首先搭建eclipse的haoop2.7.1开发环境,使用的资源链接如下:
windows安装hadoop2.7.1环境
目录
一、MapReduce 模型简介
1.Map 和 Reduce 函数
2.MapReduce 体系结构
3.MapReduce 工作流程
4.MapReduce 应用程序执行过程
二、MapReduce 实战
1.数据去重
2.数据排序
3.平均成绩
4.单表关联
三、总结
一、MapReduce 模型简介
1.Map 和 Reduce 函数

2.MapReduce 体系结构

1)Client
用户编写的MapReduce程序通过Client提交到JobTracker端 用户可通过Client提供的一些接口查看作业运行状态
2)JobTracker
JobTracker负责资源监控和作业调度 JobTracker 监控所有TaskTracker与Job的健康状况,一旦发现失败,就将相应的任务转移到其他节点 JobTracker 会跟踪任务的执行进度、资源使用量等信息,并将这些信息告诉任务调度器(TaskScheduler),而调度器会在资源出现空闲时,选择合适的任务去使用这些资源
3)TaskTracker
TaskTracker 会周期性地通过“心跳”将本节点上资源的使用情况和任务的运行进度汇报给JobTracker,同时接收JobTracker 发送过来的命令并执行相应的操作(如启动新任务、杀死任务等) TaskTracker 使用“slot”等量划分本节点上的资源量(CPU、内存等)。一个Task 获取到一个slot 后才有机会运行,而Hadoop调度器的作用就是将各个TaskTracker上的空闲slot分配给Task使用。slot 分为Map slot 和Reduce slot 两种,分别供MapTask 和Reduce Task 使用
4)Task
Task 分为Map Task 和Reduce Task 两种,均由TaskTracker 启动
3.MapReduce 工作流程

- 不同的Map任务之间不会进行通信
- 不同的Reduce任务之间也不会发生任何信息交换
- 用户不能显式地从一台机器向另一台机器发送消息
- 所有的数据交换都是通过MapReduce框架自身去实现的
2) MapReduce各个执行阶段

4.MapReduce 应用程序执行过程

二、MapReduce 实战
1.数据去重
"数据去重"主要是为了掌握和利用并行化思想来对数据进行有意义的筛选。统计大数据集上的数据种类个数、从网站日志中计算访问地等这些看似庞杂的任务都会涉及数据去重。
1.1实例描述
对数据文件中的数据进行去重。数据文件中的每行都是一个数据。样例输入如下所示:
1)file1:
2012-3-1 a
2012-3-2 b
2012-3-3 c
2012-3-4 d
2012-3-5 a
2012-3-6 b
2012-3-7 c
2012-3-3 c
2)file2:
2012-3-1 b
2012-3-2 a
2012-3-3 b
2012-3-4 d
2012-3-5 a
2012-3-6 c
2012-3-7 d
2012-3-3 c
样例输出如下所示:
2012-3-1 a
2012-3-1 b
2012-3-2 a
2012-3-2 b
2012-3-3 b
2012-3-3 c
2012-3-4 d
2012-3-5 a
2012-3-6 b
2012-3-6 c
2012-3-7 c
1.2 解题思路
map阶段:将每一行的文本作为键值对的key

reduce阶段:将每一个公用的键组输出

1.3 代码展示

package datadeduplicate.pers.xls.datadeduplicate;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.log4j.BasicConfigurator;
public class Deduplication {
public static void main(String[] args) throws Exception {
BasicConfigurator.configure(); //自动快速地使用缺省Log4j环境
//必须要传递的是自定的mapper和reducer的类,输入输出的路径必须指定,输出的类型<k3,v3>必须指定
//1首先寫job,知道需要conf和jobname在去創建即可
Configuration conf=new Configuration();
String jobName=Deduplication.class.getSimpleName();
Job job = Job.getInstance(conf, jobName);
//2将自定义的MyMapper和MyReducer组装在一起
//3读取HDFS內容:FileInputFormat在mapreduce.lib包下
FileInputFormat.setInputPaths(job, new Path(args[0]));
//4指定解析<k1,v1>的类(谁来解析键值对)
//*指定解析的类可以省略不写,因为设置解析类默认的就是TextInputFormat.class
job.setInputFormatClass(TextInputFormat.class);
//5指定自定义mapper类
job.setMapperClass(MyMapper.class);
//6指定map输出的key2的类型和value2的类型 <k2,v2>
//*下面两步可以省略,当<k3,v3>和<k2,v2>类型一致的时候,<k2,v2>类型可以不指定
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
//7分区(默认1个),排序,分组,规约 采用 默认
job.setCombinerClass(MyReducer.class);
//接下来采用reduce步骤
//8指定自定义的reduce类
job.setReducerClass(MyReducer.class);
//9指定输出的<k3,v3>类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
//10指定输出<K3,V3>的类
//*下面这一步可以省
job.setOutputFormatClass(TextOutputFormat.class);
//11指定输出路径
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//12写的mapreduce程序要交给resource manager运行
job.waitForCompletion(true);
//*13最后,如果要打包运行改程序,则需要调用如下行
job.setJarByClass(Deduplication.class);
}
private static class MyMapper extends Mapper<Object, Text, Text, Text>{
private static Text line=new Text();
@Override
protected void map(Object k1, Text v1,Mapper<Object, Text, Text, Text>.Context context) throws IOException, InterruptedException {
line=v1;//v1为每行数据,赋值给line
context.write(line, new Text(""));
}
}
private static class MyReducer extends Reducer<Text, Text, Text, Text>
{
@Override
protected void reduce(Text k2, Iterable<Text> v2s,Reducer<Text, Text, Text, Text>.Context context) throws IOException, InterruptedException {
context.write(k2, new Text(""));
}
}
}1.4 运行结果展示
打包项目成可运行的jar包,上传的hdfs文件系统:

