说说你对集群概念的理解?
集群是多个服务器组成的一个群体,这些服务器做相同类型任务。好比饭店做饭一个厨师忙不过来,又请了个厨师,两个厨师都能炒一样的菜,这两个厨师的关系是集群;切菜,备菜,备料一个配菜师忙不过来,又请了个配菜师,两个配菜师关系是集群。
说说你对Hadoop的可靠、可扩展、分布式计算的理解?
因为HDFS存储的时候会有备份,所以说它可靠。
存不下的话可以用加磁盘或加机器的方式来解决,这就是存储可扩展。计算太复杂,通过加机器来加快计算速度,也是可以扩展,这也可以理解为分布式计算。
比如一大筐球分成十份让十个人来数,再把每个人计算的结果汇总起来,这就是对分布式计算的一个通俗的理解。
详细介绍Hadoop2.x 的基本架构
Hadoop2.x框架包括三个模块
hdfs:分布式文件存储系统
mapreduce:分布式计算框架
yarn:资源调度系统
hadoop2.0%E4%B8%8E1.0%E7%9B%B8%E6%AF%94%E6%9C%89%E4%BB%80%E4%B9%88%E4%B8%8D%E5%90%8C%3F" style="margin-left:0cm;">hadoop2.0与1.0相比有什么不同?
一、从Hadoop整体框架来说
Hadoop1.0即第一代Hadoop,由分布式存储系统HDFS和分布式计算框架MapReduce组成,其中HDFS由一个NameNode和多个DateNode组成,MapReduce由一个JobTracker和多个TaskTracker组成。
Hadoop2.0即第二代Hadoop为克服Hadoop1.0中的不足:
针对Hadoop1.0单NameNode制约HDFS的扩展性问题,提出HDFSFederation,它让多个NameNode分管不同的目录进而实现访问隔离和横向扩展;针对NameNode单点故障问题,提出了HA(hight availability,高可用),让两个namenode共享editlog文件存储系统以保证元数据同步,通过zkfc来实现主备切换。
针对Hadoop1.0中的MapReduce在扩展性和多框架支持等方面的不足,它将JobTracker中的资源管理和作业控制分开,分别由ResourceManager(负责所有应用程序的资源分配)和ApplicationMaster(负责管理一个应用程序)实现,即引入了资源管理框架Yarn。同时Yarn作为Hadoop2.0中的资源管理系统,它是一个通用的资源管理模块,可为各类应用程序进行资源管理和调度,不仅限于MapReduce一种框架,也可以为其他框架使用,如Tez、Spark、Storm等
MapReduce1.0计算框架主要由三部分组成:编程模型、数据处理引擎和运行时环境。
- 它的基本编程模型是将问题抽象成Map和Reduce两个阶段,其中Map阶段将输入的数据解析成key/value,迭代调用map()函数处理后,再以key/value的形式输出到本地目录,Reduce阶段将key相同的value进行规约处理,并将最终结果写到HDFS上;
- 它的数据处理引擎由MapTask和ReduceTask组成,分别负责Map阶段逻辑和Reduce阶段的逻辑处理;
- 它的运行时环境由一个JobTracker和若干个TaskTracker两类服务组成,其中JobTracker负责资源管理和所有作业的控制,TaskTracker负责接收来自JobTracker的命令并执行它。
MapReducer2.0具有与MRv1相同的编程模型和数据处理引擎,唯一不同的是运行时环境。MRv2是在MRv1基础上经加工之后,运行于资源管理框架Yarn之上的计算框架MapReduce。它的运行时环境不再由JobTracker和TaskTracker等服务组成,而是变为通用资源管理系统Yarn和作业控制进程ApplicationMaster,其中Yarn负责资源管理的调度而ApplicationMaster负责作业的管理。
HDFS的系统结构都有哪几部分组成,以及每部分的作用?

