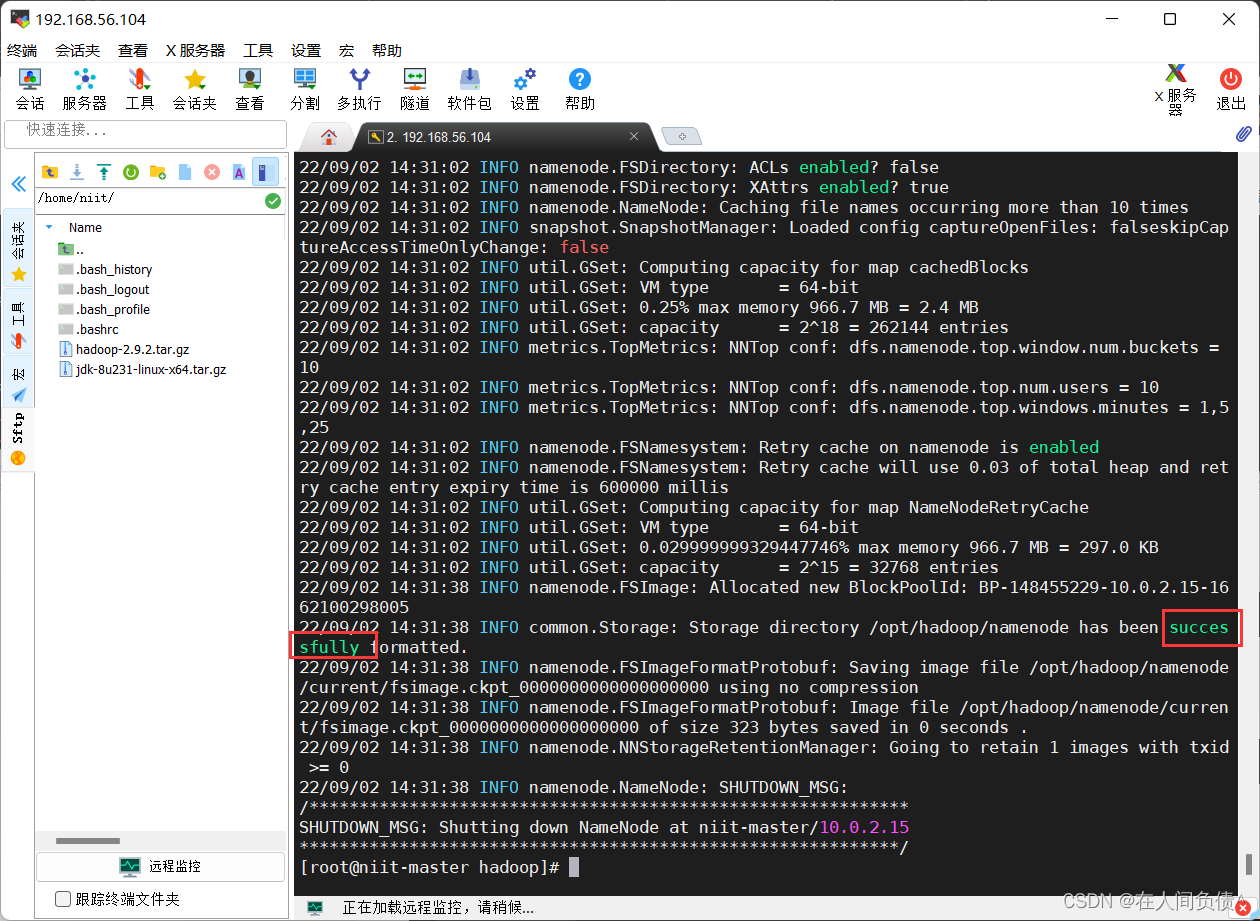
- 初始化 hadoop
[root@niit-master hadoop]# hdfs namenode -format
