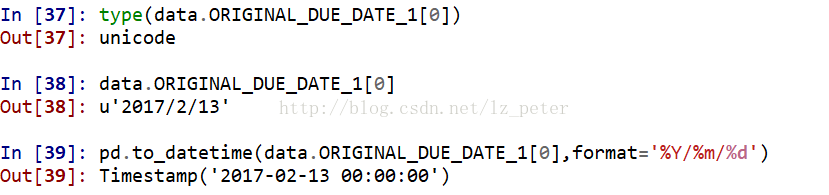
该文docker常用命令
docker search imagename:搜索查找镜像
docker pull imagename:拉取镜像到本地仓库
docker images:查看本地镜像
docker ps:查看正在运行的容器
docker ps -a:查看所有容器
docker run --name master -d -h master 本地镜像名:运行本地镜像 --name 容器名 -d 后台运行 -h 运行容器的主机名
docker exec -it 容器名 bash:进入容器名或id为多少的容器命令行
在容器里面退出命令行 退出该容器 exit ctrl+p+q
docker cp 路径 路径:复制文件
文章目录
hadoop_15">拉取hadoop镜像
1. 配置加速器:【直接复制过去运行】
sudo mkdir -p /etc/docker
sudo tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": ["https://uxk0ognt.mirror.aliyuncs.com"]
}
EOF
sudo systemctl daemon-reload
sudo systemctl restart docker
或者一步一步来:
#新建一个etc下面的docker文件
vi /etc/docker
#往里面输入json
{
"registry-mirrors": ["https://uxk0ognt.mirror.aliyuncs.com"]
}
#保存退出
:wq
#重载重启docker
systemctl daemon-reload
systemctl restart docker
hadoopstar_46">2.搜索hadoop镜像并拉取star最高的一个
[root@docker ~]# docker search hadoop
NAME DESCRIPTION STARS OFFICIAL AUTOMATED
sequenceiq/hadoop-docker An easy way to try Hadoop 656 [OK]
uhopper/hadoop Base Hadoop image with dynamic configuration… 102 [OK]
harisekhon/hadoop Apache Hadoop (HDFS + Yarn, tags 2.2 - 2.8) 67 [OK]
bde2020/hadoop-namenode Hadoop namenode of a hadoop cluster 50 [OK]
bde2020/hadoop-datanode Hadoop datanode of a hadoop cluster 37 [OK]
bde2020/hadoop-base Base image to create hadoop cluster. 20 [OK]
izone/hadoop Hadoop 2.8.5 Ecosystem fully distributed, Ju… 16 [OK]
uhopper/hadoop-namenode Hadoop namenode 11 [OK]
bde2020/hadoop-nodemanager Hadoop node manager docker image. 10 [OK]
bde2020/hadoop-resourcemanager Hadoop resource manager docker image. 9 [OK]
uhopper/hadoop-datanode Hadoop datanode 9 [OK]
singularities/hadoop Apache Hadoop 8 [OK]
harisekhon/hadoop-dev Apache Hadoop (HDFS + Yarn) + Dev Tools + Gi… 7 [OK]
apache/hadoop Apache Hadoop convenience builds 7 [OK]
bde2020/hadoop-historyserver Hadoop history server docker image. 7 [OK]
anchorfree/hadoop-slave Hadoop slave image 5
portworx/hadoop-namenode Hadoop in Docker with Networking and Persist… 4 [OK]
flokkr/hadoop-hdfs-datanode Container for HDFS datanode of Apache Hadoop… 4
uhopper/hadoop-resourcemanager Hadoop resourcemanager 4 [OK]
portworx/hadoop-yarn Hadoop in Docker with Networking and Persist… 2 [OK]
newnius/hadoop Setup a Hadoop cluster with docker. 1 [OK]
danisla/hadoop Hadoop image built with native libraries 1
openpai/hadoop-run 1
flokkr/hadoop-yarn-nodemanager Container for YARN nodemanager of Apache Had… 1
flokkr/hadoop Apache Hadoop container with advanced config… 0
[root@docker ~]# docker pull docker.io/sequenceiq/hadoop-docker
Using default tag: latest
latest: Pulling from sequenceiq/hadoop-docker
Image docker.io/sequenceiq/hadoop-docker:latest uses outdated schema1 manifest format. Please upgrade to a schema2 image for better future compatibility. More information at https://docs.docker
.com/registry/spec/deprecated-schema-v1/b253335dcf03: Pull complete
a3ed95caeb02: Pull complete
69623ef05416: Pull complete
8d2023764774: Pull complete
0c3c0ff61963: Pull complete
ff0696749bf6: Pull complete
72accdc282f3: Pull complete
5298ddb3b339: Pull complete
f252bbba6bda: Pull complete
3984257f0553: Pull complete
26343a20fa29: Pull complete
faf713cb3a4f: Pull complete
b7fa02232da2: Pull complete
