实现MySQL-->HDFS;MySQL-->Hive;Hive-->HDFS;HDFS-->MySQL的数据迁移
一. Apache Sqoop介绍
- Apache Sqoop是在Hadoop生态体系和RDBMS体系之间传送数据的一种工具。来自于Apache软件基金会提供。
- Sqoop工作机制是将导入或导出命令翻译成mapreduce程序来实现。在翻译出的mapreduce中主要是对inputformat和outputformat进行定制。
- Hadoop生态系统包括:HDFS、Hive、Hbase等
RDBMS体系包括:MySql、Oracle、DB2等 - Sqoop可以理解为:“SQL 到 Hadoop 和 Hadoop 到SQL”。


站在Apache立场看待数据流转问题,可以分为数据的导入导出:
Import:数据导入。RDBMS----->Hadoop
Export:数据导出。Hadoop---->RDBMS
二.Sqoop安装
2.1安装Sqoop
当前系统环境
1. hadoop-2.7.5
2. jdk1.8.0_141(node03)
3. apache-hive-2.1.1-bin
4. MySql(node03)

2.2解压Sqoop
cd /export/softwares
tar -zxvf sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz -C ../servers/
cd /export/servers/
ls

2.3配置Sqoop
cd /export/servers/sqoop-1.4.6.bin__hadoop-2.0.4-alpha/conf
cp sqoop-env-template.sh sqoop-env.sh
vim sqoop-env.sh
export HADOOP_COMMON_HOME=/export/servers/hadoop-2.7.5
export HADOOP_MAPRED_HOME=/export/servers/hadoop-2.7.5

sql>mysqljdbc_50">2.4.加入sql>mysql的jdbc驱动包
cp /export/servers/apache-hive-2.1.1-bin/lib/sql>mysql-connector-java-5.1.38.jar /export/servers/sqoop-1.4.6.bin__hadoop-2.0.4-alpha/lib/
ll /export/servers/sqoop-1.4.6.bin__hadoop-2.0.4-alpha/lib/sql>mysql-connector-java-5.1.38.jar

2.5. 设置ACCUMULO_HOME环境变量
mkdir -p /export/servers/sqoop-1.4.6.bin__hadoop-2.0.4-alpha/tmp/accumulo
mkdir -p /export/servers/sqoop-1.4.6.bin__hadoop-2.0.4-alpha/tmp/hcat
vim /etc/profile
export ACCUMULO_HOME=/export/servers/sqoop-1.4.6.bin__hadoop-2.0.4-alpha/tmp/accumulo
export HCAT_HOME=/export/servers/sqoop-1.4.6.bin__hadoop-2.0.4-alpha/tmp/hcat

source /etc/profile
2.5. 验证启动,显示版本号
cd /export/servers/sqoop-1.4.6.bin__hadoop-2.0.4-alpha
bin/sqoop-version

2.6.显示MySQL中的数据库
#启动MySQL
/etc/init.d/sql>mysqld start
#本命令会列出所有sql>mysql的数据库。
cd /export/servers/sqoop-1.4.6.bin__hadoop-2.0.4-alpha
bin/sqoop list-databases --connect jdbc:sql>mysql://localhost:3306/ \
--username root --password 123456

三.Sqoop导入
3.1. 加载测试数据到MySQL(创建表)


3.2. 全量导入MySQL表数据到HDFS
cd /export/servers/sqoop-1.4.6.bin__hadoop-2.0.4-alpha
bin/sqoop import \
--connect jdbc:sql>mysql://node03:3306/dress \ #刚创建数据库名字
--username root \ #用户名
--password 123456 \ #密码
--delete-target-dir \
--target-dir /sqoopdressresult \
--fields-terminated-by '\t' \
--table dress_customer \
--m 1
#--target-dir用来指定导出数据存放至HDFS的目录,此目录事先不能存在
#--fields-terminated-by '\t' \ #分隔符为 /t
#--m 1 #并行度为1

查看导入结果
hdfs dfs -cat /sqoopdressresult/part-m-00000

并行度参数–m测试
cd /export/servers/sqoop-1.4.6.bin__hadoop-2.0.4-alpha
bin/sqoop import \
--connect jdbc:sql>mysql://node03:3306/dress \
--username root \
--password 123456 \
--delete-target-dir \
--target-dir /sqoopdressresult2 \
--fields-terminated-by '\t' \
--split-by identity \
--table dress_customer \
--m 2
#--m 2 #并行度为2
#--split-by identity \ #按照 identity 字段进行拆分
查看结果
hdfs dfs -cat /sqoopdressresult2/part-m-00000
hdfs dfs -cat /sqoopdressresult2/part-m-00001
hdfs dfs -cat /sqoopdressresult2/part-m-00002
hdfs dfs -cat /sqoopdressresult2/part-m-00003