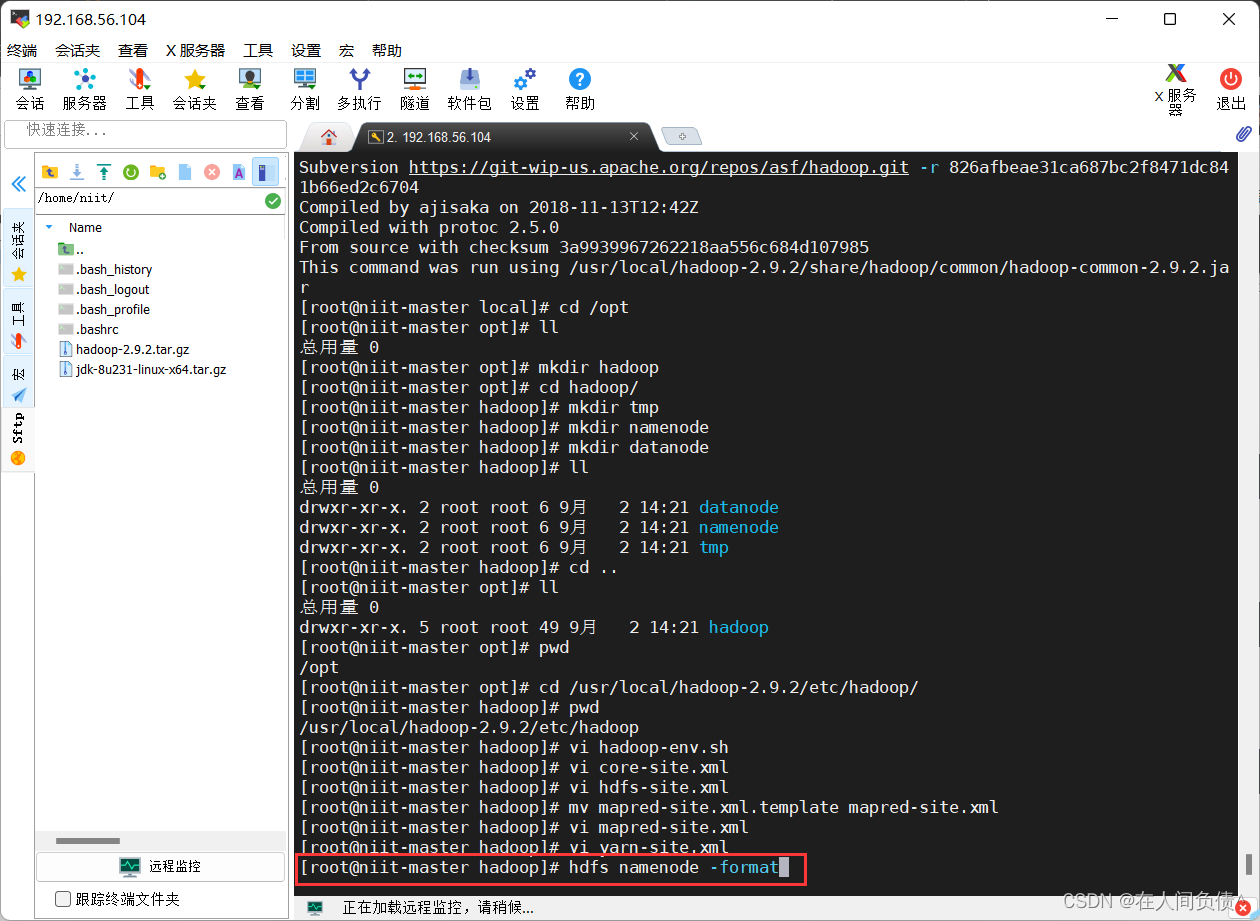
出现 successfully 说明初始化 hadoop 成功
- 查看进程
[root@niit-master hadoop]# jps