b6e914dfab57: Pull complete
ed0c4a7a604c: Pull complete
d5381e4d358c: Pull complete
d31888a1eaab: Pull complete
a38563c3a214: Pull complete
1e2a95e2180f: Pull complete
c0b49f2a09a4: Pull complete
e771f6981245: Pull complete
68cc4c8159e8: Pull complete
d7c5efdc73a8: Pull complete
59cb42af0672: Pull complete
4c15bc655c2d: Pull complete
c70804bb2ffa: Pull complete
b7dcfd72bdf8: Pull complete
c08c87bb3e91: Pull complete
d7099625e685: Pull complete
dcb8dfa26be4: Pull complete
4afe05176740: Pull complete
6a54afb04bb7: Pull complete
57ffa0650a47: Pull complete
60aa55c9a90b: Pull complete
247c8fd8465a: Pull complete
e00909753b86: Pull complete
18f53e764edf: Pull complete
3a8c9b2d833a: Pull complete
770ef75e185a: Pull complete
0173662eb77d: Pull complete
c0a37ad8136f: Pull complete
47eeef0823a8: Pull complete
77c1cad6eb69: Pull complete
ed6629089518: Pull complete
36a49c5cc0d9: Pull complete
e6a7899cd72b: Pull complete
Digest: sha256:5a971a61840d9d32752330a891d528d35a558adf31d99c46205f1180af8e1abd
Status: Downloaded newer image for sequenceiq/hadoop-docker:latest
docker.io/sequenceiq/hadoop-docker:lates
hadoop_130">3.创建hadoop容器
(1).查看镜像
docker images
(2).创建master节点
docker run --name master -d -h master sequenceiq/hadoop-docker
--name:容器名称
-d:后台运行
-h:为容器设置主机名为master
(3).创建slave节点
[root@docker ~]# docker run --name slave1 -d -h slave1 sequenceiq/hadoop-docker
5b1e70f4c9016af276fba0a6d10e65ae4ff454901cd04a5d47f11aabc7bfd71a
[root@docker ~]# docker run --name slave2 -d -h slave2 sequenceiq/hadoop-docker
38b6a3406d2051bc3c11ed539afe3e92e36647049b78a09d1c7e48d7dfc7b90c
[root@docker ~]#
(4).查看运行的容器
[root@docker ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS
NAMES38b6a3406d20 sequenceiq/hadoop-docker "/etc/bootstrap.sh -d" About a minute ago Up About a minute 2122/tcp, 8030-8033/tcp, 8040/tcp, 8042/tcp, 8088/tcp, 19888/tcp, 49707/tcp, 50010/tc
p, 50020/tcp, 50070/tcp, 50075/tcp, 50090/tcp slave25b1e70f4c901 sequenceiq/hadoop-docker "/etc/bootstrap.sh -d" About a minute ago Up About a minute 2122/tcp, 8030-8033/tcp, 8040/tcp, 8042/tcp, 8088/tcp, 19888/tcp, 49707/tcp, 50010/tc
p, 50020/tcp, 50070/tcp, 50075/tcp, 50090/tcp slave1b372c98fa64e sequenceiq/hadoop-docker "/etc/bootstrap.sh -d" 6 minutes ago Up 6 minutes 2122/tcp, 8030-8033/tcp, 8040/tcp, 8042/tcp, 8088/tcp, 19888/tcp, 49707/tcp, 50010/tc
p, 50020/tcp, 50070/tcp, 50075/tcp, 50090/tcp master[root@docker ~]#
查看所有容器:docker ps -a
(5).进入容器查看jdk
[root@docker ~]# docker exec -it master bash
bash-4.1# java -version
java version "1.7.0_71"
Java(TM) SE Runtime Environment (build 1.7.0_71-b14)
Java HotSpot(TM) 64-Bit Server VM (build 24.71-b01, mixed mode)
bash-4.1# hostname
master
-bash-4.1# exit #退出命令行 exit
logout
bash-4.1# 退出容器 ctrl+p+q
[root@docker ~]#
hadoop_178">hadoop集群前期准备配置
1.进行ssh免密配置【所有节点都需要,master节点示例】
(1).先初始化,再以rsa方式生成密钥
里面自己存在的免密配置的文件删除或者覆盖就好了。
bash-4.1# ssh localhost
-bash-4.1# cd ~/.ssh
-bash-4.1# ll
total 16
-rw-r--r--. 1 root root 399 Jul 22 2015 authorized_keys
-rw-------. 1 root root 94 Jul 22 2015 config
-rw-------. 1 root root 1671 Jul 22 2015 id_rsa#私钥
-rw-r--r--. 1 root root 399 Jul 22 2015 id_rsa.pub#公钥
-bash-4.1# ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
/root/.ssh/id_rsa already exists.
