一、组成架构
1、NameNode(NN) : 集群的Master,它是一个主管,管理者
(1) 管理HDFS的命名空间
(2) 配置副本策略
(3) 管理数据块(Block)映射信息
(4) 处理客户端读写请求
2、DataNode(DN) : 集群的Slave。NN下达命令,DataNode执行实际操作。
(1) 存储实际的数据块
(2) 执行数据块的读/写操作
3、Client : 客户端
(1) 文件切分。文件上传HDFS的时候,client将文件切分成一个个的Block,然后进行上传
(2) 与NameNode交互,获取文件的位置信息
(3) 与DataNode交互,读取或写入数据
4、SecondaryNameNode : 并非NameNode的热备。当NameNode挂掉的时候,它并不能马上替换NameNode并提供服务。
(1) 辅助NameNode,分担其工作量,比如定期合并Fsimage和Edits,并推送给NameNode
(2) 在紧急情况下可辅助恢复NameNode
二、HDFS存储副本机制
1、在 HDFS 中,每个数据块都会被分成若干个数据块副本。默认情况下每个数据块会被复制三次到HDFS 集群中的三个不同的 DataNode 上 。
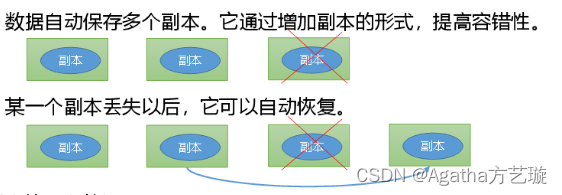