HDFS的高可用的方案有多种,最常用的是QJM。基于 QJM (Qurom Journal Manager)的共享存储系统的总体架构由namenode、datanode、journalnode、zkfc组成。
namenode是主节点,主要用于存储和更新元数据信息,处理用户的请求。
元数据就是描述数据的数据,比如块信息。一个数据块(block)包括两个文件,一个是数据本身,一个是元数据,这个元数据就是块信息。一个数据块(block) 在namenode中对应一条记录。
hdfs擅长存储大文件,因为大文件对应的元数据信息比较少。hdfs在运行时把所有的元数据都保存到namenode机器的内存中,所以整个HDFS可存储的文件数受限于namenode的内存大小。如果hadoop集群当中有大量的小文件,那么每个小文件都需要维护一份元数据信息,会大大的增加集群管理元数据的内存压力。相应的,元数据的镜像文件也会很大,会增加停机再启动的代价。所以在实际工作当中,一定要将小文件合并成大文件。
namenode中的元数据可持久化到硬盘上。一开始是生成操作日志记录文件(editlog),保存了自最后一次检查点之后所有针对HDFS文件系统的操作,比如∶增加文件、重命名文件、删除目录等等。随着editlog内容的增加,就需要在一定时间点和fsimage合并。fsimage就是HDFS文件系统存于硬盘中的元数据检查点,也是元数据的镜像,记录了自最后一次检查点之前 HDFS文件系统中所有目录和文件信息,这些信息在fsimage中是序列化的 。namenode宕机了怎么办?如果fsimage完整就直接恢复,不完整可以通过editlog来进行补余。
datanode是从节点,负责存储数据块和执行数据块的读写操作。
存储数据块:datanode存储与元数据对应的具体数据。数据块的数据本身 在Datanode中 以文件的形式存储在磁盘上。因为namenode在内存里面动态维护数据块的映射信息,所以datanode启动的时候要向namenode注册。通过注册后,Datanode周期性地向namenode上报所有的块信息。
执行数据块的读写操作:详见后面的HDFS数据的写入过程和HDFS数据的读取过程
journalnode是共享存储系统,主要用于保存 EditLog,同步元数据信息,保证两个namenode的数据是一致的,不然就会出现脑裂。journalnode并不保存 FSImage 文件,FSImage 文件还是在 NameNode 的本地磁盘上。
zkfc作用是守护进程,与namenode启动在同一台机器,监听namenode的健康状况。zkfc具有HA自动切换的功能,会将namenode的活动信息保存到zookeeper,并保证有namenode可用。具体参见 zookeeper是如何进行高可用协调的?
HDFS数据的写入过程
第一步:客户端请求namenode上传数据。
第二步:namenode校验客户端是否有写入权限,文件是否存在。如果校验通过,namenode直接告诉客户端允许上传。
第三步:客户端切分文件,并请求namenode第一个文件block块地址。
第四步:namenode寻找对应的datanode地址返回给客户端 。
寻找datanode要符合以下条件
1.就近原则
2.心跳比较活跃
3.磁盘比较空闲的
第五步:客户端直接与对应的datanode进行通信,packet为单位进行传输,packet默认是64KB,将数据写入到datanode对应的block块里面去。block块在满了之后,datanode使用反向的ack校验机制给客户端一个响应,告诉客户端第一个block块已经保存好了,这时候客户端才可以上传第二个block块。
datanode保存block的步骤
1.接收客户端数据的datanode和其他datanode互相通信,完成复制数据块的动作以保证数据的冗余性。
2.Hadoop在设计时考虑到数据的安全与高效,数据文件默认在HDFS上存放三份,存储策略为本地一份,同机架内其它某一节点上一份,不同机架的某一节点上一份。
3. 数据块保存完成后,datanode将更新信息上报给namenode,namenode也会相应地更新数据块的元数据信息。
HDFS数据的读取过程
第一步:客户端向namenode发起读取文件的请求。
第二步:namenode校验有没有文件,有没有读取权限。如果客户端可以读取,那么namenode就会查找元数据信息,找到这个文件的block块对应的datanode地址。该datanode位置离客户端最近,发送心跳的时间距客户端发起请求的时间也最近。
第三步:客户端与对应的datanode建立socket通信,并行读取block块,直到所有的block块都读取完成之后,在客户端进行block块的拼接,就成了一个完整的文件。如果block块读取到一半的时候抛错了怎么办?客户端会重新请求namenode找到出错block的副本,找副本重新读,没有断点续传的功能
关于HDFS的系统结构,更多详细内容参见:
Hadoop NameNode 高可用 (High Availability) 实现解析
hadoop2.0生产环境高可用集群原理和搭建
超详细 Hadoop2.0高可用集群搭建方案
hadoop%E6%96%87%E4%BB%B6%E7%B3%BB%E7%BB%9F%E7%9A%84%E5%B8%B8%E7%94%A8%E6%93%8D%E4%BD%9C%E5%91%BD%E4%BB%A4">hadoop文件系统的操作命令
# 在HDFs根目录创建/data目录
hadoop fs -mkdir /data
# 从本地上传1.txt到HDFS 的/data目录下
hadoop fs -put 1.txt /data
# 查看/data目录
hadoop fs -ls /data
# 查看HDFS上的1.txt 文件
hadoop fs -cat /data/1.txt
# 删除HDFs上的/data目录
hadoop fs -rm -r -skipTrash /data
# hdfs的权限管理
hdfs dfs -chmod -R 777 /xxx
hdfs dfs -chown -R hadoop:hadoop /xxxhadoop fs -rm命令加上-r 和-skipTrash各有什么作用?