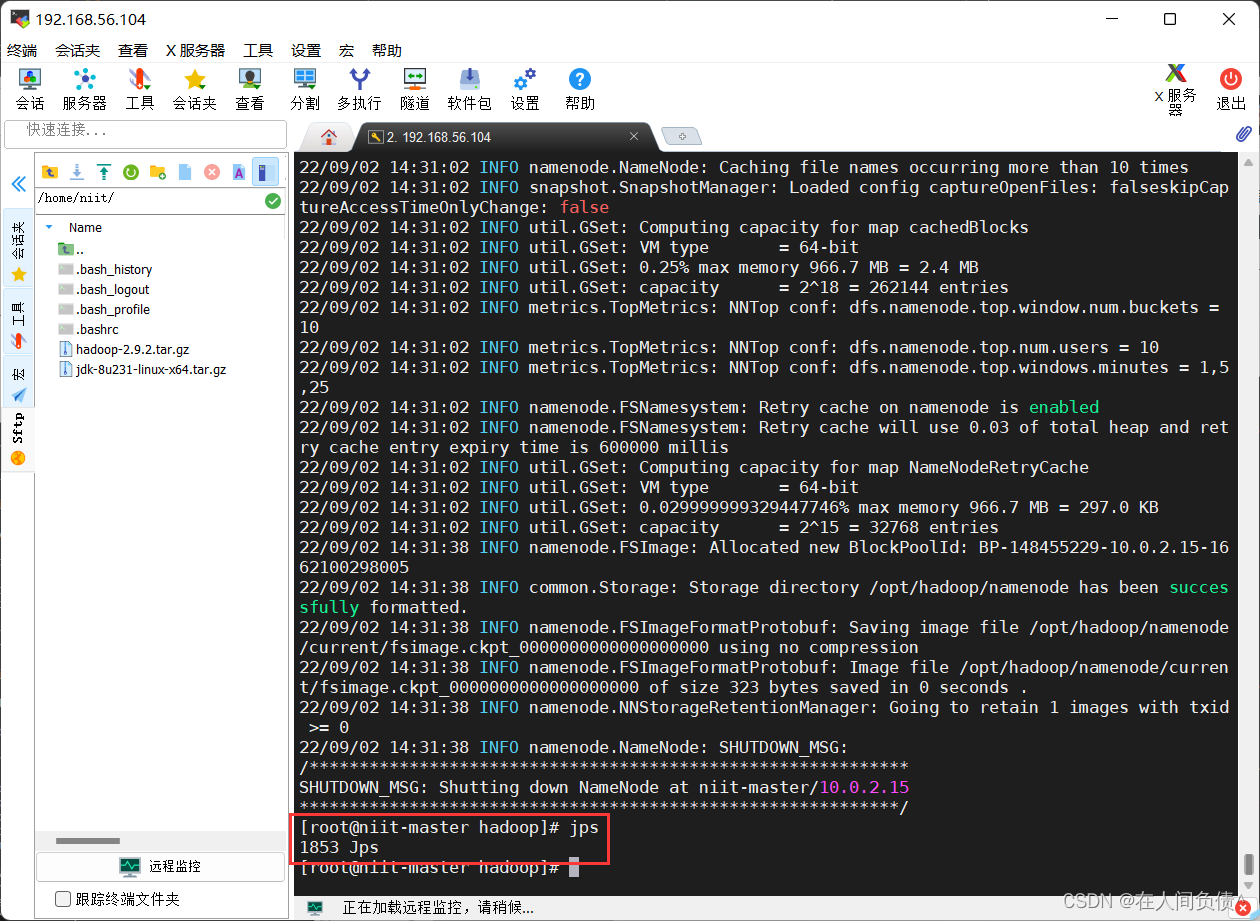
- 启动 hadoop
[root@niit-master hadoop]# start-all.sh
