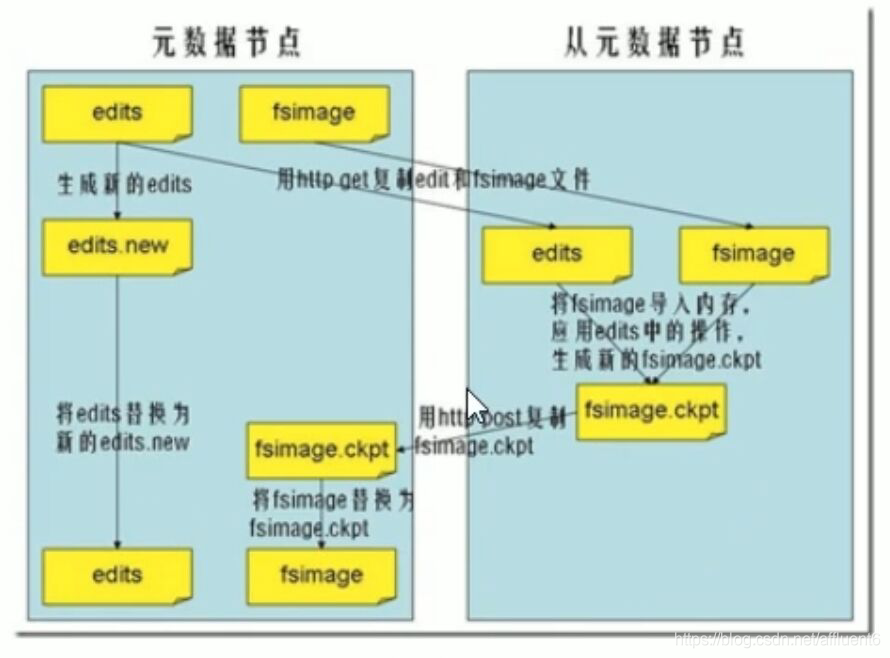
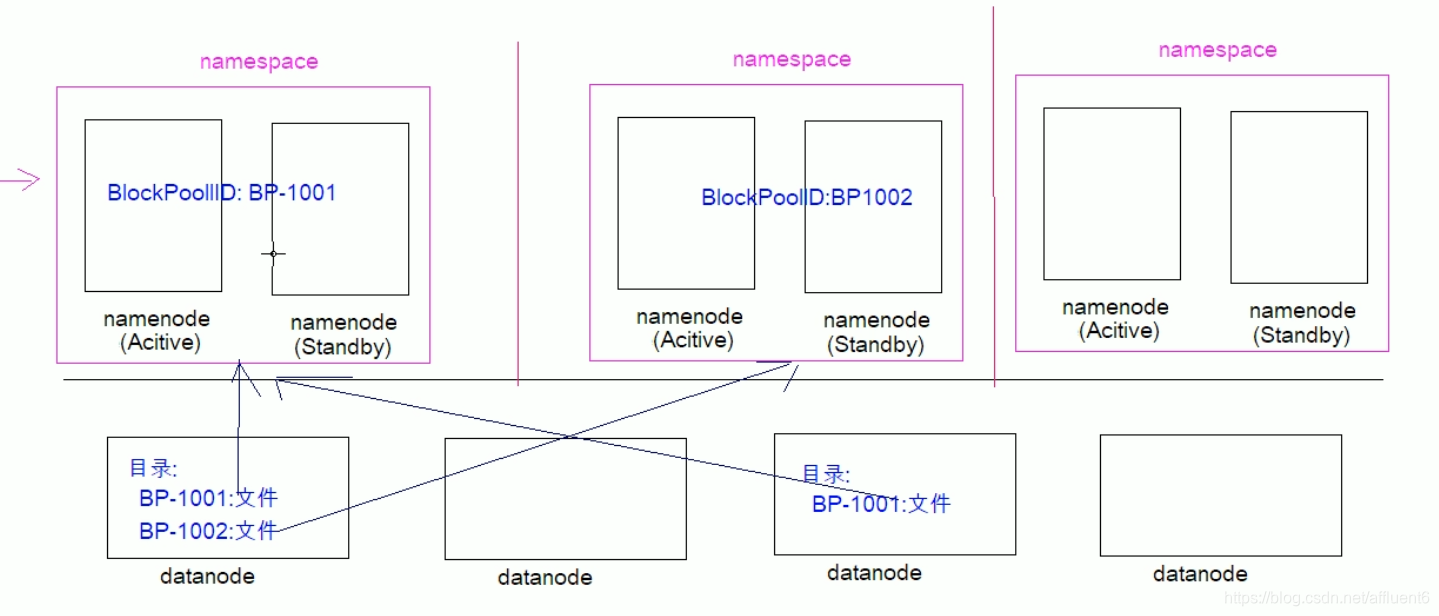
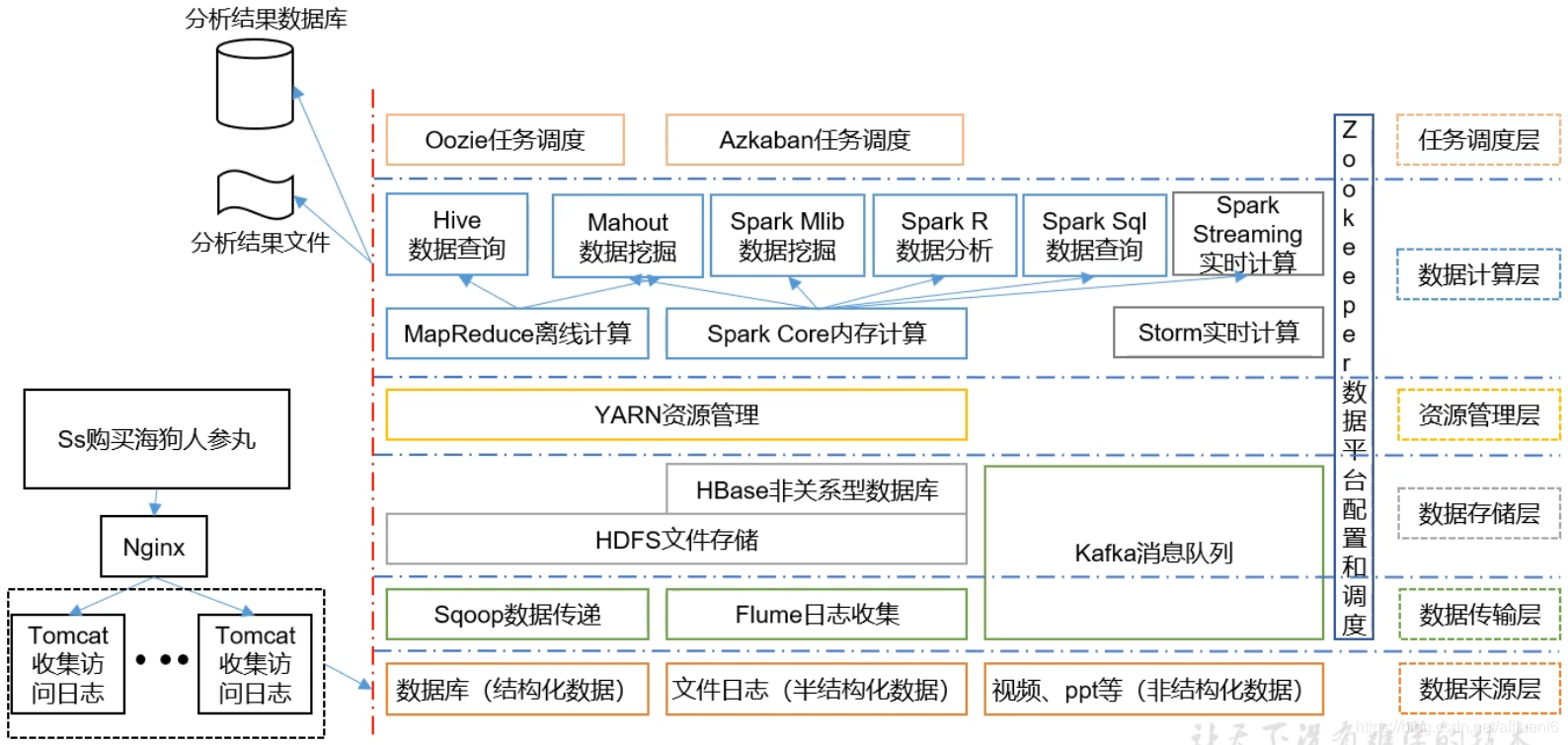
本文目录如下:
- 1 HDFS的命令行显示(基础)
- 1.1 启动Hadoop集群(方便后续的测试)
- 1.2 `help`
- 1.3 `ls`
- 1.4 `lsr`
- 1.5 `mkdir`
- 1.6 `put`
- 1.7 `moveFromLocal`
- 1.8 `appendToFile`
- 1.9 `cat`
- 1.10 `get`
- 1.11 `mv`
- 1.12 `rm`
- 1.13 `cp`
- 1.14 `chmod`
- 1.15 `chown`
- 1.16 `copyFromLocal`
- 1.17 `copyToLocal`
- 1.18 `getmerge`
- 1.19 `du`
- 1.20 `setrep`
- 2 HDFS的高级命令使用
- 2.1 HDFS文件限额配置
- 2.1.1 数量限额
- 2.1.2 空间大小限额
- 2.2 HDFS的安全模式
- 2.3 HDFS基准测试
- 2.3.1 测试写入速度
- 2.3.2 测试读取速度
- 2.3.3 清除测试数据
1 HDFS的命令行显示(基础)
1.1 启动Hadoop集群(方便后续的测试)
[xqzhao@hadoop100 /]$ sbin/start-dfs.sh
[xqzhao@hadoop101 /]$ sbin/start-yarn.sh
1.2 help
- 作用:输出这个命令参数
`hadoop fs -help rm`
1.3 ls
- 格式:hdfs dfs -ls URI
- 作用:类似于Linux的
ls命令,显示文件列表
`hdfs dfs -ls /`
1.4 lsr
- 格式:hdfs dfs -lsr URI
- 作用:在整个目录下递归执行ls,与UNIX中的**
ls -R**类似
`hdfs dfs -ls /`
1.5 mkdir
- 格式:hdfs dfs [-p] -mkdir < paths >
- 作用:以< path >中的URI作为参数,创建目录。使用-p参数可以递归创建目录
`hdfs dfs -p -mkdir /testData/text`
1.6 put
- 格式:hdfs dfs -put < localsrc > … < dest >
- 作用:将单个的源文件src或多个源文件src从本地文件系统拷贝到目标文件系统中(< dst >对应的路径)。也可以从标准输入中读取输入,写入目标文件系统
`hdfs dfs -put /root/a.txt /dir`
1.7 moveFromLocal
- 格式:hdfs dfs -moveFromLocal < localsrc > < dest >
- 作用:和
put命令类似,但是源文件localsrc拷贝之后自身被删除