Overwrite (y/n)? y
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
58:5f:eb:b5:58:93:61:be:ae:eb:8b:7b:d7:7c:b7:2c root@master
The key's randomart image is:
+--[ RSA 2048]----+
| |
| |
| . . o |
| o . . + o |
| . S . . * |
| . + + |
| o oo |
| ..Eo =|
| o+==oo+|
+-----------------+
-bash-4.1#
(2).将公钥汇到authorized_keys中,固定名字
-bash-4.1# ll
total 16
-rw-r--r--. 1 root root 399 Jul 22 2015 authorized_keys
-rw-------. 1 root root 94 Jul 22 2015 config
-rw-------. 1 root root 1675 May 11 21:22 id_rsa
-rw-r--r--. 1 root root 393 May 11 21:22 id_rsa.pub
-bash-4.1# rm -r authorized_keys
-bash-4.1# ll
total 8
-rw-------. 1 root root 1675 May 11 21:22 id_rsa
-rw-r--r--. 1 root root 393 May 11 21:22 id_rsa.pub
-bash-4.1# cat id_rsa.pub > authorized_keys
-bash-4.1# ll
total 12
-rw-r--r--. 1 root root 393 May 11 21:27 authorized_keys
-rw-------. 1 root root 1675 May 11 21:22 id_rsa
-rw-r--r--. 1 root root 393 May 11 21:22 id_rsa.pub
cat authorized_keys
ssh-rsa AAAAB3NzaC1yc2EAAAABIwAAAQEAmkOb4NhZYCi9oRwtmMVQo/P5a7F5u1OkL6xUHYSrQY47Vse6K0bduEbe29acarK1jR4xS2tcICGpWhDoFfhV0tsy9gnNPjwEDgOhZ8jeseriXq6tb4kLFMbIQZqpiapoe9I7KD7Ak3VbIcpKH+oh+wjvLzVGc
YCq2/n2MgAyhHI/MDA765Sg5SgcEWASJXsBJ6RYvfViBahVLIc0C9EXwO0v6J0hYH7Qo4brsRfXWGrgZs5otdHS9ndXLdmOqhThEhuJgFGqIqfVV0MfvA4yxgao5UchJrZ+7kjyhbljvGurwd3DCSJApDuM4JS4+d/Nulh5quB37XZ9tor8WWonsQ== root@master-bash-4.1#
注:可以用命令
cp /etc/skel/.bash* /root/和su
把-bash-4.1#变成我们熟悉的[root@master~]#,ctrl+p+q可以退出容器回到主机即宿主机
bash-4.1# cp /etc/skel/.bash* /root/
bash-4.1# su
[root@master~]#
**注:**一定不能删除config文件,我这边是删除了出的问题,后面如果看到ssh目录下我的教程没有config文件,请不要介意,我已经解决了,上面命令是没有删除config文件的,如果不小心删除可以新建该文件并加入以下内容:
Host *
UserKnownHostsFile /dev/null
StrictHostKeyChecking no
LogLevel quiet
Port 2122
(3).在其余节点各自进行上述操作
(4).把公钥汇到一个authorized_keys中
办法是先各自从docker容器取出来放到主机上,在主机上汇到一起在放到容器中。注意我取出来放到主机/home/hadoop/目录下的名字是ahthorized_master、slave1、slave2_keys,不太合适,但能用,要保证ssh目录下的名字是authorized_keys
[root@docker ~]# mkdir /home/hadoop/
[root@docker ~]# docker cp b372:/root/.ssh/authorized_keys /home/hadoop/ahthorized_master_keys
[root@docker ~]# docker cp slave1:/root/.ssh/authorized_keys /home/hadoop/ahthorized_slave1_keys
[root@docker ~]# docker cp slave2:/root/.ssh/authorized_keys /home/hadoop/ahthorized_slave2_keys
[root@docker ~]# cd /home/hadoop/
[root@docker hadoop]# ll
总用量 12
-rw-r--r--. 1 root root 393 5月 11 21:27 ahthorized_master_keys
-rw-r--r--. 1 root root 393 5月 11 21:45 ahthorized_slave1_keys
-rw-r--r--. 1 root root 393 5月 11 21:38 ahthorized_slave2_keys
[root@docker hadoop]# cat ahthorized_master_keys ahthorized_slave1_keys ahthorized_slave2_keys > authorized_keys