在linux系统下终端输入hadoop命令,在建立的hadoop节点上运行jar包:
![]()
查看eclipse中hdfs文件系统下out文件夹,发现生成了先前指定的deduplication文件夹,其中part-r-00000为运行的输出。

2.数据排序


package dararank.pers.xls.datarank;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import org.apache.log4j.BasicConfigurator;
import java.io.IOException;
public class DataRank {
/**
* 使用Mapper将数据文件中的数据本身作为Mapper输出的key直接输出
*/
public static class forSortedMapper extends Mapper<Object, Text, IntWritable, IntWritable> {
private IntWritable mapperValue = new IntWritable(); //存放key的值
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString(); //获取读取的值,转化为String
mapperValue.set(Integer.parseInt(line)); //将String转化为Int类型
context.write(mapperValue,new IntWritable(1)); //将每一条记录标记为(key,value) key--数字 value--出现的次数
//每出现一次就标记为(number,1)
}
}
/**
* 使用Reducer将输入的key本身作为key直接输出
*/
public static class forSortedReducer extends Reducer<IntWritable, IntWritable, IntWritable, IntWritable>{
private IntWritable postion = new IntWritable(1); //存放名次
@Override
protected void reduce(IntWritable key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
for (IntWritable item :values){ //同一个数字可能出多次,就要多次并列排序
context.write(postion,key); //写入名次和具体数字
System.out.println(postion + "\t"+ key);
postion = new IntWritable(postion.get()+1); //名次加1
}
}
}
public static void main(String[] args) throws Exception {
BasicConfigurator.configure(); //自动快速地使用缺省Log4j环境
Configuration conf = new Configuration(); //设置MapReduce的配置
String[] otherArgs = new GenericOptionsParser(conf,args).getRemainingArgs();
if(otherArgs.length < 2){
System.out.println("Usage: datarank <in> [<in>...] <out>");
System.exit(2);
}
//设置作业
//Job job = new Job(conf);
Job job = Job.getInstance(conf);
job.setJarByClass(DataRank.class);
job.setJobName("DataRank");
//设置处理map,reduce的类
job.setMapperClass(forSortedMapper.class);
job.setReducerClass(forSortedReducer.class);
//设置输入输出格式的处理
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(IntWritable.class);
//设定输入输出路径
for (int i = 0; i < otherArgs.length-1;++i){
FileInputFormat.addInputPath(job,new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length-1]));
System.exit(job.waitForCompletion(true)?0:1);
}
}
3.平均成绩

package averagescoreapp.pers.xls.averagescoreapp;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import org.apache.log4j.BasicConfigurator;
/**
* 求平均成绩
*
*/
public class AverageScoreApp {
public static class Map extends Mapper<Object, Text, Text, IntWritable>{
@Override
protected void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
//成绩的结构是:
// 张三 80
// 李四 82
// 王五 86
StringTokenizer tokenizer = new StringTokenizer(value.toString(), "\n");
while(tokenizer.hasMoreElements()) {
StringTokenizer lineTokenizer = new StringTokenizer(tokenizer.nextToken());
String name = lineTokenizer.nextToken(); //姓名
String score = lineTokenizer.nextToken();//成绩
context.write(new Text(name), new IntWritable(Integer.parseInt(score)));
}
}
}
public static class Reduce extends Reducer<Text, IntWritable, Text, DoubleWritable>{
@Override
protected void reduce(Text key, Iterable<IntWritable> values,Reducer<Text, IntWritable, Text, DoubleWritable>.Context context)
throws IOException, InterruptedException {
//reduce这里输入的数据结构是:
// 张三 <80,85,90>
// 李四 <82,88,94>
// 王五 <86,80,92>
int sum = 0;//所有课程成绩总分
double average = 0;//平均成绩
int courseNum = 0; //课程数目
for(IntWritable score:values) {
sum += score.get();
courseNum++;
}
average = sum/courseNum;
context.write(new Text(key), new DoubleWritable(average));
}
}
public static void main(String[] args) throws Exception{
BasicConfigurator.configure(); //自动快速地使用缺省Log4j环境
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf,args).getRemainingArgs();
if(otherArgs.length < 2){
System.out.println("Usage: AverageScoreRank <in> [<in>...] <out>");
System.exit(2);
}
Job job = Job.getInstance(conf);
job.setJarByClass(AverageScoreApp.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(DoubleWritable.class);
//设定输入输出路径
for (int i = 0; i < otherArgs.length-1;++i){
FileInputFormat.addInputPath(job,new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length-1]));
System.exit(job.waitForCompletion(true)?0:1);
}
}![]()

