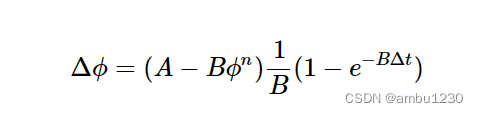HDFS文件系统写数据
1.步骤
文件上传步骤:
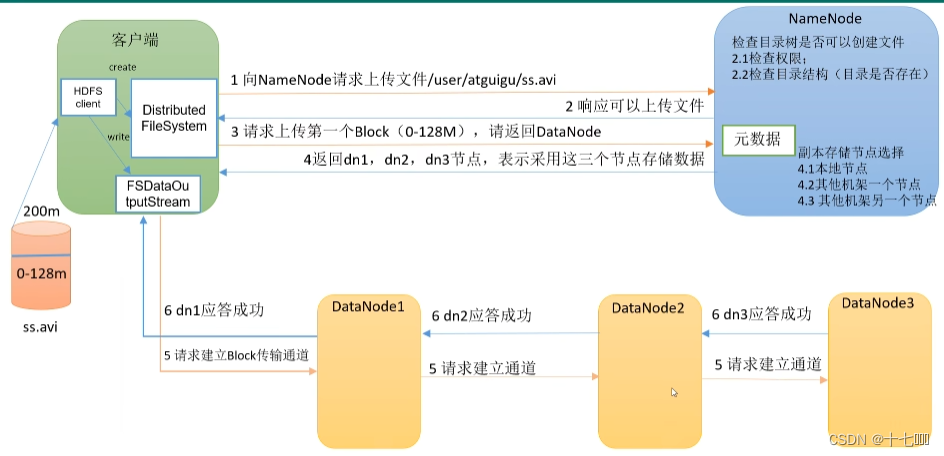
- 向NameNode请求上传文件+文件路径(验证请求身份,写权限)
- 响应可以上传文件
- 请求上传第一个Block(0-128M), 请返回DataNode
- 返回dn1,dn2,dn3节点,表示采用这三个节点存储数据
NameNode节点选择存储节点的原则:
- 节点最近原则
- 负载均衡
2.节点距离计算
在HDFS写数据的过程中,NameNode会选择距离待上传数据最近距离的DataNode接收数据,也就是节点最近原则
节点距离 = 两个节点到达最近的共同祖先的距离总和
集群、机架、主机通过类似树型的结构连接在一起,共同祖先节点的计算方法一样。
3.机架感知
NameNode接收到客户端发送过来的写数据请求后,会选择三个节点:
- 本地节点
- 其他机架的一个节点
- 其他机架的另一个节点
选择哪个节点的这个过程被称为机架感知,为何是这个策略呢?
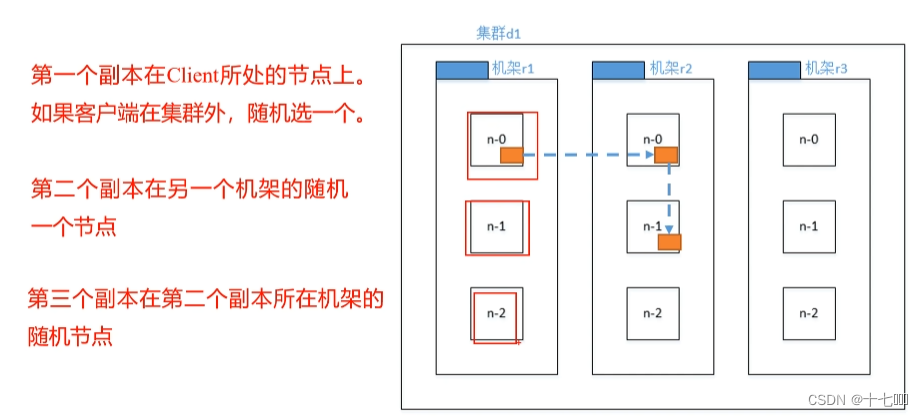
这个感知策略兼顾了数据的可靠性和效率,将数据分散在两个不同的机架,保证数据更可靠,其次第三个节点由于在同一个机架中,传输效率更高。
HDFS文件系统读数据
1.步骤
- 客户端向Name请求下载文件+文件地址(验证身份权限,权限)
- NameNode向客户端返回目标文件的元数据
- 客户端向DataNode请求读数据
- DataNode向客户端传输数据
2.读数据具体方式
实际上是串行读取方式,先读取完某个数据块后再读取另一个DataNode里面的数据。由于每个节点有3个备份,具体选择哪一个节点来进行读取主要使用节点最近原则和负载均衡原则。当某个节点读取数量超过一定数量时就更换为另一个节点。
NameNode和2NN工作机制
1.思考一下NameNode放在哪里比较好?
