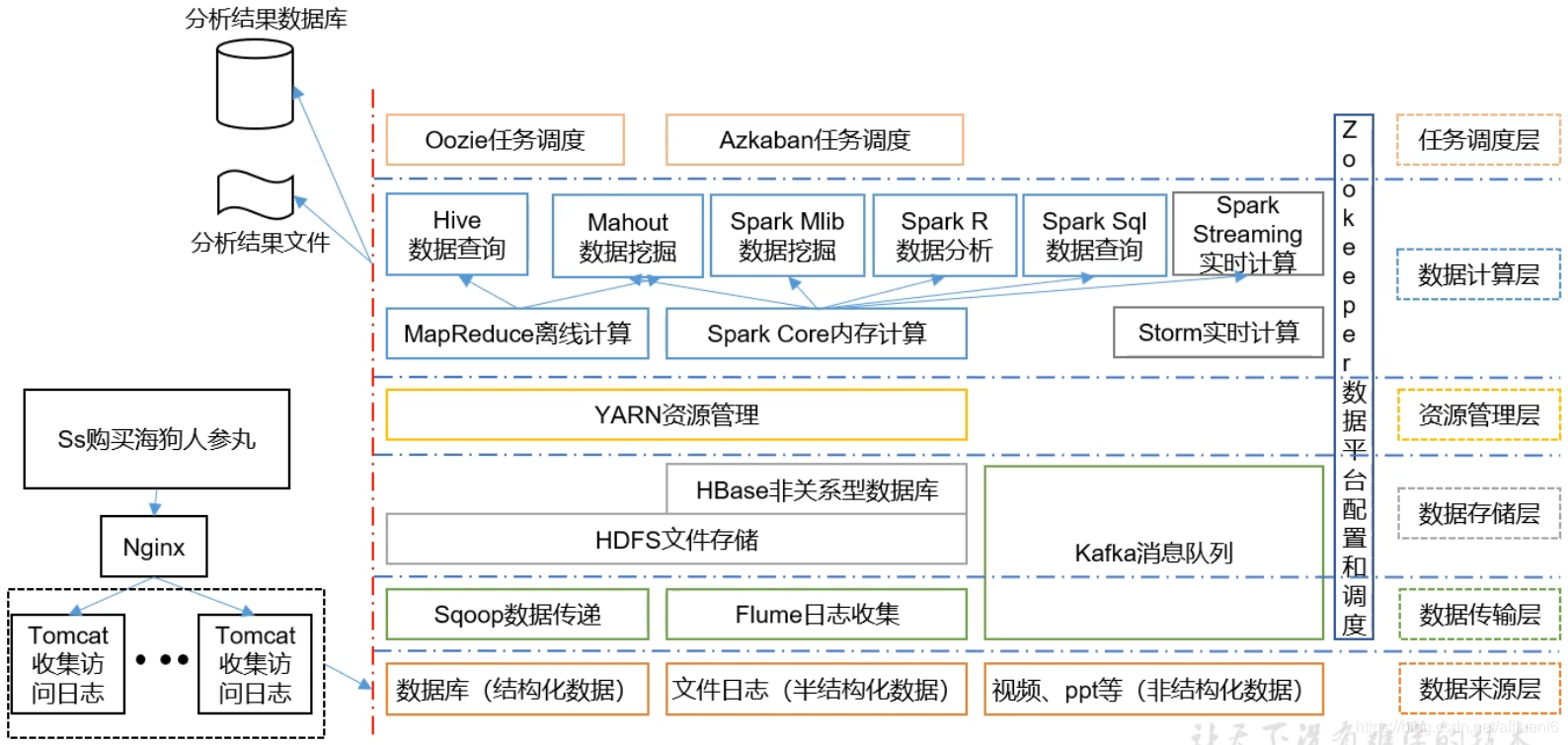
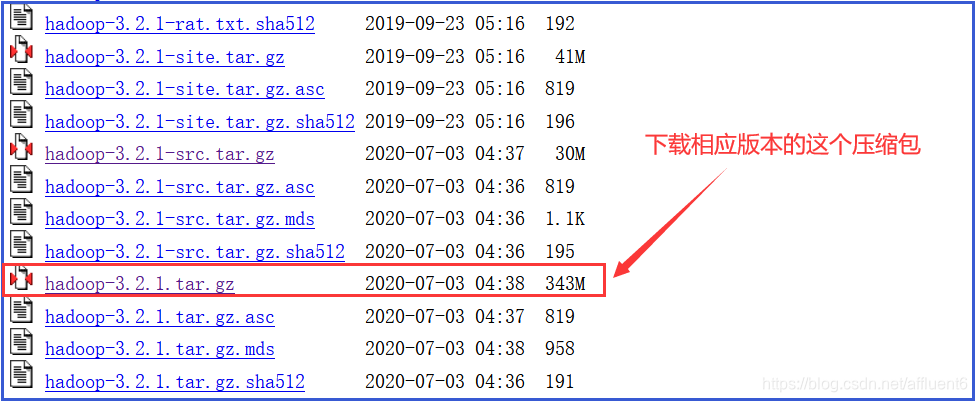
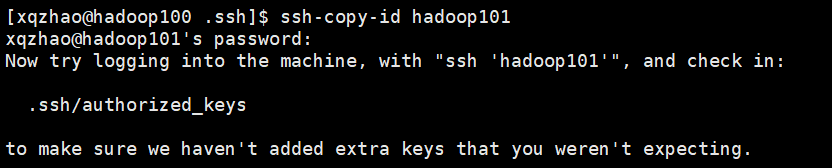
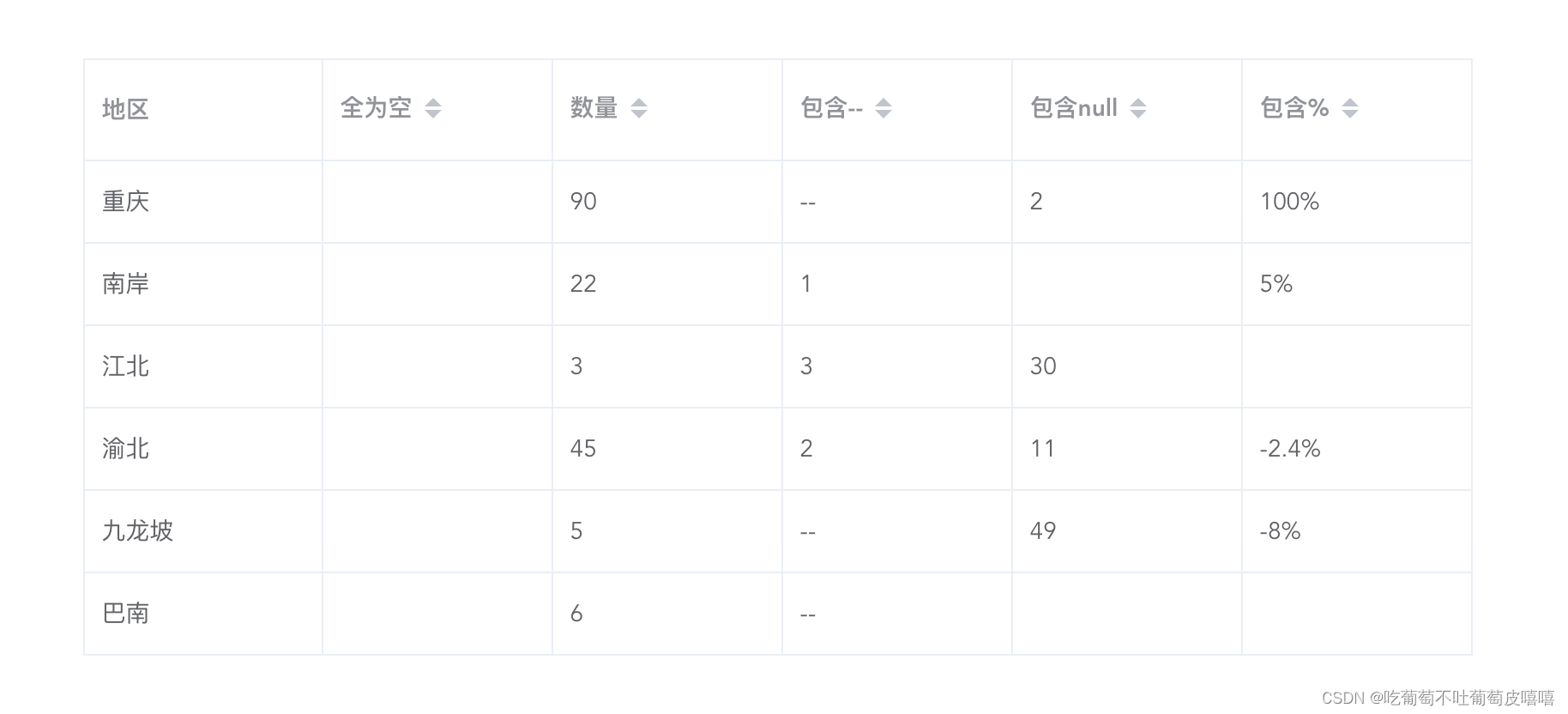
本文目录如下:
- 7 HDFS的高可用机制
- 7.1 HDFS高可用介绍
- 7.2 组件介绍
- 7.3 高可用机制-工作原理
- 7.4 分布式环境搭建
- 8 HDFS的联邦机制
- 8.1 背景概述
- 8.2 Federation架构设计
7 HDFS的高可用机制
7.1 HDFS高可用介绍
- 在Hadoop中,
NameNode所处的位置是非常重要的,整个HDFS文件系统的元数据信息都由NameNode来管理,NameNode的可用性直接决定了Hadoop的可用性,一旦`NameNode进程不能工作了,就会影响整个集群的正常使用。 - 在典型的HA集群中,两台独立的机器被配置为
NameNode。在工作集群中,NameNode机器中的一个处于Active状态,另一个处于Standby状态。Active NameNode负责群集中的所有客户端操作,而Standby充当从服务器。Standby机器保持足够的状态以提供快速故障切换(如果需要)。

7.2 组件介绍
-
ZKFailoverController