[root@docker hadoop]# cat authorized_keys
ssh-rsa AAAAB3NzaC1yc2EAAAABIwAAAQEAmkOb4NhZYCi9oRwtmMVQo/P5a7F5u1OkL6xUHYSrQY47Vse6K0bduEbe29acarK1jR4xS2tcICGpWhDoFfhV0tsy9gnNPjwEDgOhZ8jeseriXq6tb4kLFMbIQZqpiapoe9I7KD7Ak3VbIcpKH+oh+wjvLzVGc
YCq2/n2MgAyhHI/MDA765Sg5SgcEWASJXsBJ6RYvfViBahVLIc0C9EXwO0v6J0hYH7Qo4brsRfXWGrgZs5otdHS9ndXLdmOqhThEhuJgFGqIqfVV0MfvA4yxgao5UchJrZ+7kjyhbljvGurwd3DCSJApDuM4JS4+d/Nulh5quB37XZ9tor8WWonsQ== root@masterssh-rsa AAAAB3NzaC1yc2EAAAABIwAAAQEA1E9PWjB45uJXrg7feySs6VrX6h4K3iYl+XHZqFneI0INKKN/OdFMmjj9xiMPJ6Jl+gExuidozEtOU0p+1MjlJCuvd1WIM/NxzFeP7taHi7mclz6u9SEQgNTC29GNjKaGctVGKyQ8qkJER22nMpF65og+fGot7
ajwDobph5KcW0PXBI2A90vFG3utN5ze+4CoPpsriG+97etNI+j0seAjaCsIFEo9EK9sYYMagTvtk/AdqaB/nqF6IuUbp96h5erZguoMlWqXNGRfg8hmEx8v2STU2bswWlS/ZjQ7ZlVcNFD2awC31KOQoT2e/EKLYLszcZuj3LiNss7y/f3gtME36w== root@slave1ssh-rsa AAAAB3NzaC1yc2EAAAABIwAAAQEA7I4HB2GaeVvJUdqH/QVfT5pYK+Y4LOS5yZZKgcJD3Vr3Ki+cVQA02jCtU5cCckSewP/5MLygdKN/OZT6xCOZgTY7y0piPjaZoPeuCAg4u3y/SQqbTVY7S3+YQqUXKtRVTQwxV0Y8wVXsncbC9U52VAwVEtst0
21EJiSNcs6Afkw/LgrP6pSr8pkkCi4SMlvszEgmGQyBbGRgfF3eKtLANq+hm9cT+2A+ypWcGWgTiyZnsLDEAoUsEg033danSVlOQBO3zQPjsuKLqntA40WCYAQMEeo6pXZnGKfoIgtjDI00trJHB2bMEsya2ACnGMJSlaJBeDEAj2nDIO0bKt3cqw== root@slave2
[root@docker hadoop]# docker cp /home/hadoop/authorized_keys master:/root/.ssh/authorized_keys
[root@docker hadoop]# docker cp /home/hadoop/authorized_keys slave1:/root/.ssh/authorized_keys
[root@docker hadoop]# docker cp /home/hadoop/authorized_keys slave2:/root/.ssh/authorized_keys
[root@docker hadoop]#
查看:
bash-4.1# cat ~/.ssh/authorized_keys
ssh-rsa AAAAB3NzaC1yc2EAAAABIwAAAQEAmkOb4NhZYCi9oRwtmMVQo/P5a7F5u1OkL6xUHYSrQY47Vse6K0bduEbe29acarK1jR4xS2tcICGpWhDoFfhV0tsy9gnNPjwEDgOhZ8jeseriXq6tb4kLFMbIQZqpiapoe9I7KD7Ak3VbIcpKH+oh+wjvLzVGc
YCq2/n2MgAyhHI/MDA765Sg5SgcEWASJXsBJ6RYvfViBahVLIc0C9EXwO0v6J0hYH7Qo4brsRfXWGrgZs5otdHS9ndXLdmOqhThEhuJgFGqIqfVV0MfvA4yxgao5UchJrZ+7kjyhbljvGurwd3DCSJApDuM4JS4+d/Nulh5quB37XZ9tor8WWonsQ== root@masterssh-rsa AAAAB3NzaC1yc2EAAAABIwAAAQEA1E9PWjB45uJXrg7feySs6VrX6h4K3iYl+XHZqFneI0INKKN/OdFMmjj9xiMPJ6Jl+gExuidozEtOU0p+1MjlJCuvd1WIM/NxzFeP7taHi7mclz6u9SEQgNTC29GNjKaGctVGKyQ8qkJER22nMpF65og+fGot7
ajwDobph5KcW0PXBI2A90vFG3utN5ze+4CoPpsriG+97etNI+j0seAjaCsIFEo9EK9sYYMagTvtk/AdqaB/nqF6IuUbp96h5erZguoMlWqXNGRfg8hmEx8v2STU2bswWlS/ZjQ7ZlVcNFD2awC31KOQoT2e/EKLYLszcZuj3LiNss7y/f3gtME36w== root@slave1ssh-rsa AAAAB3NzaC1yc2EAAAABIwAAAQEA7I4HB2GaeVvJUdqH/QVfT5pYK+Y4LOS5yZZKgcJD3Vr3Ki+cVQA02jCtU5cCckSewP/5MLygdKN/OZT6xCOZgTY7y0piPjaZoPeuCAg4u3y/SQqbTVY7S3+YQqUXKtRVTQwxV0Y8wVXsncbC9U52VAwVEtst0
