目录
hadoop%E3%80%91-toc" style="margin-left:0px;">01【hadoop】
1.1【编写集群分发脚本xsync】
1.2【集群部署规划】
1.3【Hadoop集群启停脚本】
02【HDFS】
2.1【HDFS的API操作】
MapReduce%E3%80%91-toc" style="margin-left:0px;">03【MapReduce】
3.1【P077- WordCount案例】
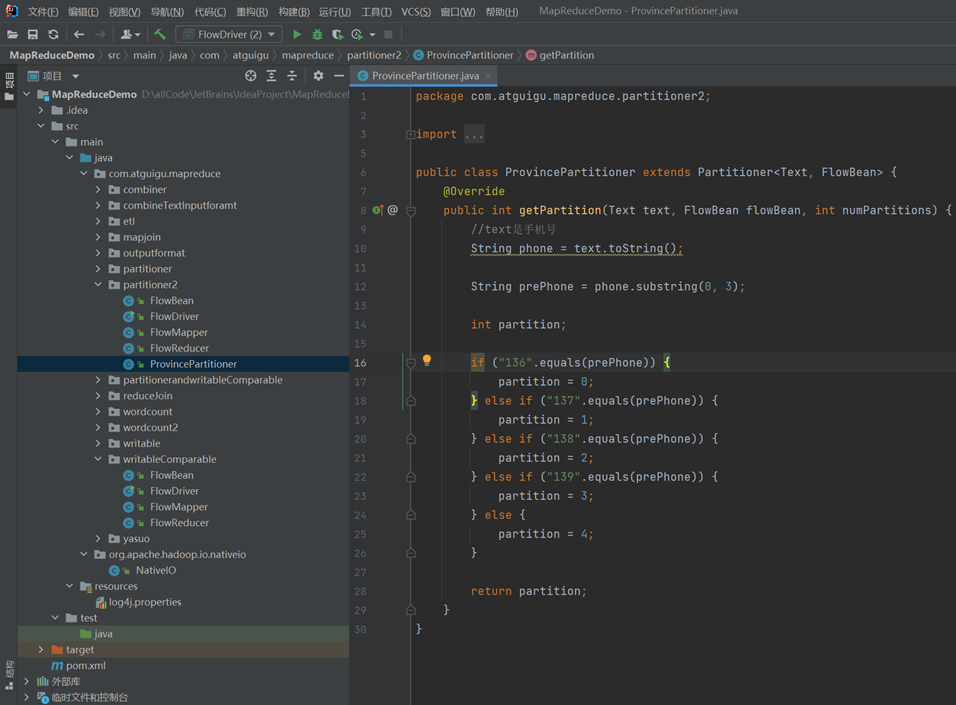
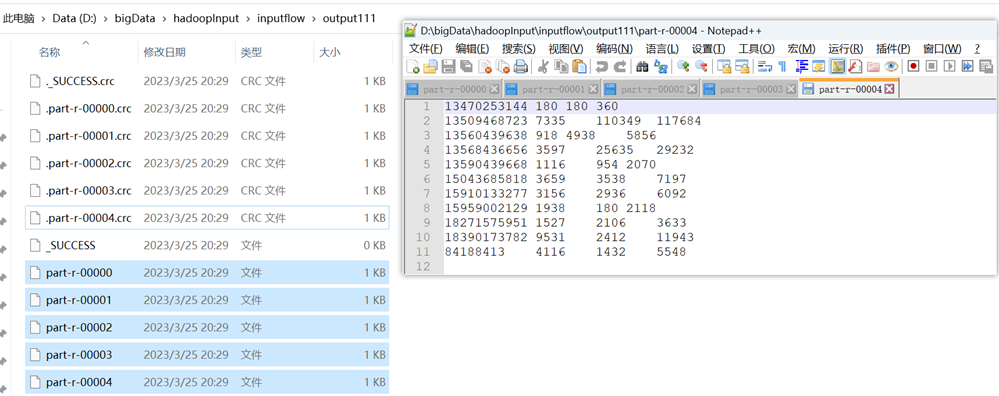
3.2【P097-自定义分区案例】
历史总结
01【hadoop】
1.1【编写集群分发脚本xsync】
1)scp(secure copy)安全拷贝
scp可以实现服务器与服务器之间的数据拷贝(from server1 to server2)。
2)rsync远程同步工具
rsync主要用于备份和镜像。具有速度快、避免复制相同内容和支持符号链接的优点。
3)xsync集群分发脚本