没有-r就删不了目录,只能删文件;有了-r就可以递归删除目录。
-skipTrash就是直接删,不放入回收站
关于权限的介绍参见 linux的权限管理
mapreduce%E7%BC%96%E7%A8%8B%E5%8F%AF%E6%8E%A7%E7%9A%84%E5%85%AB%E4%B8%AA%E6%AD%A5%E9%AA%A4">mapreduce
mapreduce编程可控的八个步骤
map阶段两个步骤
1、第一步:读取文件,解析成key1 value1对
TextInputFormat.addInputPath(job,new Path(args[0])); //读取文件
job.setInputFormatClass(TextInputFormat.class); //设置map输入format class类型,默认是TextInputFormat.class【文本】,可以不写2、第二步:接收k1 v1,自定义map逻辑,然后转换成新的key2 value2 进行输出
job.setMapperClass(XxxMapper.class); //设置map运行类
job.setMapOutputKeyClass(Text.class); //设置reduce最终输出的key的类型
job.seMapOutputValueClass(LongWritable.class); //设置reduce最终输出的value类型shuffle阶段四个步骤
3、第三步:分区 把key2 value2打上分区号,以备发送给指定的reducer去执行,从而达到负载均衡,避免数据倾斜
job.setPartitionerClass(PartitionOwn.class); //设置分区类
//一定设置我们 reducetask的数量,不设置不好使
//如果reducetask的数量比分区的数量多,那么就会有空文件
//如果reducetask的数量比分区的个数少,那么就会有些reduce里面要处理更多的数据
job.setNumReduceTasks(2);4、第四步:排序 默认按照字段顺序进行排序
5、第五步:规约 对分组后的数据进行规约(combine操作),降低数据的网络拷贝,其输出键值对的类型和map类的输出类型一致
job.setCombinerClass(XxxCombiner.class); //手动指定具体执行combiner的类6、第六步:分组 对排序后的的数据进行分组,分组的过程中,将相同key的value放到一个集合当中
reduce阶段两个步骤
7、第七步:接收k2 v2 自定义reduce逻辑,转换成新的k3 v3
job.setReducerClass(XxxReducer.class); //自定义reduce逻辑
job.setOutputKeyClass(Text.class); //设置reduce最终输出的key的类型
job.setOutputValueClass(NullWritable.class); //设置reduce最终输出的value类型8、第八步:输出K3 v3
FileOutputFormat.setOutputPath(job, new Path(args[1])); //设置任务的输出目录如何开发mr的代码?