是基于Zookeeper的故障转移控制器,它负责控制NameNode的主备切换,ZKFailoverController会监测NameNode的健康状态,当发现Active NameNode出现异常时会通过Zookeeper进行一次新的选举,完成Active和`Standby状态的切换 -
HealthMonitor
周期性调用NameNode的HAServiceProtocol RPC接口 (monitorHealth 和 getServiceStatus),监控NameNode的健康状态并向ZKFailoverController反馈 -
ActiveStandbyElector
接收ZKFC的选举请求,通过Zookeeper自动完成主备选举,选举完成后回调ZKFaildverController的主备切换方法对NameNode进行Active和standby状态的切换 -
DataNode
NameNode包含了HDFS的元数据信息和数据块信息(blockmap),其中数据块信息通过DataNode主动向Active NameNode和Standby NameNode上报 -
共享存储系统
共享存储系统负责存储HDFS的元数据(EditsLog),Active NameNode (写入)和Standby NameNode(读取)通过共享存储系统实现元数据同步,在主备切换过程中,新的Active NameNode必须确保元数据同步完成才能对外提供服务
7.3 高可用机制-工作原理

- 上图的下半部分如下所示:

7.4 分布式环境搭建
- 使用完全分布式,实现
namenode高可用,ResourceManager的高可用集群运行服务规划