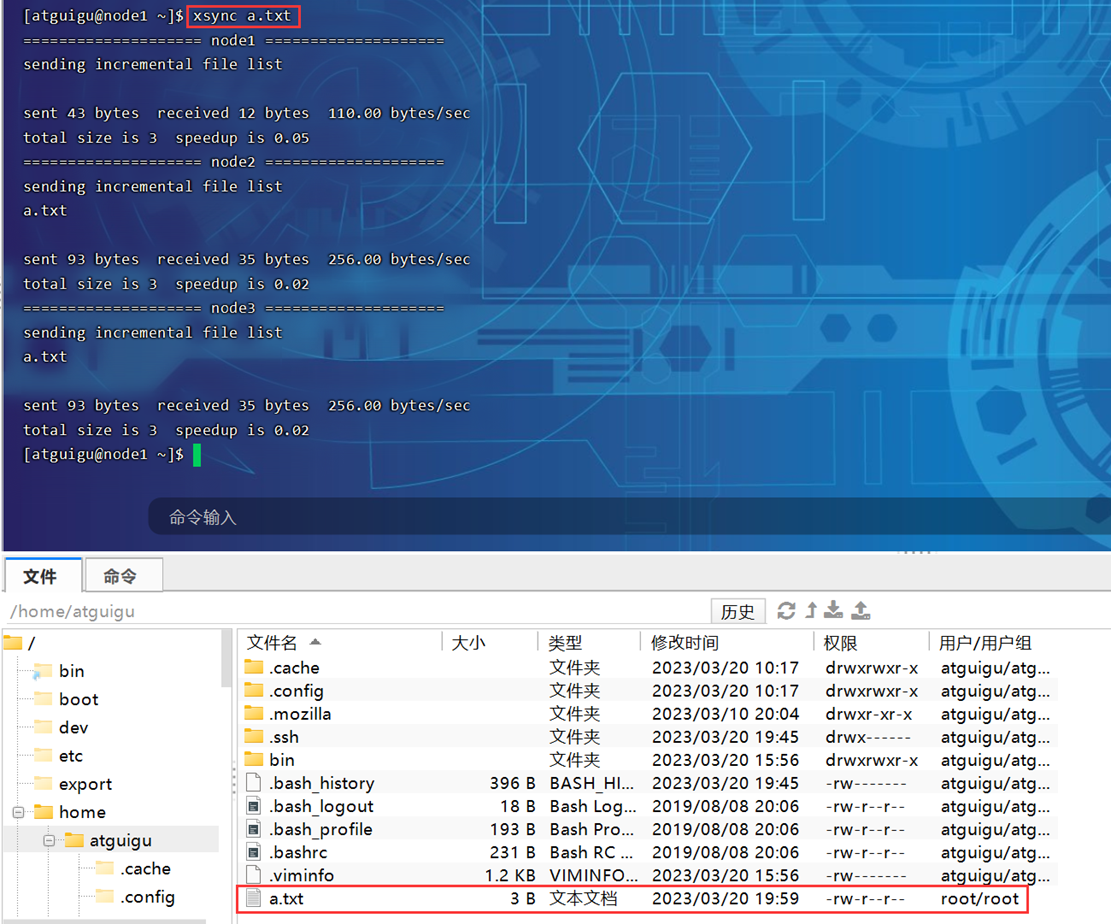
#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2. 遍历集群所有机器
for host in hadoop102 hadoop103 hadoop104
do
echo ==================== $host ====================
#3. 遍历所有目录,挨个发送
for file in $@
do
#4. 判断文件是否存在
if [ -e $file ]
then
#5. 获取父目录
pdir=$(cd -P $(dirname $file); pwd)
#6. 获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done
[atguigu@hadoop102 .ssh]$ ssh-copy-id hadoop102
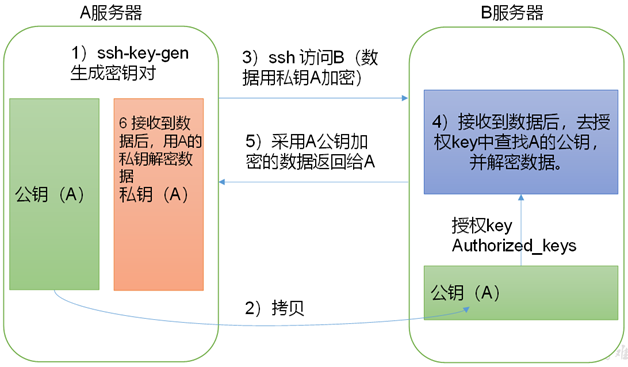
1.2【集群部署规划】
注意:
- NameNode和SecondaryNameNode不要安装在同一台服务器