3.3.全量导入MySQL表数据到HIVE
将关系型数据的表结构复制到hive中
create database if not exists dress;
use dress;
show tables;

cd /export/servers/sqoop-1.4.6.bin__hadoop-2.0.4-alpha
bin/sqoop create-hive-table \
--connect jdbc:sql>mysql://node03:3306/dress \
--table dress_customer \
--username root \
--password 123456 \
--hive-table dress.dress_customer_sp
# --table dress_customer为sql>mysql中的数据库dress中的表。
# --hive-table dress_customer_sp 为hive中新建的表名称。

desc formatted dress_customer_sp;

cd /export/servers/sqoop-1.4.6.bin__hadoop-2.0.4-alpha
bin/sqoop import \
--connect jdbc:sql>mysql://node03:3306/dress \
--username root \
--password 123456 \
--table dress_customer \
--hive-table dress.dress_customer_sp \
--hive-import \
--m 1

use dress;
select * from dress_customer_sp;

四.Sqoop导出
4.1.模块开发–数据导出

4.2. Sqoop 导出项目数据
将数据从Hadoop生态体系导出到RDBMS数据库导出前,目标表必须存在于目标数据库中。
export有三种模式:
默认模式:是从将文件中的数据使用INSERT语句插入到表中。
更新模式:Sqoop将生成UPDATE替换数据库中现有记录的语句。
调用模式:Sqoop将为每条记录创建一个存储过程调用。
- Sqoop支持直接从Hive表到RDBMS表的导出操作,也支持HDFS到RDBMS表的操作,鉴于此,有如下两种方案:
- 从Hive表到RDBMS表的直接导出:
效率较高,相当于直接在Hive表与RDBMS表的进行数据更新,但无法做精细的控制。 - 从Hive到HDFS再到RDBMS表的导出:
需要先将数据从Hive表导出到HDFS,再从HDFS将数据导入到RDBMS。虽然比直接导出多了一步操作,但是可以实现对数据的更精准的操作,特别是在从Hive表导出到HDFS时,可以进一步对数据进行字段筛选、字段加工、数据过滤操作, 从而使得HDFS上的数据更“接近”或等于将来实际要导入RDBMS表的数据,提高导出速度。
4.3.Hive–>HDFS
导出dress_customer_sp表数据到HDFS
insert overwrite directory '/dress/export/dress_customer_hdfs'
row format delimited fields terminated by '\001' STORED AS textfile
select custname,identity,sex,college,phone,custype,createtime from dress_customer_sp;
# /dress/export/dress_customer_hdfs 为导入HDFS的目录
# select custname,identity,sex,college,phone,custype,createtime from dress_customer_sp; 可以根据自己的需求对数据进入筛选(SQl语句)


查看

sql_248">4.4.HDFS–>Mysql
先创建目标表 dress_customer_hdfs
cd /export/servers/sqoop-1.4.6.bin__hadoop-2.0.4-alpha
bin/sqoop export \
--connect jdbc:sql>mysql://192.168.174.120:3306/dress \
--username root --password 123456 \
--table dress_customer_hdfs \
--fields-terminated-by '\001' \
--columns custname,identity,sex,college,phone,custype,createtime \
--export-dir /dress/export/dress_customer_hdfs
# --table dress_customer_hdfs 表示你要导入的目标表
# columns custname,identity,sex,college,phone,custype,createtime
表的字段
# --export-dir /dress/export/dress_customer_hdfs 表示你要导的HDFS源文件目录
导入成功

查看数据库中dress_customer_hdfs表(可能中文显示为??)

修改sql>mysql的编码格式配置
#查看编码格式
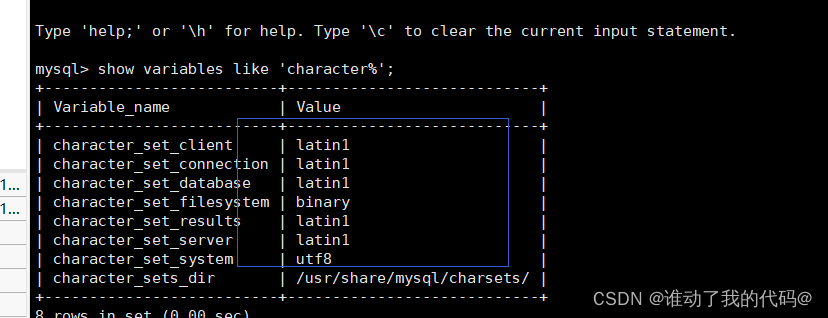
show variables like 'character%';
vim /etc/my.cnf
#在[sql>mysqld]上面加入下面几句话
[client]
default-character-set=utf8
在[sql>mysqld]最下面加入下面几句话
default-storage-engine=INNODB
character-set-server=utf8
collation-server=utf8_general_ci
重启MySQL
#centos6
service sql>mysql restart
#centos7
systemctl restart sql>mysqld


