目录
- 1.安装jdk
- 2.下载Hadoop
- 3.设置Hadoop环境变量
- 4.Hadoop配置文件设置
- 5.创建并格式化 hdfs目录
- 6.关闭防火墙
- 7.启动Hadoop
- 8.打开Hadoop web界面
1.安装jdk
步骤1:
启动终端:使用快捷键 Ctrl+Alt+T启动。也可以单击快捷工具栏的“终端”程序图标来启动。
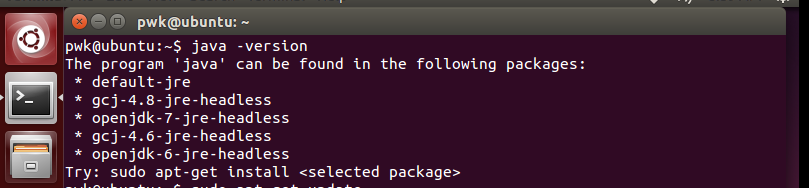
步骤2:查看java当前版本
java -version
为了获得最新软件包,首先进行更新
sudo apt-get update
下载和安装jdk
sudo apt-get install default-jdk
安装完成后重新查看版本
java -version
运行结果

2.下载Hadoop
有的同学用的安装教程版本比较旧,但是一些旧版本的Hadoop版本不知道从哪里下载,下面给大家一个网址,可以随意的选择自己想要的版本。
https://archive.apache.org/dist/hadoop/common/

1.下载
window系统用习惯了,不知道linux中怎么下载,简单,直接上命令,我安装的时候就用的是Hadoop2.6.4版本,所以这里以2.6.4为例:
wget https://archive.apache.org/dist/hadoop/common/hadoop-2.6.4/hadoop2.6.4.tar.gz
2.解压Hadoop
sudo tar -zxvf hadoop-2.6.4.tar.gz

3.将Hadoop移动到/usr/local
sudo mv hadoop-2.6.4 /usr/local/hadoop

3.设置Hadoop环境变量
运行Hadoop必须设置很多环境变量,可是如果每次登陆时都必须重新设置一次就会很麻烦,因此我们可以在~/.bashrc 文件中设置每次登陆时都会自动运行一次环境变量设置。
1.编辑 ~/.bashrc
终端输入命令:
sudo gedit ~/.bashrc
然后回车键,输入下面内容:

2.设置路径:
》1.设置jdk路径
》2.设置HADOOP_HOME为Hadoop安装路径
》3.设置Hadoop其他环境变量

3.让~/.bashrc设置生效
source ~/bashrc
运行结果见上图。
4.Hadoop配置文件设置
接下来就是Hadoop配置设置,包括 Hadoop-env.sh,core-site.xml,YARN-site.xml。
1.设置Hadoop-env.sh 配置文件
1.编辑Hadoop-env.sh
sudo gedit /usr/local/hadoop/hadoop-env.sh

原本文件中JAVA_HOME的设置为:
export JAVA_HOME=${JAVA_HOME}
修改后
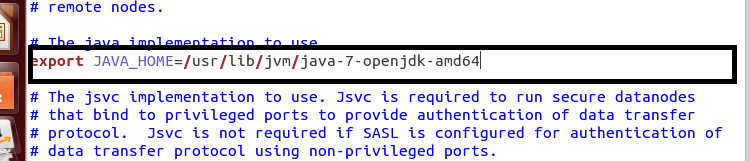
注意:先保存,再关闭gedit。
2.设置core-site.xml
修改core-site.xml
sudo gedit /usr/local/hadoop/etc/hadoop/core-site.xml

编辑后:

先保存,再关闭gedit。
3.设置YARN-site.xml
YARN-site.xml文件中含有MapReduce2相关配置设置,可在终端程序中输入以下命令:
sudo gedit /usr/local/hadoop/etc/hadoop/yarn-site.xml

编辑文件

先保存,再关闭gedit。
4.设置mapred-site.xml
mapred-site,xml 用于监控map和reduce程序的JobTracker任务分配情况以及T爱上Tracker任务运行情况,Hadoop提供设置模板,可自行复制修改,在终端程序中输入以下命令
复制模板文件,由mapred-site.xml.template至mapred-site.xml
sudo cp /usr/local/hadoop/etc/hadoop/mapred-site.xml.template /usr/local/hadoop/mapred-site.xml