- ResourceManager也很消耗内存,不要和NameNode、SecondaryNameNode配置在同一台机器上。
hadoop102
hadoop103
hadoop104
HDFS
NameNode
DataNode
DataNode
SecondaryNameNode
DataNode
YARN
NodeManager
ResourceManager
NodeManager
NodeManager
core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml等四个配置文件存放在$HADOOP_HOME/etc/hadoop这个路径上,用户可以根据项目需求重新进行修改配置。
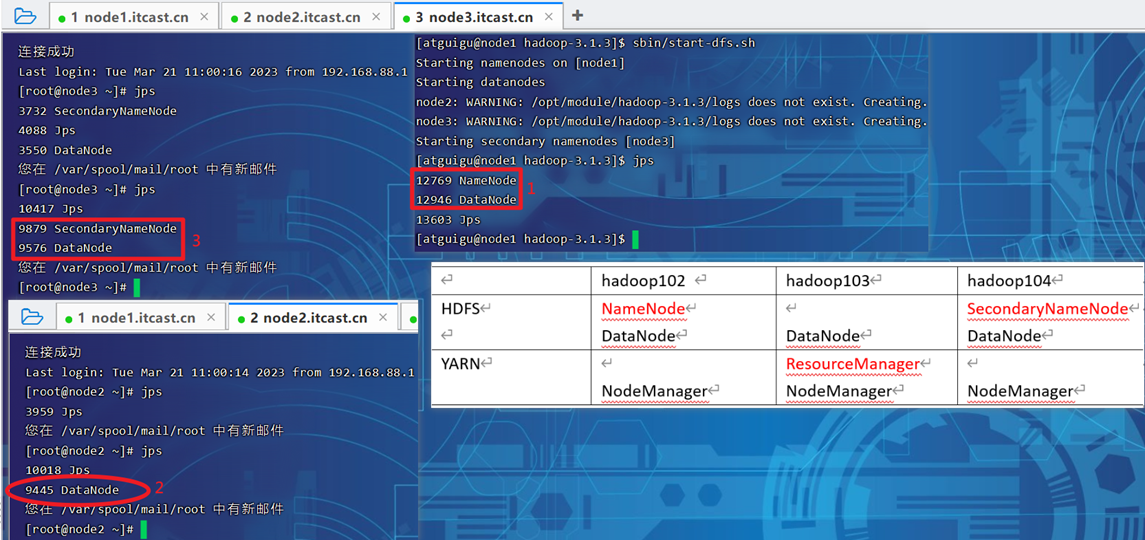
1.3【Hadoop集群启停脚本】
1)Hadoop集群启停脚本(包含HDFS,Yarn,Historyserver):myhadoop.sh

#!/bin/bash
if [ $# -lt 1 ]
then
echo "No Args Input..."