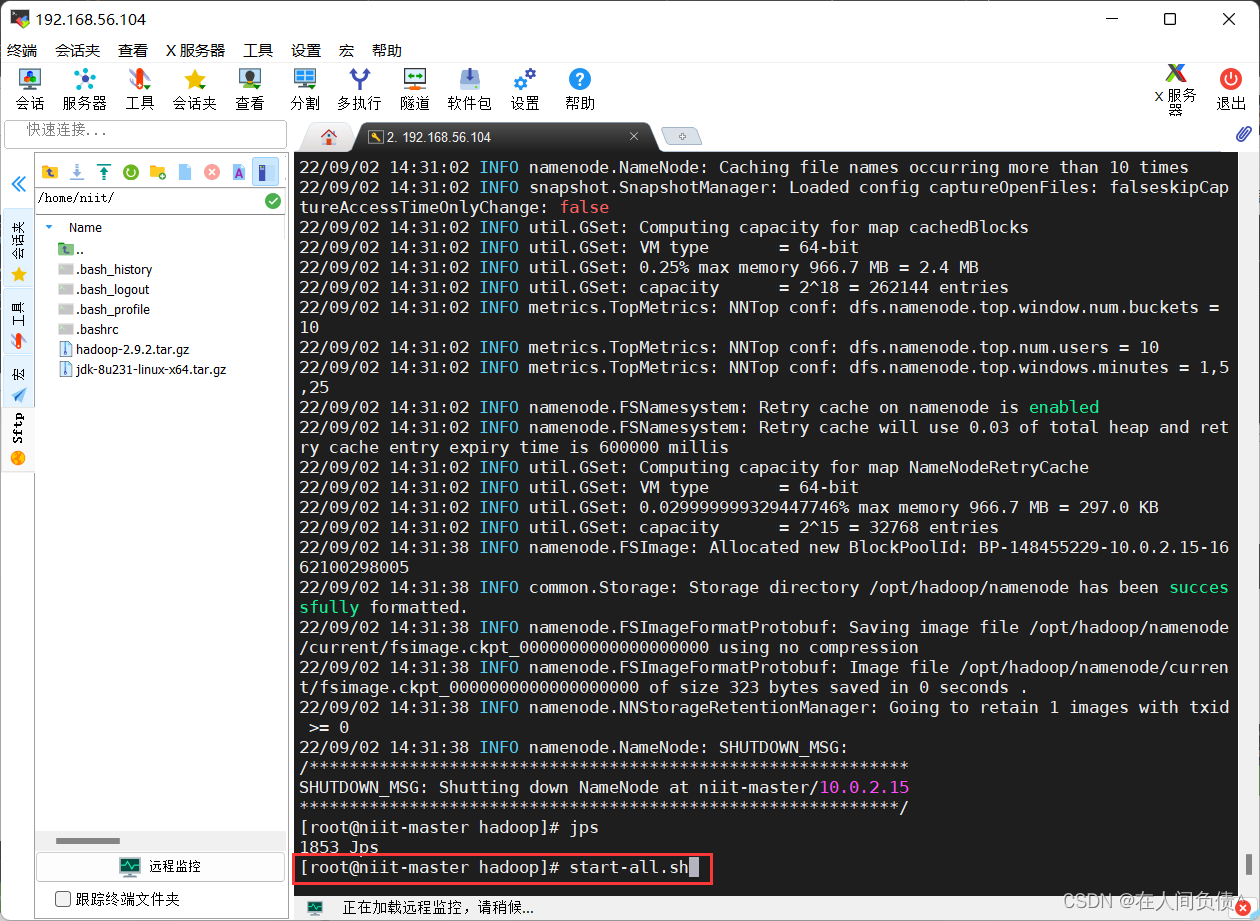
对于出现的询问,全部输入 yes 和密码即可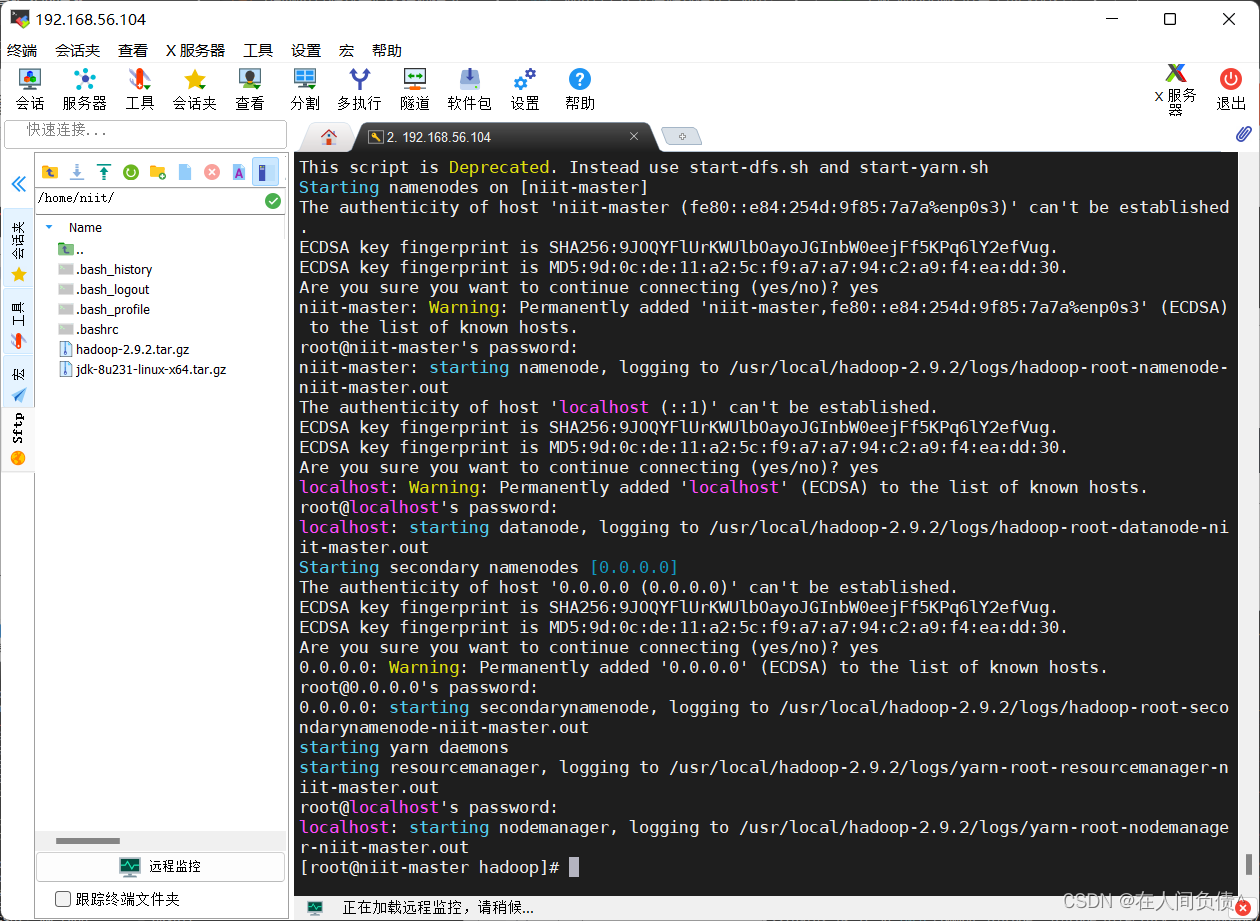
- 再次查看进程