上面八个步骤,每一个步骤都是一个单独的java类
八个步骤写完了之后,通过job任务组装我们的mr的程序,进行任务的提交
maptask的运行机制、reducetask的运行机制以及shuffle过程
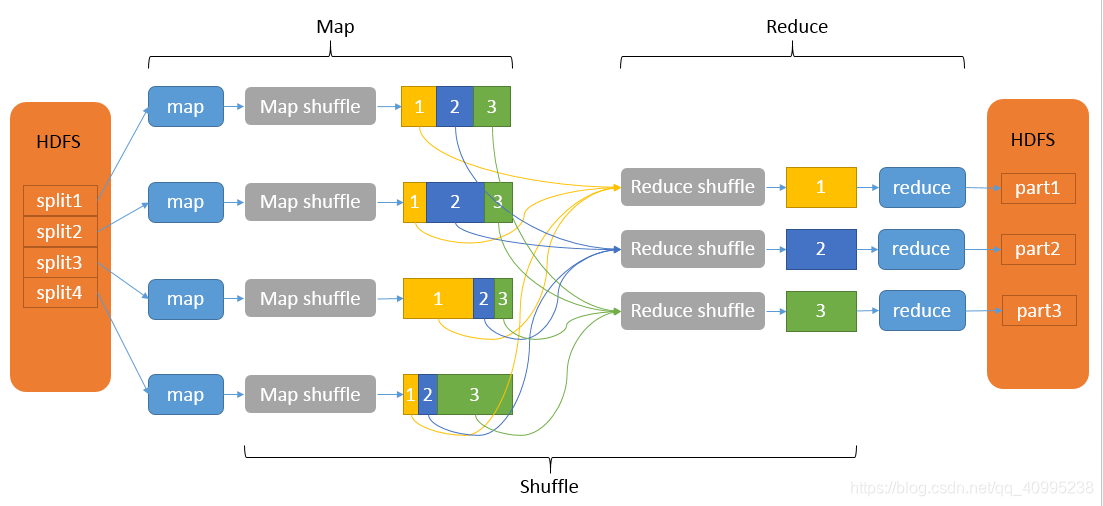
map: inputsplit->read->map->mapbuff-->(partition->sort->combiner)->spill-> sort->combiner->mergepartitionfile;
在文件被读入的时候调用的是Inputformat方法。Hadoop 将 MapReduce 的输入数据划分成等长的小数据块,不能超过block的大小(block默认大小为128M)。这种小数据块称为 inputsplit(输入分片 或 分片) 。然后分片被一行一行地读入,返回的是(k,v)的形式,key是行号的偏移量,value是这一行的内容。
读入之后调用map方法(用户可自定义该方法),将以上内容转换成新的键值对,也就是map方法输出的中间结果。
将中间结果写入到环形内存缓冲区中。
以下是map阶段的shuffle过程---------------------------------------------------------------
每个 map 任务都有一个环形内存缓冲区用于存储任务输出,默认大小是100M。一旦缓冲区内容达到阈值(默认0.8),一个后台线程(spill <溢写>线程)便开始把内容写入到磁盘。在将数据写到磁盘文件的过程中,会对数据进行分区和排序。分区的目的是把map任务处理的结果打上分区号,以备发送给指定的reducer去执行,从而达到负载均衡,避免数据倾斜。各个分区(文件)中的数据将按照key进行排序。
在写入磁盘的同时,map输出继续写到缓冲区,但如果在此期间缓冲区被填满,map 会被阻塞直到写磁盘过程完成。每次内存缓冲区达到溢出阈值时,就会新建一个溢出文件(spill file),因此在 map 任务写完其最后一个输出记录之 后,就会有多个溢出文件。
如果指定了规约(Combiner),可能在两个地方被调用:
1.当为作业设置Combiner类后,缓存溢出线程将缓存存放到磁盘时,就会调用;
2.缓存溢出的数量(即spill文件数目)超过规定(默认3)时,在缓存溢出文件合并的时候会调用。
规约(Combine)和分组(Merge)的区别:两个键值对<"a",1>和<"a",1>,如果规约,会得到<"a",2>,如果分组,会得到<"a",<1,1>>
当一个map task处理的数据很大,以至于超过缓冲区内存时,就会生成多个spill文件。此时就需要对同一个map任务产生的多个spill文件进行分组生成最终的一个已分区已排序的大文件。这个过程包括排序和规约(可选)。
溢出写文件分组完毕后,Map将删除所有的临时溢出写文件,并告知NodeManager任务已完成,只要其中一个MapTask完成,ReduceTask就开始复制它的输出(Copy阶段分区输出文件通过http的方式提供给reducer)
写磁盘时压缩map端的输出会让写磁盘的速度更快,节约磁盘空间,并减少传给reducer的数据量。默认情况下,输出是不压缩的。
reducer:copy->copybuff->merger(内存)->merge and sort->reducer->output
reducer中是有分区号的,在reduce阶段会按照相同的分区通过http的方式拖取map阶段的输出文件数据,将数据复制到内存缓存区中。当内存缓存区中存储的map数据占用空间达到一定程度的时候,开始启动内存中的合并操作,把合并文件输出到本地磁盘中。取完数据之后会按照相同的分区,然后将取过来的数据按照key有序进行排序,之后会调用groupingcomparator进行分组。
以上是ruduce阶段的shuffle过程---------------------------------------------------------------
之后的reduce中会按照这个分组,每次取出一组数据,调用reduce中自定义的方法进行处理。
最后调用outputformat会将内容写入到文件中。