21EJiSNcs6Afkw/LgrP6pSr8pkkCi4SMlvszEgmGQyBbGRgfF3eKtLANq+hm9cT+2A+ypWcGWgTiyZnsLDEAoUsEg033danSVlOQBO3zQPjsuKLqntA40WCYAQMEeo6pXZnGKfoIgtjDI00trJHB2bMEsya2ACnGMJSlaJBeDEAj2nDIO0bKt3cqw== root@slave2bash-4.1#
2.进行IP配置
(1).在master上 ip addr查看地址,ping主机,修改hosts做映射
bash-4.1# ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
4: eth0@if5: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue state UP
link/ether 02:42:ac:11:00:02 brd ff:ff:ff:ff:ff:ff
inet 172.17.0.2/16 brd 172.17.255.255 scope global eth0
valid_lft forever preferred_lft forever
bash-4.1# ping 192.168.72.123
PING 192.168.72.123 (192.168.72.123) 56(84) bytes of data.
64 bytes from 192.168.72.123: icmp_seq=1 ttl=64 time=0.081 ms
64 bytes from 192.168.72.123: icmp_seq=2 ttl=64 time=0.171 ms
^Z
[3]+ Stopped ping 192.168.72.123
bash-4.1# vi /etc/hosts
127.0.0.1 localhost
::1 localhost ip6-localhost ip6-loopback
fe00::0 ip6-localnet
ff00::0 ip6-mcastprefix
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
172.17.0.2 master
172.17.0.3 slave1
172.17.0.4 slave2
(2).在slave节点上做同样的事
(3).验证
[root@docker hadoop]# docker exec -it master bash
[root@master /]# ssh slave1
Last login: Wed May 12 00:09:50 2021 from master
[root@slave1 ~]# logout
[root@master /]# ssh slave2
[root@slave2 ~]# logout
[root@master /]# exit
[root@docker hadoop]#
hadoop_351">配置hadoop
1.修改配置文件
hadoop_353">(1).查看hadoop位置
[root@docker hadoop]# docker exec -it master bash
[root@master ~]# whereis hadoop
hadoop: /usr/local/hadoop
[root@master ~]# cd /usr/local/hadoop/
[root@master hadoop]# ll
total 32
-rw-r--r--. 1 10021 10021 15429 Apr 10 2015 LICENSE.txt
-rw-r--r--. 1 10021 10021 101 Apr 10 2015 NOTICE.txt
-rw-r--r--. 1 10021 10021 1366 Apr 10 2015 README.txt
drwxr-xr-x. 2 10021 10021 194 Apr 10 2015 bin
drwxr-xr-x. 1 10021 10021 20 Apr 10 2015 etc
drwxr-xr-x. 2 10021 10021 106 Apr 10 2015 include
drwxr-xr-x. 1 root root 187 Jul 22 2015 input
drwxr-xr-x. 1 10021 10021 20 Jul 22 2015 lib
drwxr-xr-x. 2 10021 10021 239 Apr 10 2015 libexec
drwxr-xr-x. 1 root root 4096 May 11 23:59 logs
drwxr-xr-x. 2 10021 10021 4096 Apr 10 2015 sbin
drwxr-xr-x. 4 10021 10021 31 Apr 10 2015 share
[root@master hadoop]# cd etc/hadoop
[root@master hadoop]# ll
total 160
-rw-r--r--. 1 10021 10021 4436 Apr 10 2015 capacity-scheduler.xml
-rw-r--r--. 1 10021 10021 1335 Apr 10 2015 configuration.xsl
-rw-r--r--. 1 10021 10021 318 Apr 10 2015 container-executor.cfg
-rw-r--r--. 1 10021 10021 152 May 11 23:57 core-site.xml
-rw-r--r--. 1 root root 154 Jul 22 2015 core-site.xml.template
-rw-r--r--. 1 10021 10021 3670 Apr 10 2015 hadoop-env.cmd
-rwxr-xr-x. 1 10021 10021 4302 Jul 22 2015 hadoop-env.sh
