目录
1.拉取centos镜像
hadoopbase%E9%95%9C%E5%83%8F)-toc" style="margin-left:0px;">2.基础镜像配置(基于centos构建hadoopbase镜像)
3.集群环境配置
1.创建3个容器
2.配置网络
3.配置主机和ip的映射关系
4.配置3个节点的免密登录
hadoop%E9%9B%86%E7%BE%A4-toc" style="margin-left:0px;">4.搭建hadoop集群
hadoop-toc" style="margin-left:40px;">1.安装hadoop
2.修改配置文件
3.分发Hadoop及配置文件my_env.sh
5.启动集群
集群规划:


常用命令:
查看当前存在的 Docker 容器:docker ps -a
查看当前存在的 Docker 镜像:docker images
删除 Docker 容器:docker rm [容器ID或名称]
删除 Docker 镜像:docker rmi [镜像ID或名称]
关闭已经启动的 Docker 容器:docker stop [容器ID或名称]
前期准备,安装pipework和网桥
安装pipework:
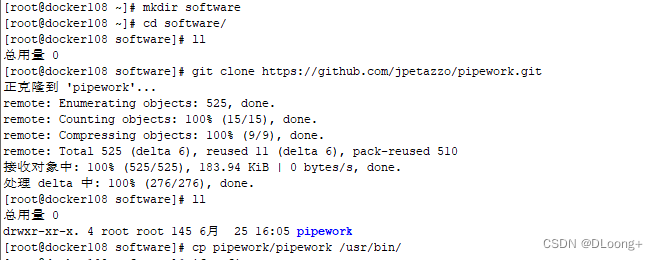
安装网桥:yum install -y bridge-utils
1.拉取centos镜像
输入命令:docker pull centos:7.5.1804

hadoopbase%E9%95%9C%E5%83%8F)">2.基础镜像配置(基于centos构建hadoopbase镜像)

2.上传jdk安装包
在文件夹下创建Dockerfile文件
并将配置粘贴进去
FROM centos:7.5.1804
#安装JDK
RUN mkdir -p /opt/software && mkdir -p /opt/service
ADD jdk-8u311-linux-x64.tar.gz /opt/service
#安装语言包
RUN yum -y install kde-l10n-Chinese glibc-common vim
