本文目录如下:
- 1.Hadoop运行环境搭建
- 1.1 虚拟机环境准备
- 1.2 安装JDK
- 1.2.1 卸载现有JDK
- 1.2.2 在Linux系统下的opt目录中查看软件包是否导入成功
- 1.2.3 解压JDK到/opt/module目录下
- 1.2.4 配置JDK环境变量
- 1.2.5 测试JDK是否安装成功
- 1.3 安装Hadoop
- 1.3.1 进入到Hadoop安装包路径下
- 1.3.2 解压安装文件到/opt/module下面
- 1.3.3 查看是否解压成功
- 1.3.4 将Hadoop添加到环境变量
- 1.3.5 测试是否安装成功
- 1.3.6 重启(如果Hadoop命令不能用再重启)
- 1.4 Hadoop目录结构
- 1.4.1 查看Hadoop目录结构
- 1.4.2 重要目录
- 1.5 Windows安装Hadoop(并配置IDEA开发环境)
1.Hadoop运行环境搭建
首先需要使用VMware或其他工具先安装一个Linux虚拟机,并运行它。
1.1 虚拟机环境准备
- (1) 首先为崭新的Linux虚拟机创建一个快照,可以命名为"
clean"。并使用此快照克隆一台虚拟机(链接克隆),命名为"hadoop100",打开该虚拟机。
注:每克隆一台虚拟机,都需要为其修改
静态IP(2)、主机名(3)和网卡脚本文件(4)。
- (2) 修改虚拟机的静态IP
[root@hadoop100 opt]$ vim /etc/sysconfig/network-scripts/ifcfg-eth0
# 大致修改为如下样式
DEVICE=eth0
TYPE=Ethernet
ONBOOT=yes
BOOTPROTO=static # 设置为静态IP
NM_CONTROLLED=no
IPADDR=192.168.91.100
NETMASK=255.255.255.0
GATEWAY=192.168.91.2
DNS1=192.168.91.2
NAME=eth0
# 修改之后可以使用 ifconfig 查看是否配置成功
[root@hadoop100 opt]$ ifconfig
详细步骤请见:原文地址
设置静态IP和主机名也可以参考(第2条):原文地址
- (3) 修改主机名
[root@hadoop100 opt]$ vim /etc/sysconfig/network
# 修改为如下样式
HOSTNAME=hadoop100
- (4) 修改网卡脚本文件
注意:克隆的虚拟机需要修改网卡文件。新虚拟机不需要修改。
[root@hadoop100 opt]$ vim /etc/udev/rules.d/70-persistent-net.rules
打开之后按照如下提示进行操作即可:

- (5) 修改hosts文件
[root@hadoop100 opt]$ vim /etc/hosts
#在后面添加如下内容
192.168.91.100 hadoop100
192.168.91.101 hadoop101
192.168.91.102 hadoop102
# 如有需求可添加更多
- (6) 关闭防火墙
[root@hadoop100 opt]$ service iptables stop
# 永久关闭防火墙
[root@hadoop100 opt]$ chkconfig iptables off
# 关闭后记得重启系统
[root@hadoop100 opt]$ reboot
Centos6关闭防火墙
Centos7关闭防火墙
Bug:在这一步之后,应该可以使用XShell软件连接虚拟机进行操作了。在网络连接模式为"桥接模式"时,怎么都连接不上,ping也ping不通,最后将网络连接模式改为"NET连接"之后,XShell成功连接上虚拟机。
- (7) 创建xqzhao用户
[root@hadoop100 opt]$ useradd xqzhao
[root@hadoop100 opt]$ passwd xqzhao
- (8) 配置xqzhao用户具有root权限
[root@hadoop100 opt] vim /etc/sudoers
详细步骤请见:Linux操作笔记(第4条)