-rw-r--r--. 1 10021 10021 2490 Apr 10 2015 hadoop-metrics.properties
-rw-r--r--. 1 10021 10021 2598 Apr 10 2015 hadoop-metrics2.properties
-rw-r--r--. 1 10021 10021 9683 Apr 10 2015 hadoop-policy.xml
-rw-r--r--. 1 root root 126 Jul 22 2015 hdfs-site.xml
-rwxr-xr-x. 1 10021 10021 1449 Apr 10 2015 httpfs-env.sh
-rw-r--r--. 1 10021 10021 1657 Apr 10 2015 httpfs-log4j.properties
-rw-r--r--. 1 10021 10021 21 Apr 10 2015 httpfs-signature.secret
-rw-r--r--. 1 10021 10021 620 Apr 10 2015 httpfs-site.xml
-rw-r--r--. 1 10021 10021 3518 Apr 10 2015 kms-acls.xml
-rwxr-xr-x. 1 10021 10021 1527 Apr 10 2015 kms-env.sh
-rw-r--r--. 1 10021 10021 1631 Apr 10 2015 kms-log4j.properties
-rw-r--r--. 1 10021 10021 5511 Apr 10 2015 kms-site.xml
-rw-r--r--. 1 10021 10021 11237 Apr 10 2015 log4j.properties
-rw-r--r--. 1 10021 10021 951 Apr 10 2015 mapred-env.cmd
-rwxr-xr-x. 1 10021 10021 1383 Apr 10 2015 mapred-env.sh
-rw-r--r--. 1 10021 10021 4113 Apr 10 2015 mapred-queues.xml.template
-rw-r--r--. 1 root root 138 Jul 22 2015 mapred-site.xml
-rw-r--r--. 1 10021 10021 758 Apr 10 2015 mapred-site.xml.template
-rw-r--r--. 1 10021 10021 10 Apr 10 2015 slaves
-rw-r--r--. 1 10021 10021 2316 Apr 10 2015 ssl-client.xml.example
-rw-r--r--. 1 10021 10021 2268 Apr 10 2015 ssl-server.xml.example
-rw-r--r--. 1 10021 10021 2250 Apr 10 2015 yarn-env.cmd
-rwxr-xr-x. 1 10021 10021 4567 Apr 10 2015 yarn-env.sh
-rw-r--r--. 1 root root 1525 Jul 22 2015 yarn-site.xml
[root@master hadoop]#
hadoopenvsh_410">(2).配置hadoop-env.sh
vi hadoop-env.sh #里面用的默认的,没必要改了
(2).配置核心配置文件core-site.xml
配置hdfs的地址和端口号 默认是合适的加个tmp路径就可以了。
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/hadoop/tmp</value>
</property>
</configuration>
hdfssitexml_431">(3).配置hdfs-site.xml
配置hdfs备份数量【一般三份比较好,机子存储盘不大就改成一份了】,配置namenode和datanode的数据路径,提前键好路径,自己可以按照自己情况来。我的是/hadoop/data、/hadoop/name
[root@master hadoop]# mkdirp -p /hadoop/name
bash: mkdirp: command not found
[root@master hadoop]# mkdir -p /hadoop/name
[root@master hadoop]# mkdir -p /hadoop/data
[root@master hadoop]# cd /hadoop
[root@master hadoop]# ll
total 0
drwxr-xr-x. 2 root root 6 May 12 00:44 data
drwxr-xr-x. 2 root root 6 May 12 00:44 name
[root@master hadoop]#
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/hadoop/data</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/hadoop/name</value>
</property>
</configuration>
(4).修改mapped-site.xml【mapreduce运行在yarn上】
默认配好了。。。。
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>localhost:9001</value>
</property>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
(5).修改yarn-site.xml【yarn配置】
把原有的加后缀名,新建一该文件:
[root@master hadoop]# cp yarn-site.xml yarn-site.xml.bak