RUN localedef -c -f UTF-8 -i zh_CN zh_CN.utf8
RUN echo "LANG=zh_CN.UTF-8" >>/etc/locale.conf
#解决login环境变量失效问题
RUN touch /etc/profile.d/my_env.sh
RUN echo -e "export LC_ALL=zh_CN.UTF-8\nexport JAVA_HOME=/opt/service/jdk1.8.0_311\nexport PATH=\$PATH:\$JAVA_HOME/bin" >>/etc/profile.d/my_env.sh
#安装ssh服务
#更换国内阿里云yum源
RUN curl -o /etc/yum.repos.d/Centos-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
RUN sed -i -e '/mirrors.cloud.aliyuncs.com/d' -e '/mirrors.aliyuncs.com/d' /etc/yum.repos.d/Centos-Base.repo
RUN yum makecache
#安装sshd
RUN yum install -y openssh-server openssh-clients vim net-tools lrzsz
RUN sed -i '/^HostKey/'d /etc/ssh/sshd_config
RUN echo 'HostKey /etc/ssh/ssh_host_rsa_key'>>/etc/ssh/sshd_config
#生成 ssh-key
RUN ssh-keygen -t rsa -b 2048 -f /etc/ssh/ssh_host_rsa_key
#更改root用户名登陆密码为
RUN echo 'root:123456' | chpasswd
#声明22端口
EXPOSE 22
#容器运行时启动sshd
RUN mkdir -p /opt
RUN echo '#!/bin/bash' >> /opt/run.sh