8 HDFS的联邦机制
8.1 背景概述
- 单
NameNode的架构使得HDFS在集群扩展性和性能上都有潜在的问题,当集群大到一定程度后,NameNode进程使用的内存可能会达到上百G,NameNode成为了性能的瓶颈。因而提出了namenode水平扩展方案--Federation。 Federation中文意思为联邦、联盟,是NameNode的Federation,也就是会有多个NameNode。多个NameNode的情况意味着有多个namespace(命名空间),区别于HA模式下的多NameNode,它们是拥有着同一个namespace。既然说到了NameNode的命名空间的概念,这里就看一下现有的HDFS数据管理架构,如下图所示:

8.2 Federation架构设计
HDFS Federatio是解决namenode内存瓶颈问题的水平横向扩展方案。Federation意味着在集群中将会有多个namenode/namespace。这些namenode之间是联合的,也就是说,他们之间相互独立且不需要互相协调,各自分工,管理自己的区域。分布式的datanode被用作通用的数据块存储存储设备。每个datanode要向集群中所有的namenode注册,且周期性地向所有namenode发送心跳和块报告,并执行来自所有namenode的命令。

Federation一个典型的例子就是上面提到的NameNode内存过高问题,我们完全可以将上面部分大的文件目录移到另外一个NameNode上做管理.更重要的一点在于,这些NameNode是共享集群中所有的DataNode的,它们还是在同一个集群内的。- 这时候在