- (9) 在/opt目录下创建module、software文件夹
[xqzhao@hadoop100 opt]$ sudo mkdir module
[xqzhao@hadoop100 opt]$ sudo mkdir software
# 注:module文件夹用于安装软件
# software文件夹用于存放软件安装包
- (10) 修改module、software文件夹的所有者cd
[xqzhao@hadoop100 opt]$ sudo chown xqzhao:xqzhao module/ software/
[xqzhao@hadoop100 opt]$ ll
总用量 8
drwxr-xr-x. 2 xqzhao xqzhao 4096 1月 17 14:37 module
drwxr-xr-x. 2 xqzhao xqzhao 4096 1月 17 14:38 software
-
(11) 修改 windows 的主机映射文件(
hosts 文件)
略… -
(12) 注意:至此,虚拟机的基础设置应该就差不多了。我们可以再为虚拟机创建一个快照(虚拟机关机状态下),建议命名为
After Configuration,后面再克隆虚拟机,将使用这个快照去克隆(链接克隆)。克隆之后的虚拟机只需要修改静态IP(2)、主机名(3)和网卡脚本文件(4)。
1.2 安装JDK
1.2.1 卸载现有JDK
- (1) 查询是否安装Java软件:
[xqzhao@hadoop100 opt]$ rpm -qa | grep java
- (2) 如果安装的版本低于1.7,卸载该JDK:
[xqzhao@hadoop100 opt]$ rpm -qa | grep java | xargs sudo rpm -e --nodeps
- (3) 查看JDK安装路径:
[xqzhao@hadoop100 ~]$ which java
1.2.2 在Linux系统下的opt目录中查看软件包是否导入成功
[xqzhao@hadoop100 opt]$ cd software/
[xqzhao@hadoop100 software]$ ls
hadoop-3.2.1.tar.gz jdk-8u144-linux-x64.tar.gz
1.2.3 解压JDK到/opt/module目录下
[xqzhao@hadoop100 software]$ tar -zxvf jdk-8u144-linux-x64.tar.gz -C /opt/module/
1.2.4 配置JDK环境变量
- (1) 先获取JDK路径
[xqzhao@hadoop100 jdk1.8.0_144]$ pwd
/opt/module/jdk1.8.0_144
- (2) 打开/etc/profile文件
[xqzhao@hadoop100 software]$ sudo vim /etc/profile
注:在profile文件末尾添加JDK路径
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_144
export PATH=$PATH:$JAVA_HOME/bin
- (3) 让修改后的文件生效
[xqzhao@hadoop100 jdk1.8.0_144]$ source /etc/profile
1.2.5 测试JDK是否安装成功
[xqzhao@hadoop100 jdk1.8.0_144]$ java -version
java version "1.8.0_144"
注意:重启(如果java -version可以用就不用重启)
[xqzhao@hadoop100 jdk1.8.0_144]$ sync # 数据同步,不知道有什么用哈哈
[xqzhao@hadoop100 jdk1.8.0_144]$ sudo reboot
1.3 安装Hadoop
1.3.1 进入到Hadoop安装包路径下
[xqzhao@hadoop100 ~]$ cd /opt/software/
1.3.2 解压安装文件到/opt/module下面
[xqzhao@hadoop100 software]$ tar -zxvf hadoop-3.2.1.tar.gz -C /opt/module/