exit ;
fi
case $1 in
"start")
echo " =================== 启动 hadoop集群 ==================="
echo " --------------- 启动 hdfs ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/start-dfs.sh"
echo " --------------- 启动 yarn ---------------"
ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/start-yarn.sh"
echo " --------------- 启动 historyserver ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon start historyserver"
;;
"stop")
echo " =================== 关闭 hadoop集群 ==================="
echo " --------------- 关闭 historyserver ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon stop historyserver"
echo " --------------- 关闭 yarn ---------------"
ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/stop-yarn.sh"
echo " --------------- 关闭 hdfs ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/stop-dfs.sh"
;;
*)
echo "Input Args Error..."
;;
esac2)查看三台服务器Java进程脚本:jpsall
#!/bin/bash
for host in hadoop102 hadoop103 hadoop104
do
echo =============== $host ===============
ssh $host jps
done02【HDFS】
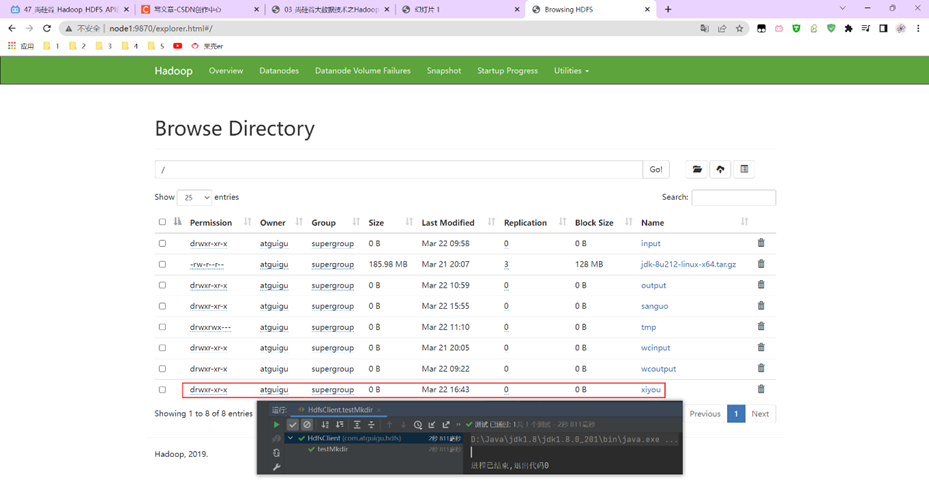
2.1【HDFS的API操作】
练习内容:
- HDFS文件上传(测试参数优先级)
- HDFS文件下载
- HDFS文件更名和移动
- HDFS删除文件和目录