`hdfs dfs -moveFromLocal /rootinstall.log /`
1.8 appendToFile
- 作用:追加一个文件到已经存在的文件末尾
[xqzhao@hadoop100 /]$ touch liubei.txt
[xqzhao@hadoop100 /]$ vim liubei.txt
输入
san gu mao lu
[xqzhao@hadoop100 /]$ hadoop fs -appendToFile liubei.txt /sanguo/shuguo/kongming.txt
1.9 cat
- 格式:hdfs dfs -cat URI [URI…]
- 作用:将参数所指示的文件内容输出到stdout
`hdfs dfs -cat /install.log`
1.10 get
- 格式:hdfs dfs -get [-ignorecrc] [-crc] < src > < localdst >
- 作用:将文件拷贝到本地文件系统。CRC校验失败的文件通过-ignorecrc选项拷贝。文件和CRC校验和可以通过-CRC选项拷贝
`hdfs dfs -get /install.log /export/serves`
1.11 mv
`hdfs dfs -mv /dir1/a.txt /dir2`
1.12 rm
- 格式:hdfs dfs -rm [-r] 【-skipTrash】 URI 【URI…】
- 作用:删除参数指定的文件,参数可以有多个。此命令只删除文件和非空目录。 如果指定-skipTrash选项,那么回收站可用的情况下,该选项将跳过回收站而直接删除文件;否则,在回收站可用时,在HDFS Shell中执行此命令,会将文件暂时放到回收站中。
`hdfs dfs -rm -r /dir1`
1.13 cp
- 格式:hdfs dfs -cp URI [URI …] < dest >
- 作用:将文件拷贝到目标路径下。如果< dest >为目录的话,可以将多个文件拷贝到该目录下
-f :选项将覆盖目标,如果它已经存在
-p:选项将保留文件属性(时间戳、所有权、许可、ACL、Xattr)
`hdfs dfs -cp /dir1/a.txt /dir2/b.txt`
1.14 chmod
- 格式:hdfs dfs -chmod [-R] URI [URI…]
- 作用:改变文件权限。如果使用
-R选项,则对整个目录有效递归执行。使用这一命令的用户必须是文件的所属用户,或超级用户。
`hdfs dfs -chomd -R 777 /install.log`
1.15 chown
- 格式:hdfs dfs -chown [-R] URI[URI…]
- 作用:改变文件的所属用户和用户组。如果使用
-R选项,则对整个目录有效递归执行。使用这一命令的用户必须是文件所属的用户,或超级用户。
`hdfs dfs -chown -R hadoop:hadoop /install.log`
1.16 copyFromLocal
- 作用:从本地文件系统中拷贝文件到HDFS路径去
`hadoop fs -copyFromLocal README.txt /`