- 内存:好处是计算速度快,坏处是可靠性差。
- 磁盘:好处是可靠性高,坏处是计算速度慢
- 内存+磁盘:需要在内存中计算完,然后再持久化到磁盘中,两个位置都需要计算,效率更低。磁盘中存放的是fsImage镜像文件,如果是随机读写,效率很低。追加读写效率会更高
- 随机读写
- 需要读取历史数据
- 修改后覆盖历史数据
- 追加读写
- 不读取历史数据
- 直接修改操作追加到文件末尾
- 随机读写
2.第三种方式如何协调运行
- 客户端的增删改请求都会追加到edits_improgress中。
- 2NN会不定期向NameNode发送CheckPoint请求,CheckPoint触发条件有两种:
- 定时时间到
- Edits中的数据满了
- NameNode接受请求后edits追加信息会进行滚动操作,生成一个新的edits2文件,滚动期间的增删改操作会进入到edits2文件中。
- edits2文件生成后,2NN会将镜像文件和edits2都拷贝到2NN中,然后加载到内存中进行合并,并生成一个新的镜像文件fsimage.chkpoint, 并拷贝回NameNode中。
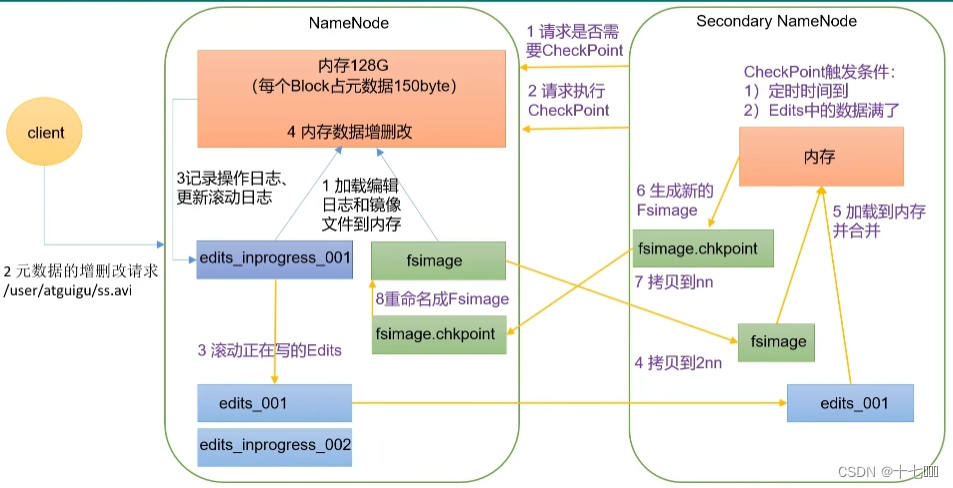
3.文件结构
在linux文件目录中,NN文件都存放在/opt/module/hadoop-3.1.3/data/dfs/name/current/路径下, 主要存放了如下文件
- fsimage镜像文件
- hdfs oiv -p 文件类型 -i 镜像文件 -o: 必须先将镜像文件转换为特定格式后才能查看
- fsimage文件存储了文件的inode节点,包含文件名以及文件之间的父子关系
- fsimage文件没有存放dataNode节点的存储位置,开机时dataNode会主动向对应的NameNode告知其位置
- edits追加文件
- 同理edits文件也需要转换类型后才能查看,命令为edits_inprogress_0000000000000000517
- NameNode保存着最新的修改信息,2NN没有。
- seen_txid追加次数
- VERSION版本信息(ClusterID集群ID):必须集群ID一致,NameNode才能找到相应的DataNode.