- HDFS文件详情查看
- HDFS文件和文件夹判断
MapReduce%E3%80%91" style="margin-left:0;text-align:justify;">03【MapReduce】
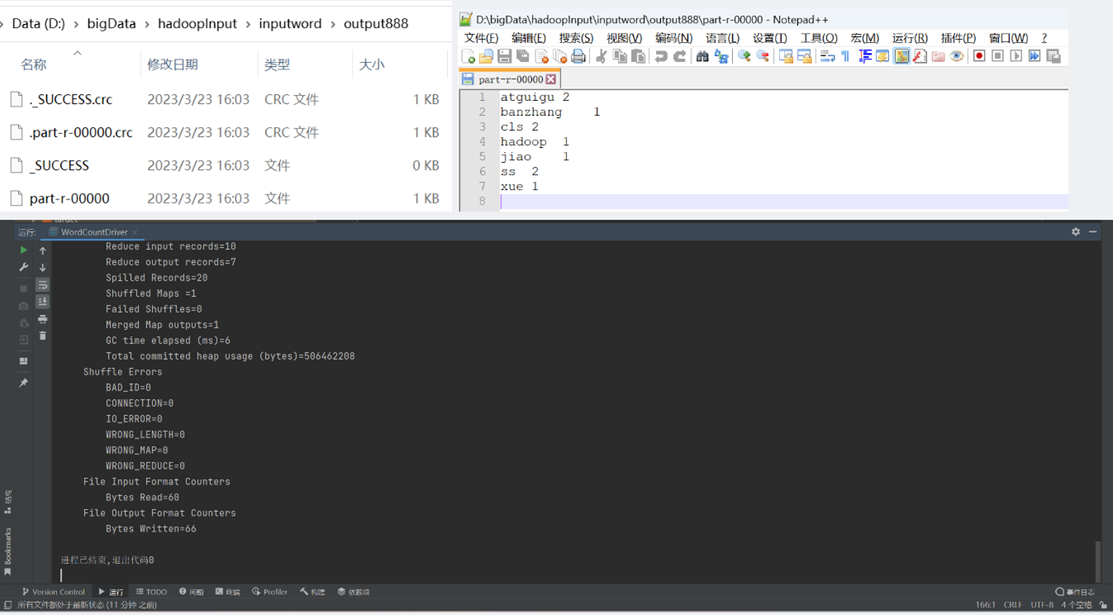
3.1【P077- WordCount案例】
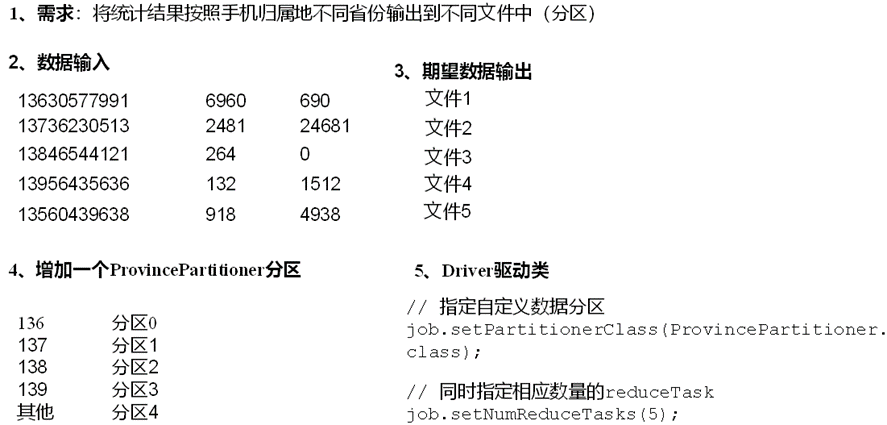
3.2【P097-自定义分区案例】
历史总结
高考项目 医疗项目
存储2泽卢、调度lnz、计算2
MySQL同步到es集群,动态更新、数据同步、集群
MySQL和es集群同步数据库
大数据平台组件 本地搭建
spark
scala
面试手册 八股文
采集 maxwell
datax
flume
zookepeer
hdfs hadoop三大组件之一
hive hbase
hudi
doris
mr spark flink
青城在线
800 1800 2000
no搭框架,这是运维搞的事情。
研究具体应用和底层原理代码。
练手:简易rpc框架。原方案:flume采集日志文件传到kafka,尚硅谷数仓项目。
现方案:Linux虚拟机rocketMQ监控logstash数据日志。
logstash -f /opt/module/logstash-8.5.1/config/test/mysql01.conf
logstash -f ../config/gaokao/mysql.conf
详细列出所学内容,xxx框架。
doris、flink、spark streaming
jieba分词器
汇报人:xxx、项目组:大数据linux集成es
canal
P25 25、基于canal数据同步的介绍 01:46
https://www.bilibili.com/video/BV1Jq4y1w7Bc?p=25
https://help.aliyun.com/document_detail/307064.html
https://github.com/alibaba/canal
https://github.com/alibaba/canal/wiki/Canal-Kafka-RocketMQ-QuickStart
2、数据存储
elk接入实时日志
1、大学专业等导入es
2、mysql-es 全量-增量,更新机制并实现
3、数据检索
1、数据治理
1.1、招生计划治理,spark实现,存es
1.2、高考数据实时日志计算统计指标梳理并统计kafka日志、kafka可视化!
极光:https://www.jiguang.cn/
https://cgsss.com/