文章目录
- (168)HDFS小文件优化方法
- (169)MapReduce集群压测
- 参考文献
(168)HDFS小文件优化方法
小文件的弊端,之前也讲过,一是大量占用NameNode的空间,二是会使得寻址速度变慢。
另外,过多的小文件,在进行MR的时候,会生成过多切片,从而启动过多的MapTask,很容易造成,启动MapTask的时间比MapTask计算的时间还长,浪费资源。
那怎么解决小文件问题,有这么几个解决方向:
- 从数据源头上控制:
- 就是数据在采集的时候,就不让上传小文件,如果有小文件的话,就先合并成大文件之后,再上传到HDFS;
- 从存储上来控制:
- Hadoop Archive,即文件归档,将多个小文件压缩归档成一个大文件,可以减少NN的使用。
- 从计算方向上来控制:
- 采用CombineTextInputFormat,在切片过程中,将多个小文件生成一个切片;
- 开启uber模式,实现JVM重用。默认情况下,每个Task任务都需要开启一个JVM来运行,如果Task任务的计算量很小,那我们完全可以让多个Task运行在同一个JVM中,不需要开启多余的JVM。
下面举一下例子,在未开启Uber模式的情况下,我们在/input路径上上传多个小文件并执行wordcount程序:
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input /output2
观察控制台,里面会有行这样的输出:
2021-02-14 16:13:50,607 INFO mapreduce.Job: Job job_1613281510851_0002 running in uber mode : false
提示我们本次没有开启uber模式。
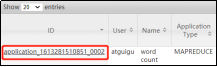
然后在yarn的网页里,查看刚刚运行完成的这个任务,如下图,会发现,它一共开启了5个容器:

接下来让我们开启uber模式,在mapred-site.xml中添加如下配置:
<!-- 开启uber模式,默认关闭 -->
<property>
<name>mapreduce.job.ubertask.enable</name>
<value>true</value>
</property>
<!-- uber模式中最大的mapTask数量,即JVM重用的次数,只能向下修改,即小于9 -->
<property>
<name>mapreduce.job.ubertask.maxmaps</name>
<value>9</value>
</property>
<!-- uber模式中最大的reduce数量,只能向下修改,即要不是0,要不是1 -->
<property>
<name>mapreduce.job.ubertask.maxreduces</name>
<value>1</value>
</property>
<!-- uber模式中最大的输入数据量,默认使用dfs.blocksize 的值,可向下修改 -->
<property>
<name>mapreduce.job.ubertask.maxbytes</name>
<value></value>
</property>
然后分发配置:
[atguigu@hadoop102 hadoop]$ xsync mapred-site.xml
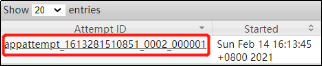
继续执行刚才执行过的WordCount程序,这时候我们可以从控制台里观察到这么一行输出:
2021-02-14 16:28:36,198 INFO mapreduce.Job: Job job_1613281510851_0003 running in uber mode : true
同时查看yarn,如下图,会发现当前任务,其实只用了一个容器:

所以uber模式的开启,实现了共用容器的效果。
(169)MapReduce集群压测
集群搭建好后,可以通过压测,来了解下当前集群的计算能力。
比如说可以执行下面的任务,查看多长时间内,可以执行完这个任务,就可以大概估算出数据量和执行时间之间的关系。
(1)使用RandomWriter来产生随机数,每个节点运行10个Map任务,每个Map产生大约1G大小的二进制随机数
[atguigu@hadoop102 mapreduce]$ hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar randomwriter random-data
(2)执行Sort程序
[atguigu@hadoop102 mapreduce]$ hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar sort random-data sorted-data
(3)验证数据是否真正排好序了
[atguigu@hadoop102 mapreduce]$
hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.3-tests.jar testmapredsort -sortInput random-data -sortOutput sorted-data
参考文献
- 【尚硅谷大数据Hadoop教程,hadoop3.x搭建到集群调优,百万播放】