RUN echo '/usr/sbin/sshd -D'>> /opt/run.sh
RUN chmod +x /opt/run.sh
CMD ["/opt/run.sh"]
执行命令构建镜像:docker build -t hadoopbase:1.0 ./
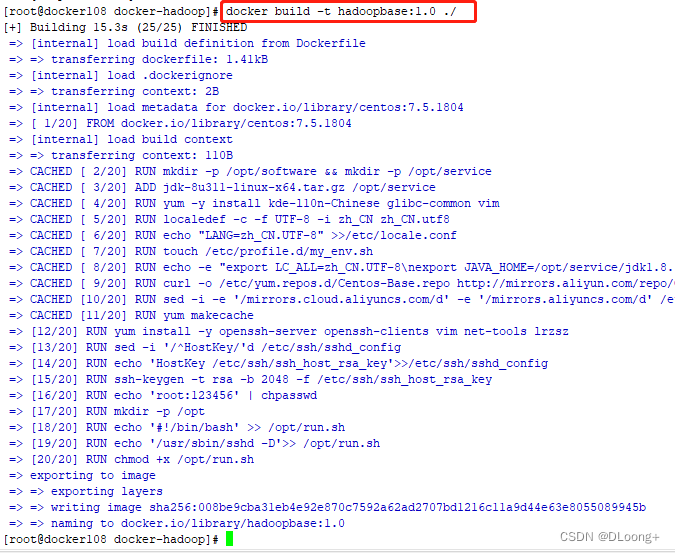
执行命令查看镜像:docker images

3.集群环境配置
1.创建3个容器
执行命令进行容器创建:
docker create -it --name hadoop102 -h hadoop102 hadoopbase:1.0
docker create -it --name hadoop103 -h hadoop103 hadoopbase:1.0
docker create -it --name hadoop104 -h hadoop104 hadoopbase:1.0
如下图:

2.配置网络
执行以下命令,在/usr/local/bin/目录下创建docker.sh文件,并将配置信息粘贴进去
#!/bin/bash
#启动容器
docker start hadoop102
docker start hadoop103
docker start hadoop104
#搭建网桥
brctl addbr br0; \
ip link set dev br0 up; \
ip addr del 192.168.88.108/24 dev ens33; \
ip addr add 192.168.88.108/24 dev br0; \
brctl addif br0 ens33; \
ip route add default via 192.168.88.1 dev br0
#睡5秒钟
sleep 5
#给容器配置ip和网关
pipework br0 hadoop102 192.168.88.102/24@192.168.88.1
pipework br0 hadoop103 192.168.88.103/24@192.168.88.1