2、HDFS 会将数据块的多个副本分别存储在不同的 DataNode 上,以提高数据的可靠性和容错性。如果某个 DataNode 发生故障,数据块的其他副本仍然可以被访问。
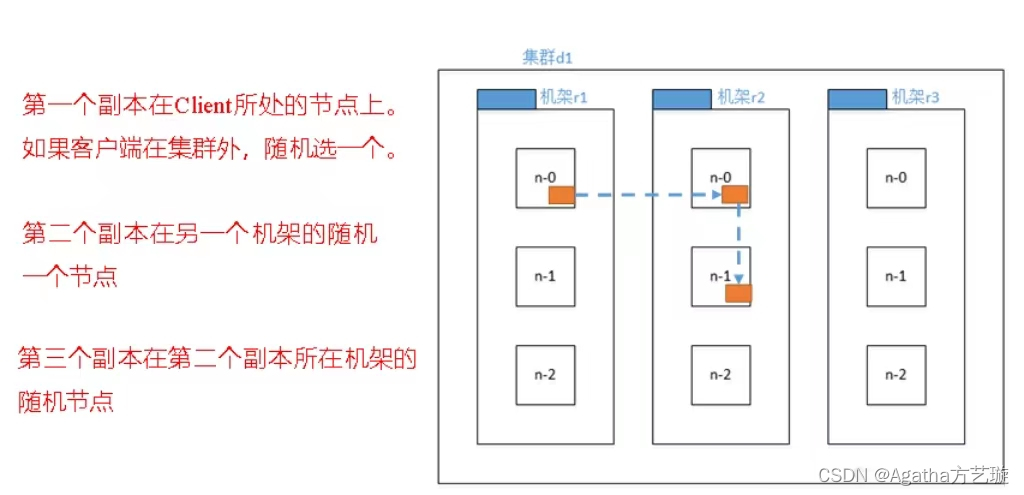
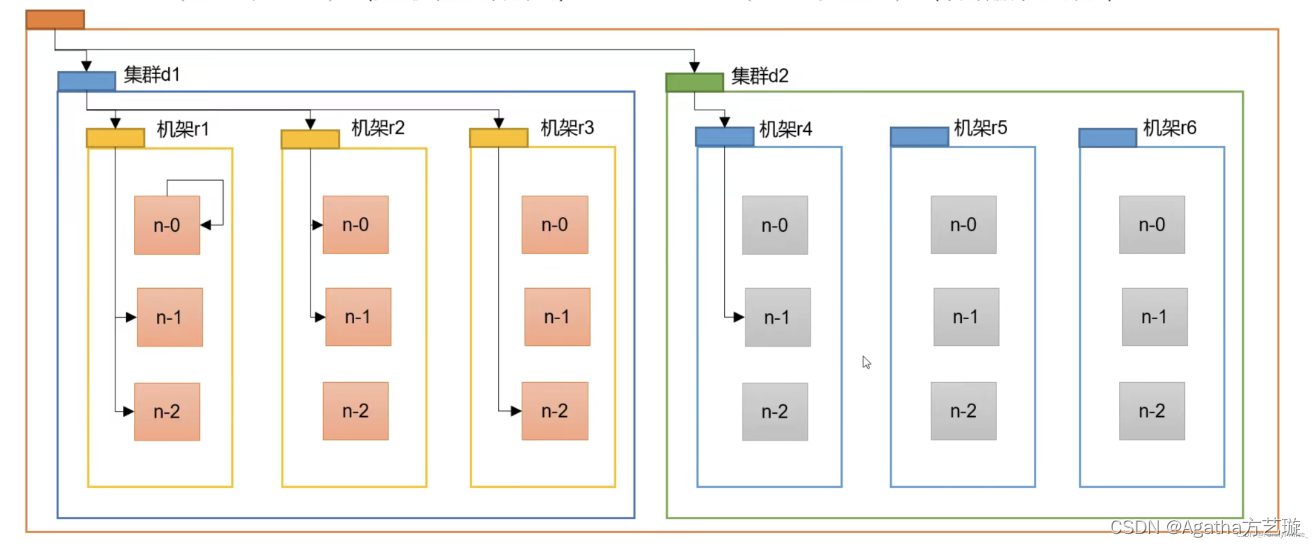
3、HDFS 会尽量将数据块的多个副本存储在不同的机架(rack)上,以避免机架故障导致数据不可用的情况。HDFS 会将数据块的多个副本存储在不同的机架的从节点上,第一个副本在客户端所处的节点上。如果客户端在集群外,随机选一个,第二个副本在另一个机架的随机一个节点,第三个副本在第二个副本所在机架的随机节点。
4、各个从节点通过机架交换机进行数据传输,各个机架通过集群内交换机进行数据传输,各个集群通过集群间交换机进行数据传输
三、HDFS 机架
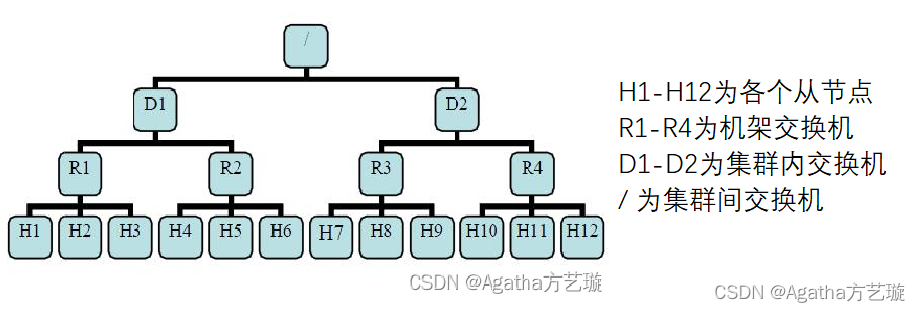
1、机架数据传输距离计算:
1)相同的datanode,距离为 0,比如H1到H1 distance(/D1/R1/H1,/D1/R1/H1)=0
2)同一机架下的不同datanode,距离为 2,比如H1到H2 distance(/D1/R1/H1,/D1/R1/H2)=2