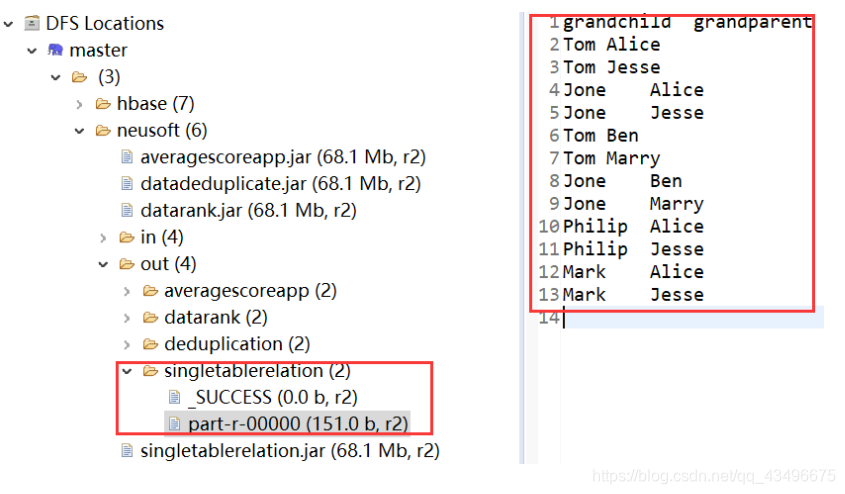
4.单表关联

package singletabblerelation.pers.xls.singletablerelation;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import org.apache.log4j.BasicConfigurator;
public class SingleTableRelation {
public static int time = 0;
public static class Map extends Mapper<LongWritable, Text, Text, Text> {
protected void map(LongWritable key, Text value, Context context)throws java.io.IOException, InterruptedException {
// 左右表的标识
int relation;
StringTokenizer tokenizer = new StringTokenizer(value.toString());
String child = tokenizer.nextToken();
String parent = tokenizer.nextToken();
if (child.compareTo("child") != 0) {
// 左表
relation = 1;
context.write(new Text(parent), new Text(relation + "+" + child));
// 右表
relation = 2;
context.write(new Text(child), new Text(relation + "+" + parent));
}
};
}
public static class Reduce extends Reducer<Text, Text, Text, Text> {
protected void reduce(Text key, Iterable<Text> values,
Reducer<Text, Text, Text, Text>.Context output)
throws java.io.IOException, InterruptedException {
int grandchildnum = 0;
int grandparentnum = 0;
List<String> grandchilds = new ArrayList<>();
List<String> grandparents = new ArrayList<>();
/** 输出表头 */
if (time == 0) {
output.write(new Text("grandchild"), new Text("grandparent"));
time++;
}
for (Text val : values) {
String record = val.toString();
char relation = record.charAt(0);
// 取出此时key所对应的child
if (relation == '1') {
String child = record.substring(2);
grandchilds.add(child);
grandchildnum++;
}
// 取出此时key所对应的parent
else {
String parent = record.substring(2);
grandparents.add(parent);
grandparentnum++;
}
}
if (grandchildnum != 0 && grandparentnum != 0) {
for (int i = 0; i < grandchildnum; i++)
for (int j = 0; j < grandparentnum; j++)
output.write(new Text(grandchilds.get(i)), new Text(
grandparents.get(j)));
}
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
BasicConfigurator.configure(); //自动快速地使用缺省Log4j环境
//必须要传递的是自定的mapper和reducer的类,输入输出的路径必须指定,输出的类型<k3,v3>必须指定
//2将自定义的MyMapper和MyReducer组装在一起
Configuration conf=new Configuration();
String[] otherArgs = new GenericOptionsParser(conf,args).getRemainingArgs();
if(otherArgs.length < 2){
System.out.println("Usage: SingleTableRelation <in> [<in>...] <out>");
System.exit(2);
}
String jobName=SingleTableRelation.class.getSimpleName();
//1首先寫job,知道需要conf和jobname在去創建即可
Job job = Job.getInstance(conf, jobName);
job.setJarByClass(SingleTableRelation.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
//设定输入输出路径
for (int i = 0; i < otherArgs.length-1;++i){
FileInputFormat.addInputPath(job,new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length-1]));
System.exit((job.waitForCompletion(true) ? 0 : 1));
}
}