pipework br0 hadoop104 192.168.88.104/24@192.168.88.1![]()
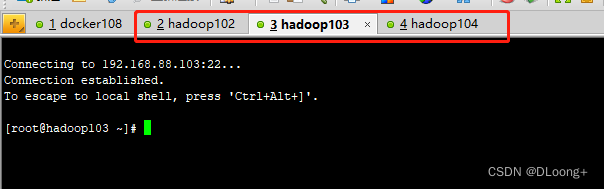
安装结束后执行docker.sh
执行完成后,通过XShell链接3个容器如下:
3.配置主机和ip的映射关系
在102下输入vim /etc/hosts,如下:
192.168.88.102 hadoop102
192.168.88.103 hadoop103
192.168.88.104 hadoop104
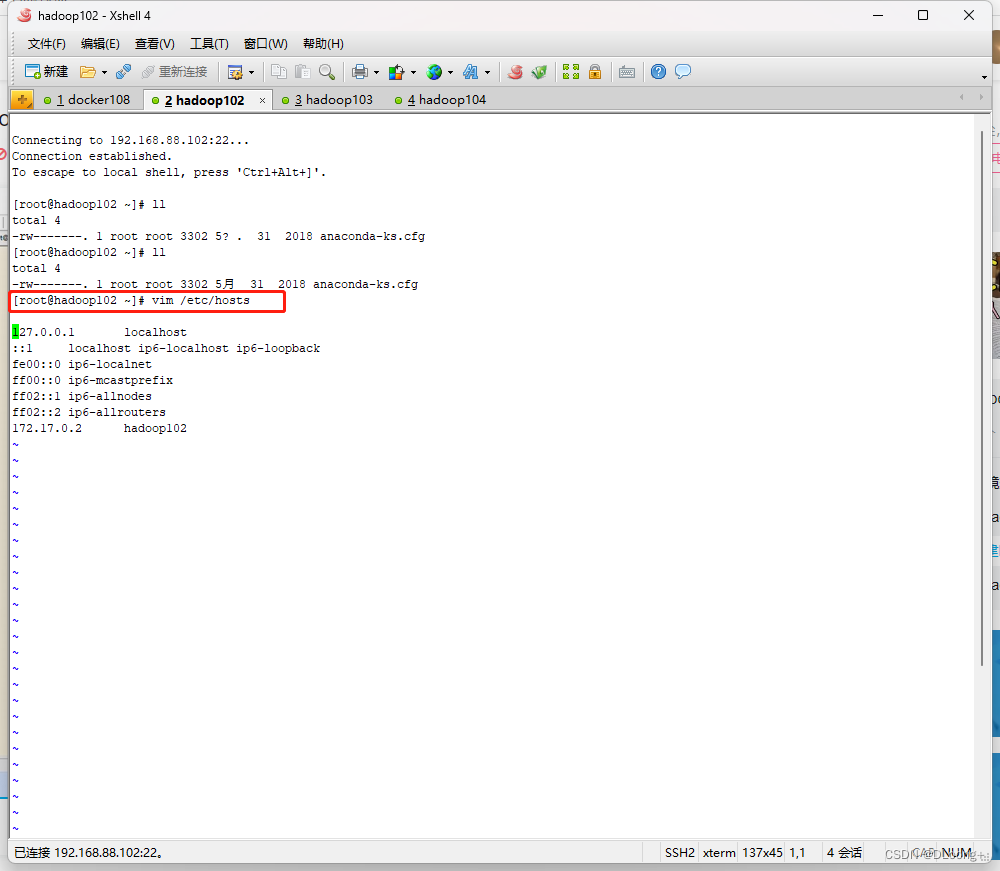
修改后如下:

在103和104中重复相同的操作
4.配置3个节点的免密登录
在hadoop102中生成公钥和私钥,输入ssh-keygen -t rsa 然后回车回车回车即可
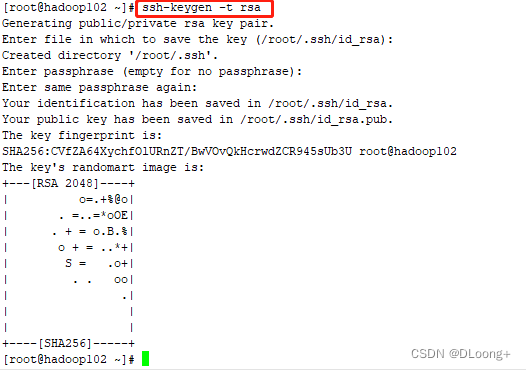
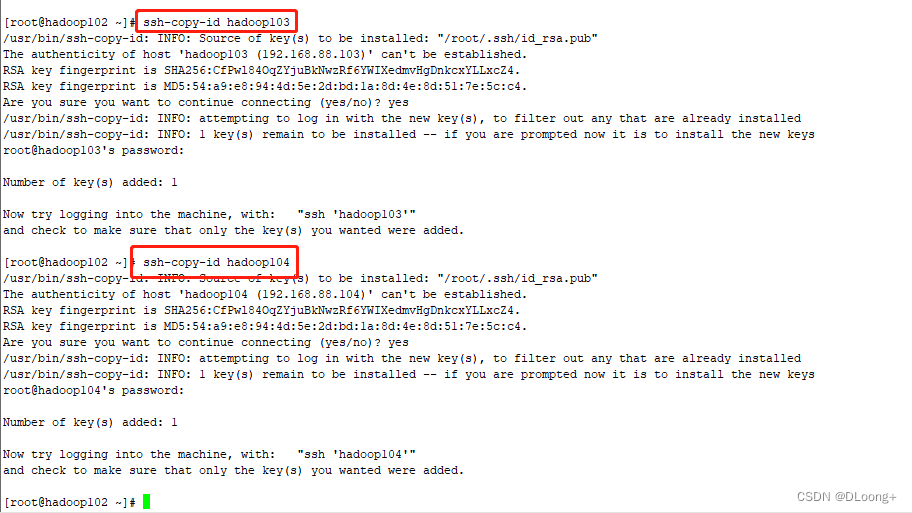
继续在hadoop102中输入ssh-copy-id hadoop102进行配置,回车,yes,输入密码即可
继续输入命令ssh-copy-id hadoop103进行配置
继续输入命令ssh-copy-id hadoop104进行配置

输入ssh hadoop103进行验证,成功登入,exit退回102
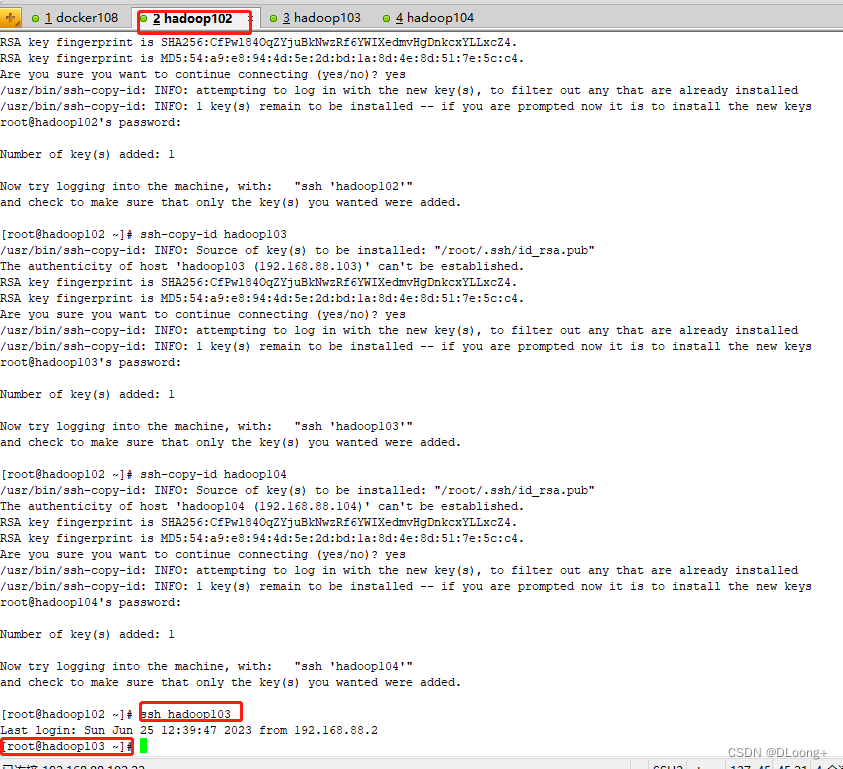
验证成功后,相同的操作在Hadoop103和Hadoop104中进行配置
hadoop%E9%9B%86%E7%BE%A4">4.搭建hadoop集群
hadoop">1.安装hadoop
将事先下载好的Hadoop3.1.3.tar.gz文件上传到hadoop102的/opt/software/目录下
解压并copy到/opt/service/这个目录下,如下:
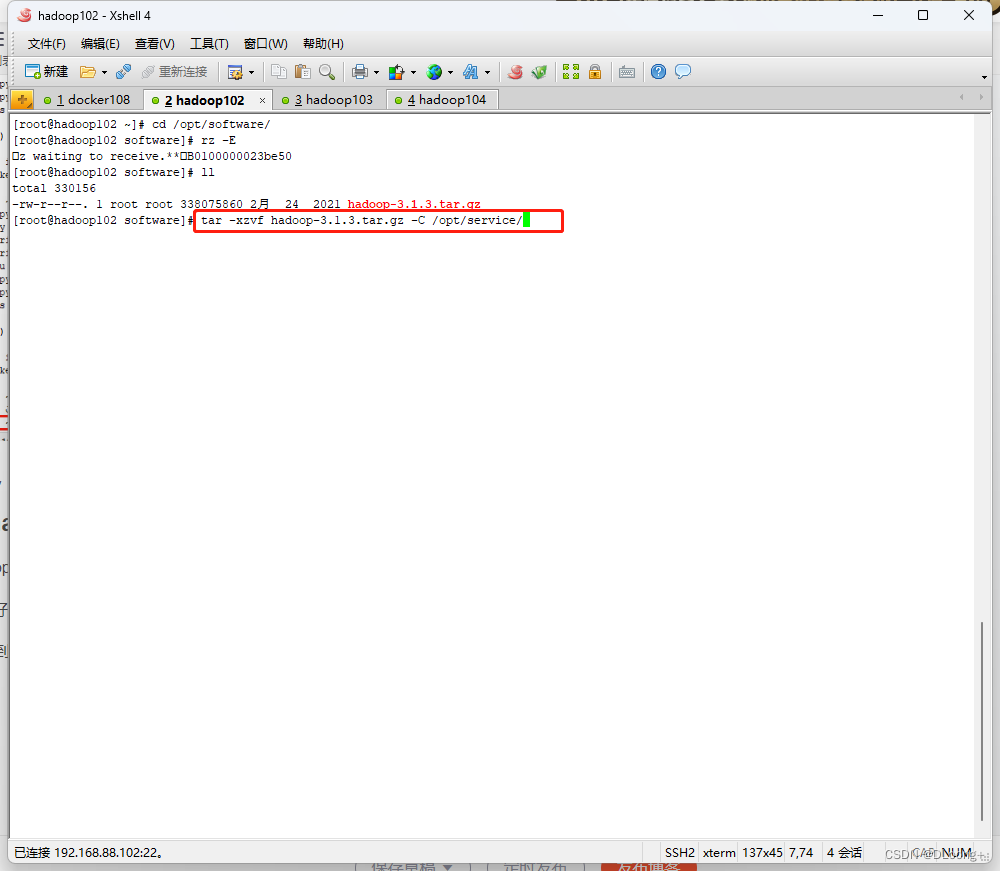
将hadoop添加到环境变量中
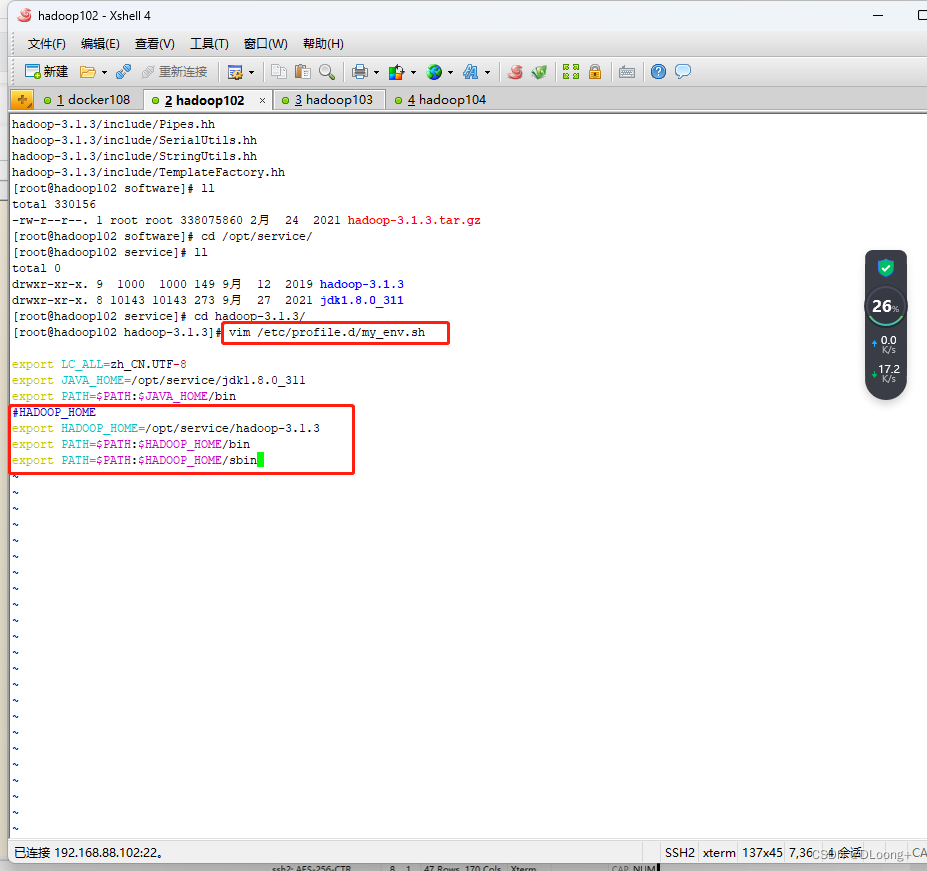