3)同一集群不同机架下的datanode,距离为 4,比如H1到H4 distance(/D1/R1/H1,/D1/R1/H4)=4
4)不同集群下的datanode,距离为 6,比如H1到H7 distance(/D1/R1/H1,/D2/R3/H7)=6
2、为什么三分之一的副本在一个节点上,三分之二的副本在另一个机架不同节点上
1)hdfs 三个副本的这种存放策略减少了机架间的数据传输,提高了写操作的效率。
2)机架的错误远远比节点的错误少,所以这种策略不会影响到数据的可靠性和可用性。
3)与此同时,因为数据块只存放在两个不同的机架上,所以此策略减少了读取数据时需要的网络传输总带宽。
4)在这种策略下,副本并不是均匀的分布在不同的机架上:三分之一的副本在一个节点上,三分之二的副本在一个机架上,其它副本均匀分布在剩下的机架中,这种策略在不损害数据可靠性和读取性能的情况下改进了写的性能。
四、HDFS 写(Write)流程
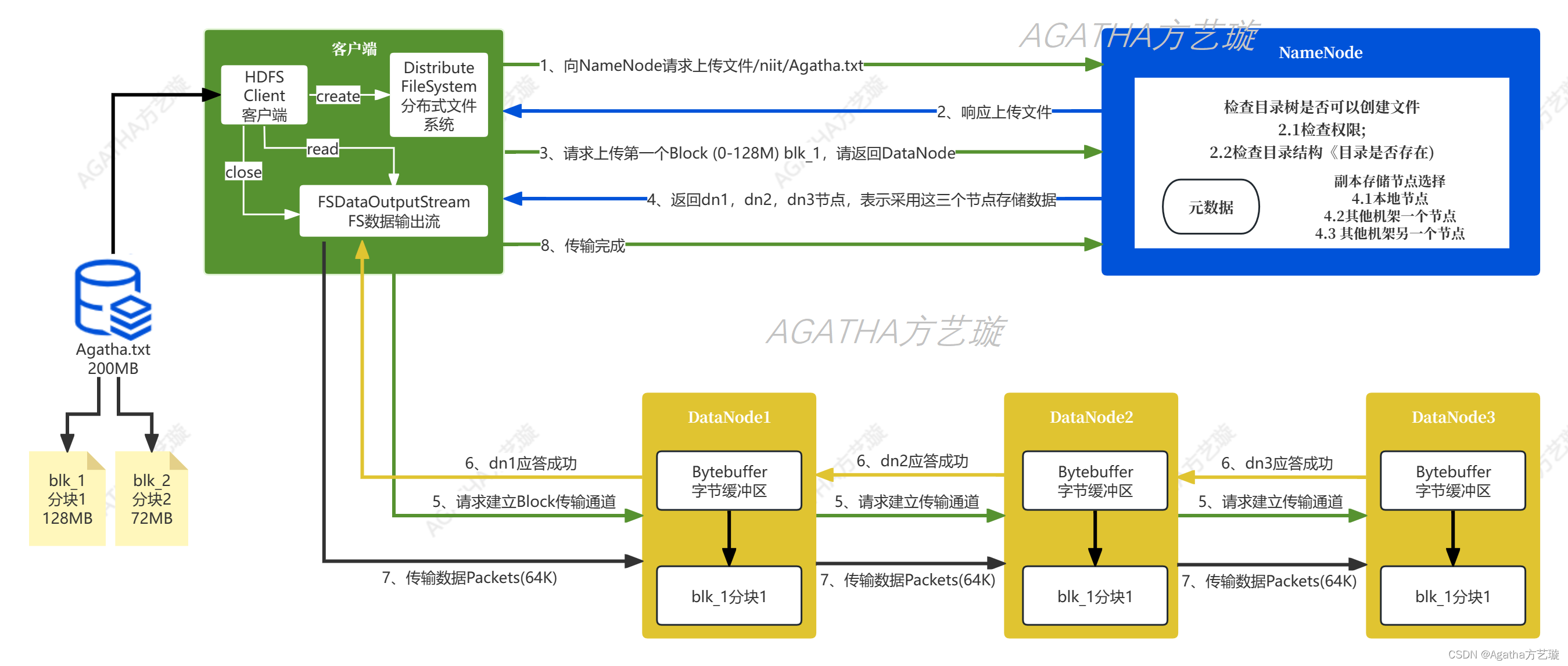
(1)客户端通过Distributed FileSystem模块向NameNode请求上传文件,NameNode检查目标文件是否已存在,父目录是否存在,客户端是否有写权限。
(2)NameNode返回是否可以上传。
(3)客户端请求第一个 Block上传到哪几个DataNode服务器上(数据的切分在客户端完成)。