1.17 copyToLocal
- 作用:从HDFS拷贝到本地
`hadoop fs -copyToLocal /sanguo/shuguo/kongming.txt ./`
1.18 getmerge
- 作用:合并下载多个文件,比如HDFS的目录 /user/atguigu/test下有多个文件:log.1, log.2,log.3,…
`hadoop fs -getmerge /user/atguigu/test/* ./zaiyiqi.txt`
1.19 du
- 作用:统计文件夹的大小信息
[xqzhao@hadoop100 /]$ hadoop fs -du -s -h /user/atguigu/test
2.7 K /user/atguigu/test
[xqzhao@hadoop100 /]$ hadoop fs -du -h /user/atguigu/test
1.3 K /user/atguigu/test/README.txt
15 /user/atguigu/test/jinlian.txt
1.4 K /user/atguigu/test/zaiyiqi.txt
1.20 setrep
- 作用:设置HDFS中文件的副本数量
`hadoop fs -setrep 10 /sanguo/shuguo/kongming.txt`
2 HDFS的高级命令使用
2.1 HDFS文件限额配置
- 在多人共用HDFS的环境下,配置设置非常重要。特别是在Hadoop处理大量资料的环境,如果没有配额管理,很容易把所有的空间用完造成别人无法存取。Hdfs的配额设定是针对目录而不是针对账号,可以让每个账号仅操作某一个目录,然后对目录设置配置。
- hdfs文件的限额配置允许我们以文件个数,或者文件大小来限制我们在某个目录下上传的文件数量或者文件内容总量,以便达到我们类似百度网盘网盘等限制每个用户允许上传的最大的文件的量。
`hdfs dfs -count -q -h /user/root/dir1` #查看配额信息
2.1.1 数量限额
`hdfs dfs -mkdir -p /user/root/dir` #创建hdfs文件夹
`hdfs dfsadmin -setQuota 2 dir` #给该文件夹下面设置最多上传两个文件,发现只能上传一个文件
`hdfs dfsadmin -clrQuota /user/root/dir` #清除文件数量限制
2.1.2 空间大小限额
-
在设置空间配额时,设置的空间至少是block_size * 3大小
hdfs dfsadmin -setSpaceQuota 4k /user/root/dir#限制空间大小4KB
hdfs dfs -put /root/a.txt /user /root/dir -
生成任意大小文件的命令:
dd if=/dev/zero of=1.txtbs=1M count=2#生成2M的文件 -
清除空间配置限额
hdfs dfs admin -clrSpaceQuota /user/root/dir