[root@niit-master hadoop]# jps
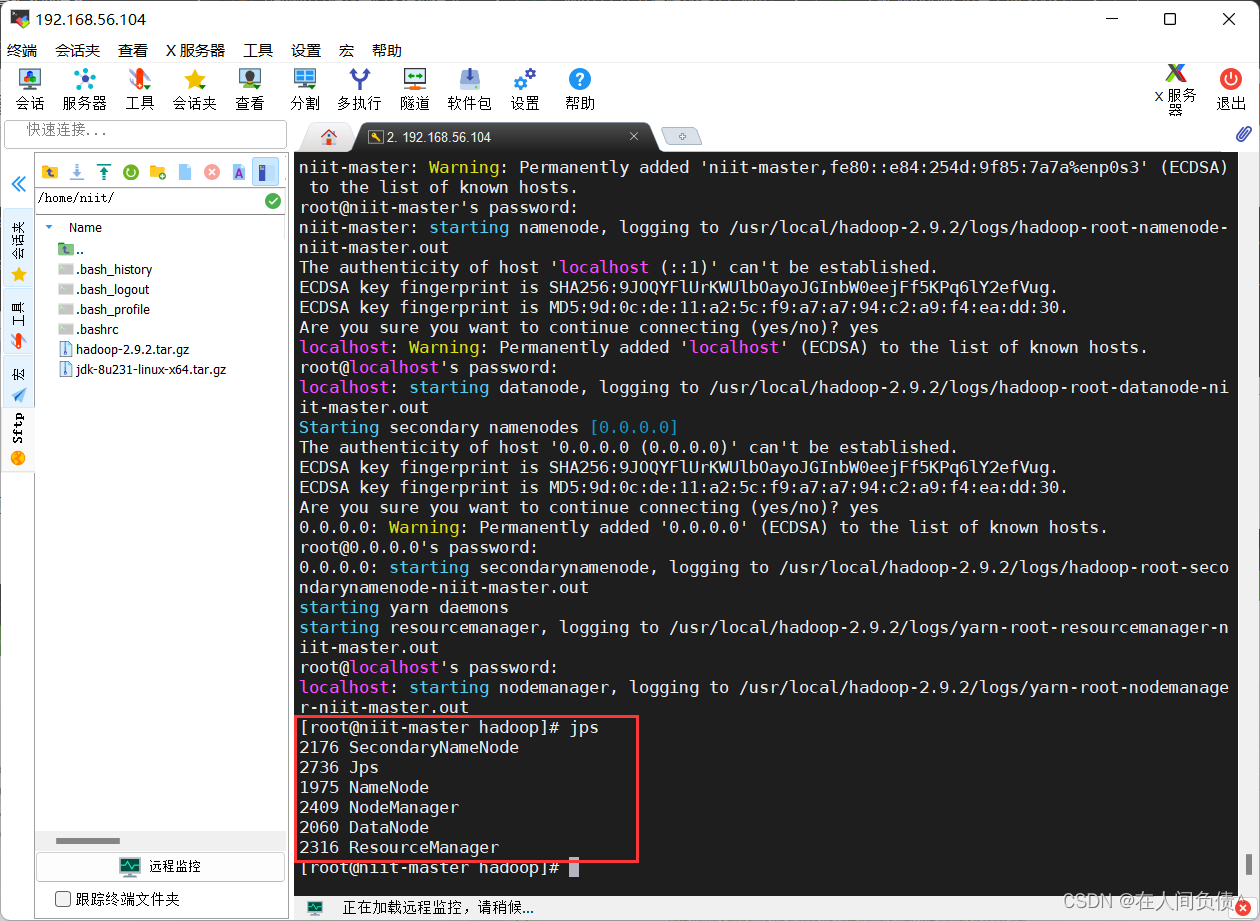
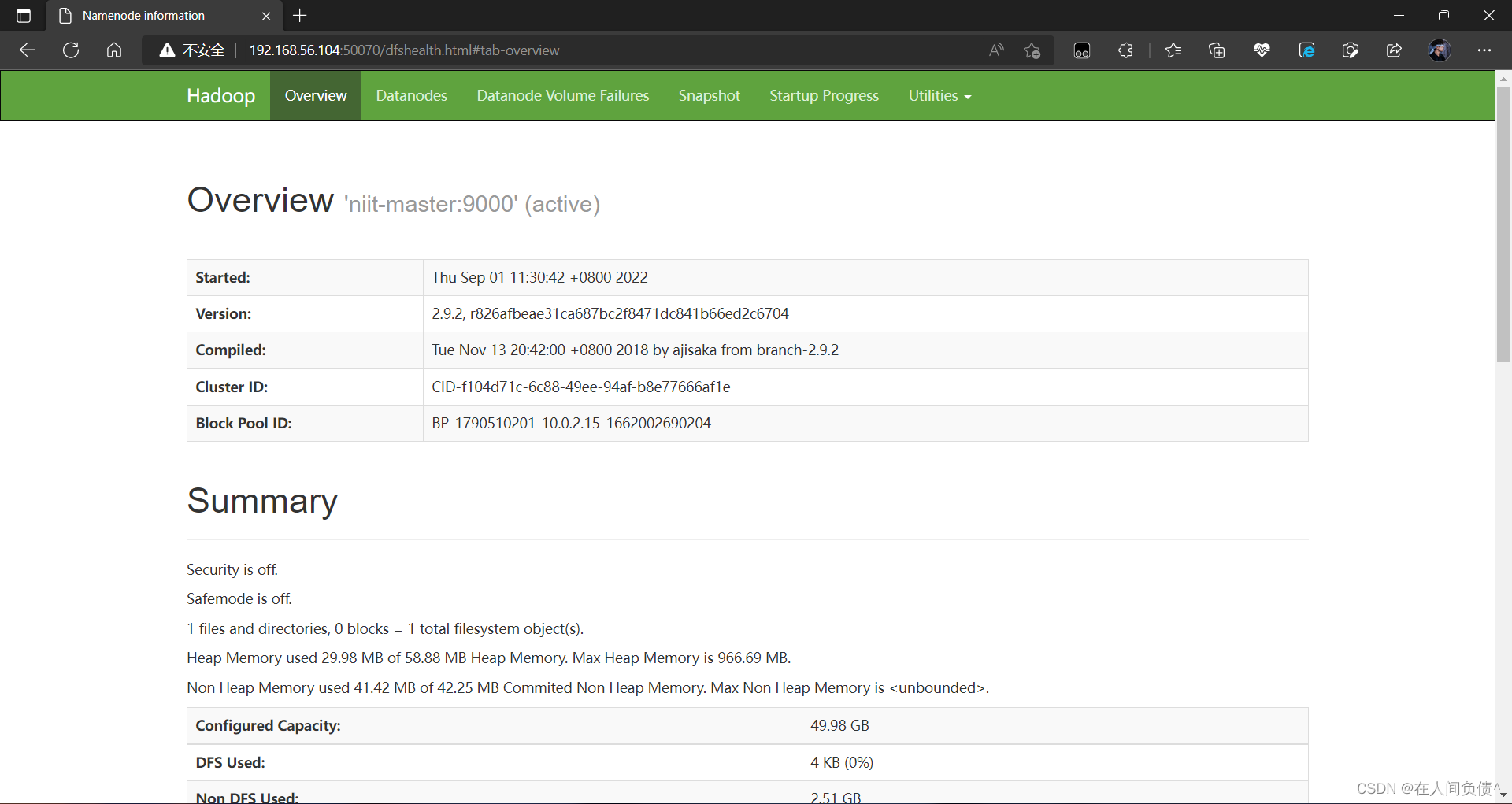
- 查看网址
在网页上输入:192.168.56.104:50070查看是否可以打开网页


![[OpenJudge]带有通配符的字符串匹配](https://www.oschina.net/img/hot3.png)