保存退出后执行source /etc/profile.d/my_env.sh
2.修改配置文件
修改core-site.xml文件
输入命令:cd /opt/service/hadoop-3.1.3/etc/hadoop/
进入该路径中,输入vim core-site.xml,将下面的配置信息编辑进去
<!-- 指定NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop102:8020</value>
</property>
<!-- 指定hadoop数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/service/hadoop-3.1.3/data</value>
</property>
<!-- 配置HDFS网页登录使用的静态用户为root -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>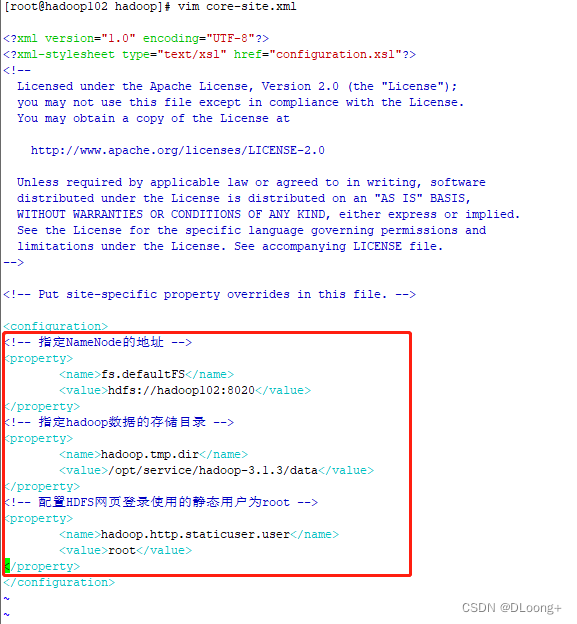
修改hdfs-site.xml 输入vim hdfs-site.xml
将下面的配置信息编辑进去
<!-- nn web端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop102:9870</value>
</property>
<!-- 2nn web端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop104:9868</value>
</property>
<!-- 测试环境指定HDFS副本的数量1 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>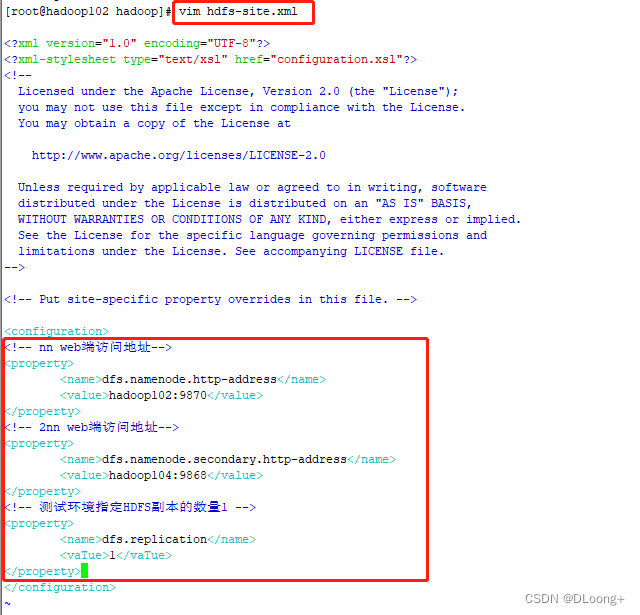
修改yarn-site.xml
输入vim yarn-site.xml 把下面的配置信息编辑进去 保存退出