注:Hadoop下载地址:
- (1) 官方网址:官方网址下载
- (2) 参考网址:Hadoop全版本下载
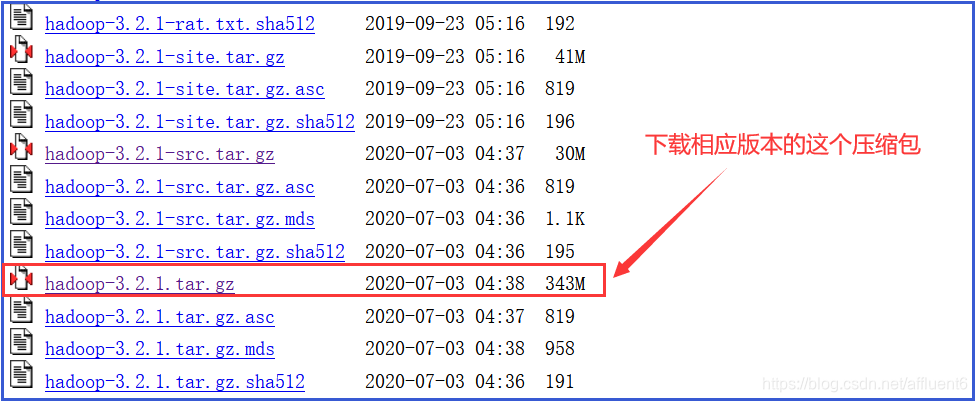
注:本系列博客使用的Hadoop版本为:Hadoop3.2.X
1.3.3 查看是否解压成功
[xqzhao@hadoop100 software]$ ls /opt/module/
hadoop-3.2.1
1.3.4 将Hadoop添加到环境变量
- (1) 获取Hadoop安装路径
[xqzhao@hadoop100 hadoop-3.2.1]$ pwd
/opt/module/hadoop-3.2.1
- (2) 打开/etc/profile文件
[xqzhao@hadoop100 hadoop-3.2.1]$ sudo vim /etc/profile
注:在profile文件末尾添加Hadoop路径:(shitf+g)
# HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.2.1
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
- (3) 让修改后的文件生效
[xqzhao@ hadoop100 hadoop-3.2.1]$ source /etc/profile
1.3.5 测试是否安装成功
[xqzhao@hadoop100 hadoop-3.2.1]$ hadoop version
Hadoop 3.2.1
1.3.6 重启(如果Hadoop命令不能用再重启)
[xqzhao@ hadoop100 hadoop-3.2.1]$ sync
[xqzhao@ hadoop100 hadoop-3.2.1]$ sudo reboot
1.4 Hadoop目录结构
1.4.1 查看Hadoop目录结构
[atguigu@hadoop101 hadoop-3.2.1]$ ll
总用量 52
drwxr-xr-x. 2 xqzhao xqzhao 4096 5月 22 2017 bin
drwxr-xr-x. 3 xqzhao xqzhao 4096 5月 22 2017 etc
drwxr-xr-x. 2 xqzhao xqzhao 4096 5月 22 2017 include
drwxr-xr-x. 3 xqzhao xqzhao 4096 5月 22 2017 lib
drwxr-xr-x. 2 xqzhao xqzhao 4096 5月 22 2017 libexec
-rw-r--r--. 1 xqzhao xqzhao 15429 5月 22 2017 LICENSE.txt
-rw-r--r--. 1 xqzhao xqzhao 101 5月 22 2017 NOTICE.txt
-rw-r--r--. 1 xqzhao xqzhao 1366 5月 22 2017 README.txt
drwxr-xr-x. 2 xqzhao xqzhao 4096 5月 22 2017 sbin
drwxr-xr-x. 4 xqzhao xqzhao 4096 5月 22 2017 share
1.4.2 重要目录
bin目录:存放对Hadoop相关服务(HDFS,YARN)进行操作的脚本etc目录:Hadoop的配置文件目录,存放Hadoop的配置文件lib目录:存放Hadoop的本地库(对数据进行压缩解压缩功能)sbin目录:存放启动或停止Hadoop相关服务的脚本share目录:存放Hadoop的依赖jar包、文档、和官方案例
注:看完这篇博客之后,你可以继续看本系列的第二篇进行测试,当然也可进入本系列的第三篇博客直接进行集群搭建:Hadoop运行模式-完全分布式(重点)
1.5 Windows安装Hadoop(并配置IDEA开发环境)
—>Windows安装Hadoop(并配置IDEA开发环境)
声明:本文是学习时记录的笔记,如有侵权请告知删除!
原视频地址:https://www.bilibili.com/video/BV1Me411W7PV