DataNode上就不仅仅存储一个Block Pool下的数据了,而是多个(在DataNode的datadir所在目录里面查看BP-xX.xx.xx.xx打头的目录)。
namespace(命名空间):
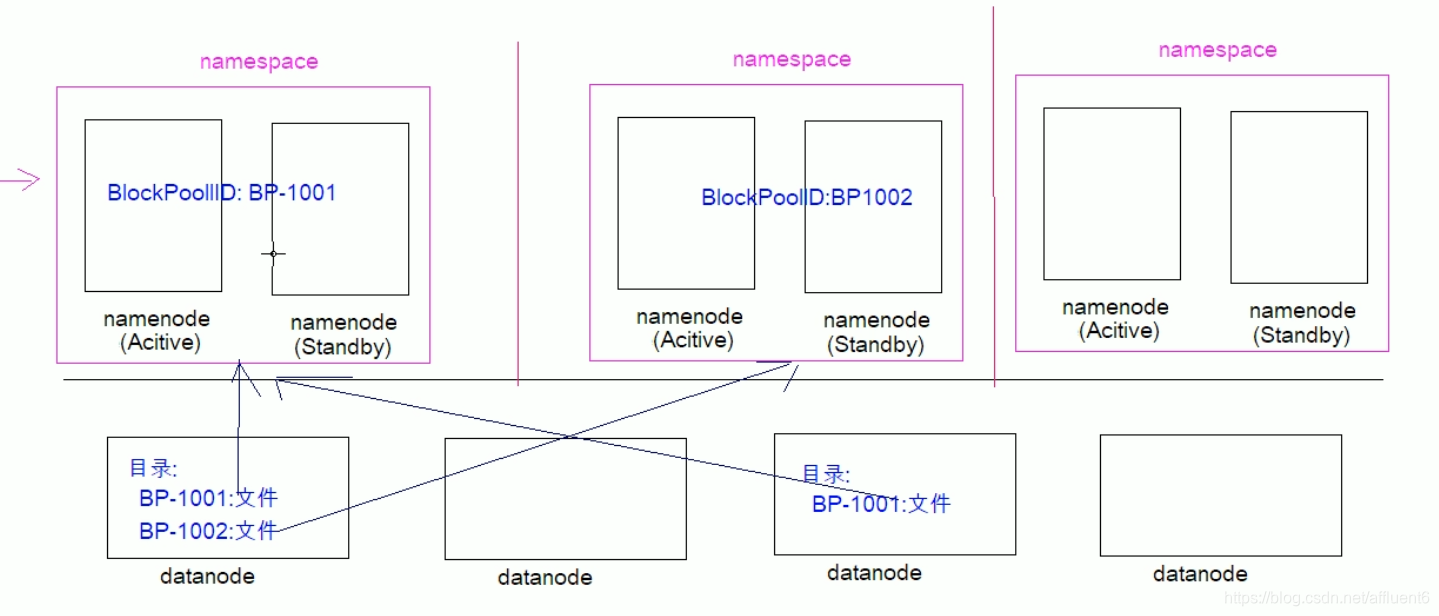
概括起来:
- 多个NN共用一个集群里的存储资源,每个NN都可以单独对外提供服务。
- 每个NN都会定义一个存储池,有单独的id,每个DN都为所有存储池提供存储。
- DN会按照存储池id向其对应的NN汇报块信息,同时,DN会向所有NN汇报本地存储可用资源情况。
HDFS Federation不足
HDFS Federation并没有完全解决单点故障问题。虽然namenode/namespace存在多个,但是从单个namenode/namespace看,仍然存在单点故障:如果某个namenode挂掉了,其管理的相应的文件便不可以访问。Federation中每个namenode仍然像之前HDFS上实现一样,配有一个secondary namenode,以便主namenode挂掉一下,用于还原元数据信息。- 所以一般集群规模真的很大的时候,会采用
HA+Federation的部署方案。也就是每个联合的namenodes都是ha的。
声明:本文是学习时记录的笔记,如有侵权请告知删除!
原视频地址:https://www.bilibili.com/video/BV1154y1U73k