[root@master hadoop]# ll yarn-site.*
-rw-r--r--. 1 root root 1525 Jul 22 2015 yarn-site.xml
-rw-r--r--. 1 root root 1525 May 12 00:50 yarn-site.xml.bak
[root@master hadoop]# rm yarn-site.xml
[root@master hadoop]# vi yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value> </property> <property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8089</value>
</property>
</configuration>
(6).将这些发送到其它节点
[root@master etc]# scp -r hadoop/ slave1:/usr/local/hadoop/etc/
[root@master etc]# scp -r hadoop/ slave2:/usr/local/hadoop/etc/
(7).配置slaves【注意】
这个地方,分发完之后再修改master的slaves文件,删除localhost,加入数据节点的名称,每一个名称占一行。如果改完分发过去,其余两个slave节点,一定要恢复成本来默认的只有localhost的文件,不然后面运行集群,这两个节点会多开namenode等进程。
[root@master hadoop]# vi slaves
## 删除里面的东西 加入master换行slave1换行slave2
2.启动集群做验证
(1).初始化
#到/usr/local/hadoop/bin/目录下运行
[root@master bin]# ./hadoop namenode -format
注意:初始化完之后会默认开启hadoop集群的。
(2).开启集群
在sbin目录下开启
[root@master hadoop]# cd sbin/
[root@master sbin]# ./start-all.sh
This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh
Starting namenodes on [master]
master: starting namenode, logging to /usr/local/hadoop/logs/hadoop-root-namenode-master.out
slave2: starting datanode, logging to /usr/local/hadoop/logs/hadoop-root-datanode-slave2.out
slave1: starting datanode, logging to /usr/local/hadoop/logs/hadoop-root-datanode-slave1.out
master: starting datanode, logging to /usr/local/hadoop/logs/hadoop-root-datanode-master.out
Starting secondary namenodes [0.0.0.0]
0.0.0.0: starting secondarynamenode, logging to /usr/local/hadoop/logs/hadoop-root-secondarynamenode-master.out
starting yarn daemons
resourcemanager running as process 564. Stop it first.
slave2: starting nodemanager, logging to /usr/local/hadoop/logs/yarn-root-nodemanager-slave2.out
master: starting nodemanager, logging to /usr/local/hadoop/logs/yarn-root-nodemanager-master.out
slave1: starting nodemanager, logging to /usr/local/hadoop/logs/yarn-root-nodemanager-slave1.out
(3).jsp查看进程
[root@master sbin]# jps
3749 NameNode
564 ResourceManager
4015 SecondaryNameNode
4263 NodeManager
4365 Jps
[root@master sbin]#
(3).关闭
[root@master sbin]# ./stop-all.sh
This script is Deprecated. Instead use stop-dfs.sh and stop-yarn.sh
Stopping namenodes on [master]
master: stopping namenode
slave2: stopping datanode
slave1: stopping datanode
master: stopping datanode
Stopping secondary namenodes [0.0.0.0]
0.0.0.0: stopping secondarynamenode
stopping yarn daemons
no resourcemanager to stop
master: stopping nodemanager
slave1: stopping nodemanager
slave2: stopping nodemanager
no proxyserver to stop
[root@master sbin]#