模板复制成功,接下来继续编辑mapred-site.xml
sudo gedit /usr/local/hadoop/etc/hadoop/mapred-site.xml

编辑

先保存,在关闭geidit。
5.设置hdfs-site.xml
hdfs-site.xml用于设置HDFS分布式文件系统,在终端程序中输入以下命令:
sudo gedit /usr/local/hadoop/etc/hadoop/hdfs-site.xml

编辑

先保存,再关闭gedit。
(不写蓝色部分会出现错误,有些书上面没有,大家注意!如果对错误感兴趣,可以看博客:https://blog.csdn.net/qq_44176343/article/details/109564129)
hdfs_135">5.创建并格式化 hdfs目录
1.创建namenode数据存储目录:
sudo mkdir -p /usr/local/hadoop/hadoop_data/hdfs/namenode
2.创建datanode数据存储目录:
sudo mkdir -p /usr/local/hadoop/hadoop_data/hdfs/datanode
3.将Hadoop目录所有者改为hduser
sudo chown hduser:hduser -R /usr/local/hadoop

6.关闭防火墙
1.切换到root用户
su
2.关闭防火墙
sudo ufw disable

2.格式化HDFS
hadoop namenode -format

7.启动Hadoop
启动Hadoop可以分为分为两种,一种是分别启动HDFS,YARN.一种是同时启动HDFS,YARN.
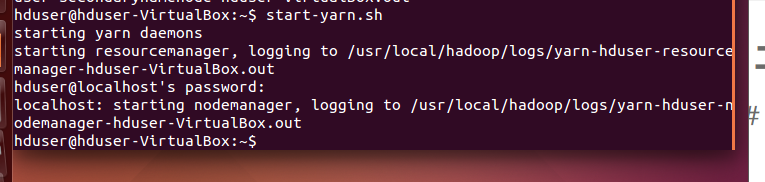
1.分别启动
start-hdfs.sh

start-yarn.sh
2.同时启动
start-all.sh
同上。
3.查看NameNode和DataNode是否启动
jps

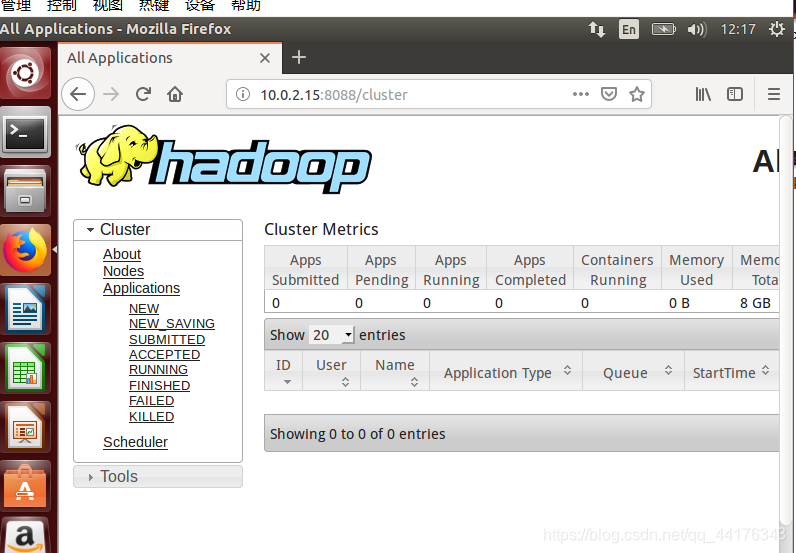
8.打开Hadoop web界面
1.打开Hadoop resourcemanager web界面用于查看Hadoop状态:node节点,应用程序和运行状态。
步骤1:打开浏览器Firefox,在网址中输入:
http://localhost:8088/
2.打开HDFS web 界面可以检查HDFS与DataNode的运行情况
步骤1:打开浏览器Firefox,在网址中输入:
http://localhost:50070/

注意:如果界面不显示,可以先用ifconfig查询一下网络
ifconfig

发现ip地址为:10.0.2.15.则在浏览器输入
http://10.0.2.15:8088/
欢迎大家评论,互相讨论问题。