Failed to add storage directory [DISK]file
- hadoop启动后缺少DataNode进程
- 报错out文件
- 报错log文件
- 解决
hadoopDataNode_4">hadoop启动后缺少DataNode进程
jps查看hadoop进程缺少DataNode的进程
报错out文件
查看DataNode的out日志
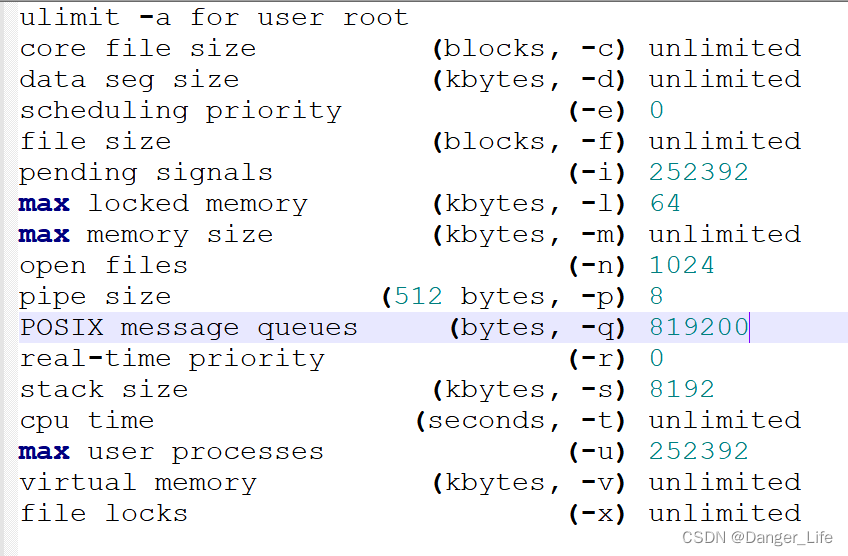
DataNode启动报错
ulimit -a for user root
core file size (blocks, -c) unlimited
data seg size (kbytes, -d) unlimited
scheduling priority (-e) 0
file size (blocks, -f) unlimited
pending signals (-i) 252392
max locked memory (kbytes, -l) 64
max memory size (kbytes, -m) unlimited
open files (-n) 1024
pipe size (512 bytes, -p) 8
POSIX message queues (bytes, -q) 819200
real-time priority (-r) 0
stack size (kbytes, -s) 8192
cpu time (seconds, -t) unlimited
max user processes (-u) 252392
virtual memory (kbytes, -v) unlimited
file locks (-x) unlimited
报错log文件
此时就去查看DataNode的log日志
2023-05-23 20:02:23,308 INFO org.apache.hadoop.hdfs.server.common.Storage: Lock on /home/software/hadoop/hadoop-2.7.7/dfs/data/in_use.lock acquired by nodename 24183@iZa3y01l4cd5oebwfuvt8qZ
2023-05-23 20:02:23,309 WARN org.apache.hadoop.hdfs.server.common.Storage: Failed to add storage directory [DISK]file:/home/software/hadoop/hadoop-2.7.7/dfs/data/
java.io.IOException: Incompatible clusterIDs in /home/software/hadoop/hadoop-2.7.7/dfs/data: namenode clusterID = CID-6655f7bc-1809-4f17-8a9c-01209e95723d; datanode clusterID = CID-2035db24-3c8f-4de1-ab08-d714abeb65e4
at org.apache.hadoop.hdfs.server.datanode.DataStorage.doTransition(DataStorage.java:775)
at org.apache.hadoop.hdfs.server.datanode.DataStorage.loadStorageDirectory(DataStorage.java:300)
at org.apache.hadoop.hdfs.server.datanode.DataStorage.loadDataStorage(DataStorage.java:416)
at org.apache.hadoop.hdfs.server.datanode.DataStorage.addStorageLocations(DataStorage.java:395)
at org.apache.hadoop.hdfs.server.datanode.DataStorage.recoverTransitionRead(DataStorage.java:573)
at org.apache.hadoop.hdfs.server.datanode.DataNode.initStorage(DataNode.java:1393)
at org.apache.hadoop.hdfs.server.datanode.DataNode.initBlockPool(DataNode.java:1358)
at org.apache.hadoop.hdfs.server.datanode.BPOfferService.verifyAndSetNamespaceInfo(BPOfferService.java:313)
at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.connectToNNAndHandshake(BPServiceActor.java:216)
at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.run(BPServiceActor.java:637)
at java.lang.Thread.run(Thread.java:748)
2023-05-23 20:02:23,311 FATAL org.apache.hadoop.hdfs.server.datanode.DataNode: Initialization failed for Block pool <registering> (Datanode Uuid unassigned) service to myuser/127.2.2.1:8020. Exiting.
java.io.IOException: All specified directories are failed to load.
at org.apache.hadoop.hdfs.server.datanode.DataStorage.recoverTransitionRead(DataStorage.java:574)
解决
可以看出来这里有
Lock on /home/software/hadoop/hadoop-2.7.7/dfs/data/in_use.lock acquired by nodename的字样
这个问题主要是因为多次的format有某一个出现了问题
我的文件目录是:/home/software/hadoop/hadoop-2.7.7/dfs/
所以我**清空了dfs下的data** 的数据
所以我**清空了dfs下的name** 的数据
重新format即可:hadoop namenode -format
此时重启hadoop即可