<!-- 指定MR走shuffle-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop103</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<!-- yarn容器允许分配的最大最小内存-->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>2048</value>
</property>
<!-- yarn容器允许管理的物理内存大小-->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>4096</value>
</property>
<!-- 关闭yarn对虚拟内存的限制检查-->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!-- 开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop102:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为7天(7*24*60*60) -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800<</value>
</property>
修改mapred-site.xml文件
输入vim mapred-site.xml把下面的配置信息编辑进去
<!-- 指定MapReduce程序运行在Yarn 上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop102:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop102:19888</value>
</property>
修改workers
输入vim workers把localhost删掉,换成下面的配置信息
hadoop102
hadoop103
hadoop104
3.分发Hadoop及配置文件my_env.sh
执行命令
scp -r /opt/service/hadoop-3.1.3 hadoop103:/opt/service
scp -r /opt/service/hadoop-3.1.3 hadoop104:/opt/service
将hadoop分发到hadoop103和hadoop104中
执行命令
scp -r /etc/profile.d/my_env.sh hadoop103:/etc/profile.d
scp -r /etc/profile.d/my_env.sh hadoop104:/etc/profile.d
将my_env.sh分发到hadoop103和hadoop104中,分发完成后分别在103和104中执行
source /etc/profile.d/my_env.sh
5.启动集群

命令:
hdfs namenode -format
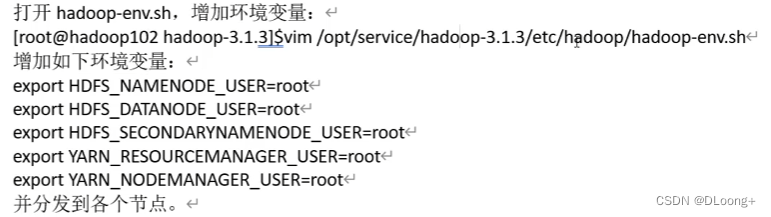
vim /opt/service/hadoop-3.1.3/etc/hadoop/hadoop-env.sh
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
配置完成后执行命令 start-dfs.sh 启动hdfs
将刚配置的文件分发到hadoop103和104中
scp -r /opt/service/hadoop-3.1.3/etc/hadoop/hadoop-env.sh hadoop103:/opt/service/hadoop-3.1.3/etc/hadoop
scp -r /opt/service/hadoop-3.1.3/etc/hadoop/hadoop-env.sh hadoop104:/opt/service/hadoop-3.1.3/etc/hadoop
然后在hadoop103上执行start-yarn.sh启动yarn
至此集群启动完成
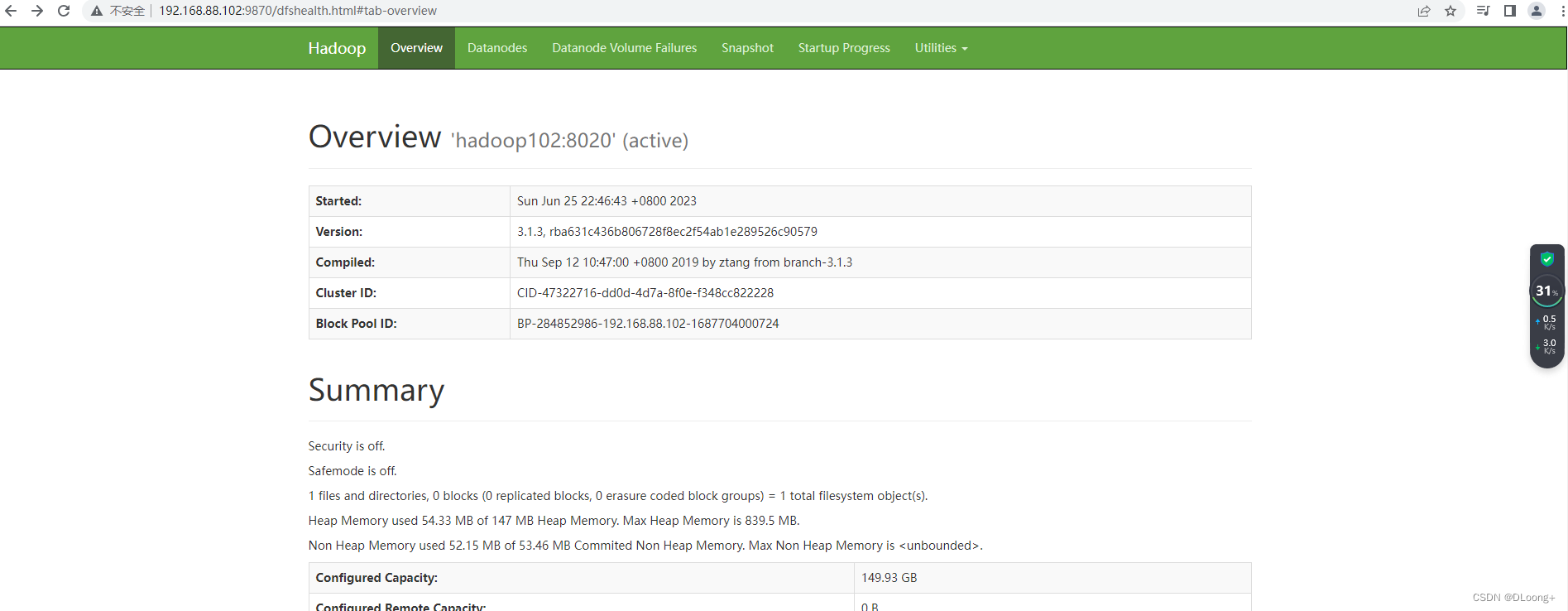
查看web端hdfs,网址:http://192.168.88.102:9870/
查看yarn,网址 :http://192.168.88.103:8088/