2.2 HDFS的安全模式
- 安全模式是hadoop的一种保护机制,用于保证集群中的数据块的安全性。当集群启动的时候,会首先进入安全模式。当系统处于安全模式时会检查数据块的完整性。
- 假设我们设置的副本数(即参数dfs.replication)是3,那么在datanode上就应该有3个副本存在,假设只存在2个副本,那么比例就是2/3=0.666。hdfs默认的副本率0.999。我们的副本率0.666明显小于0.999,因此系统会自动的复制副本到其他dataNode,使得副本率不小于0.999。如果系统中有5个副本,超过我们设定的3个副本,那么系统也会删除多于的2个副本。
- 在安全模式状态下,文件系统只接受读数据请求,而不接受删除、修改等变更请求。当整个系统达到安全标准时,HDFS自动离开安全模式。
安全模式操作命令
hdfs dfsadmin -safemode get#查看安全模式状态
hdfs dfsadmin -safemode enter#进入安全模式
hdfs dfsadmin -safemode leave#离开安全模式
2.3 HDFS基准测试
实际生产环境当中,hadoop的环境搭建完成之后,第一件事情就是进行压力测试,测试我们的集群的读取和写入速度I测试我们的网络带宽是否足够等一些基准测试
2.3.1 测试写入速度
- 向HDFS文件系统中写入数据,10个文件,每个文件10MB,文件存放到**/benchmarks/TestDFSIO**中
`hadoop jar /export/servers/hadoop-2.7.5/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.7.5.jar TestDFSIO -write -nrFiles 10 -fileSize 10MB`
- 完成之后查看写入速度结果
hdfs dfs -text /benchmarks/TestDFSIO/io_write/part-00000
2.3.2 测试读取速度
- 测试hdfs的读取文件性能
- 在HDFS文件系统中读入10个文件,每个文件10M
`hadoop jar /export/serves/hadoop-2.7.5/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.7.5.jar TestDFSIO -read -nrFiles 10 -fileSize 10MB`
- 查看读取结果
`hdfs dfs -text /benchamarks/TestDFSIO/io_read/part-00000`
2.3.3 清除测试数据
`hadoop jar /export/serves/hadoop-2.7.5/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.7.5.jar TestDFSIO -clean`
声明:本文是学习时记录的笔记,如有侵权请告知删除!
原视频地址:https://www.bilibili.com/video/BV1154y1U73k