(4)NameNode返回3个DataNode节点,分别为dn1、dn2、dn3(返回dn数据存储列表)。
(5)客户端通过FSDataOutputStream模块请求dn1上传数据,dn1收到请求会继续调用dn2,然后dn2调用dn3,将这个通信管道建立完成。(Pipline管道传输)
(6)dn1、dn2、dn3逐级应答客户端。
(7)客户端开始往dn1上传第一个Block(先从磁盘读取数据放到一个本地内存缓存),以Packet为单位,dn1收到一个Packet就会传给dn2,dn2传给dn3;dn1每传一个packet会放入一个应答队列等待应答(ACK校验)。
(8)当一个Block传输完成之后,客户端再次请求NameNode上传第二个Block的服务器。(重复执行3-7步)。
五、HDFS 读(Read)流程
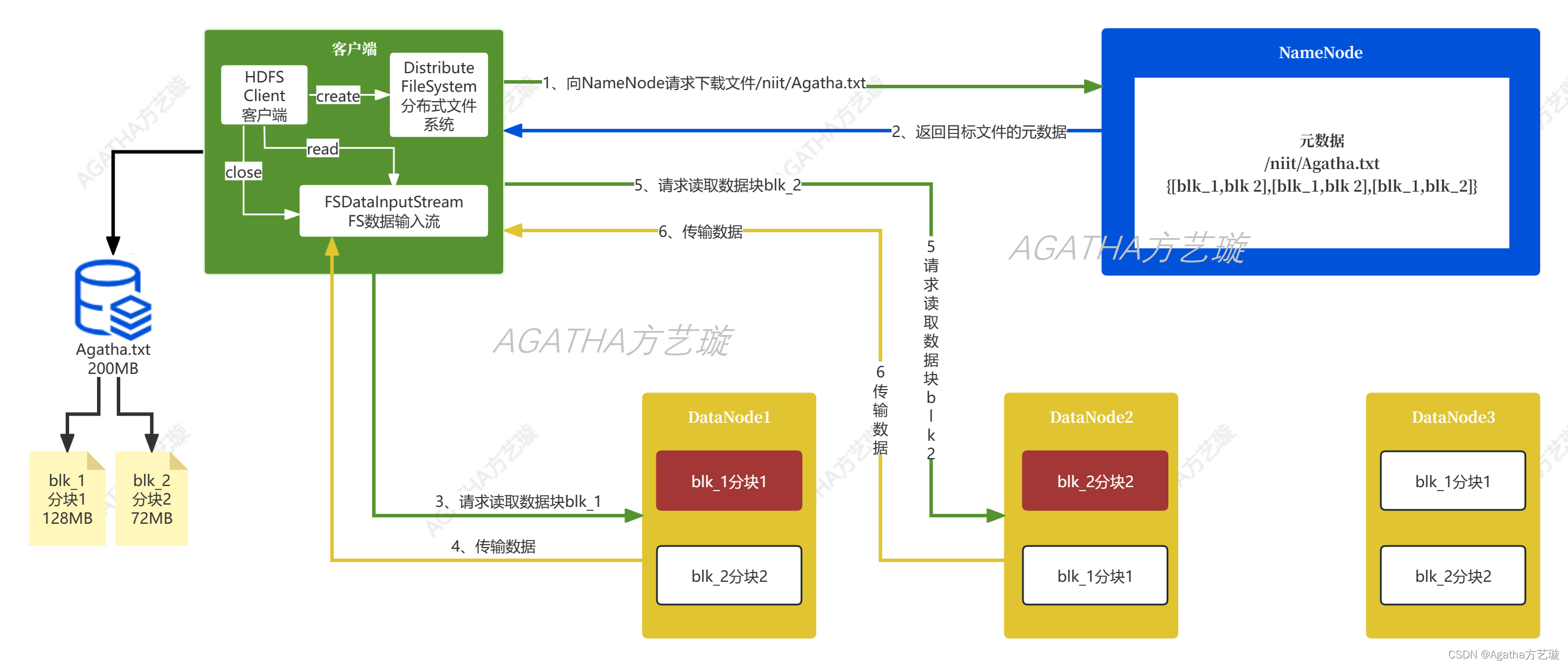
(1)客户端向 NameNode 发送读取请求,请求包括要读取的文件名和文件块的起始位置。
(2)NameNode 根据请求的文件名,查询文件所对应的块列表,并返回给客户端块列表以及每个块所在的 DataNode 列表。
(3)客户端根据返回的块列表和 DataNode 列表,选择一个 DataNode 开始读取数据。如果选择的 DataNode 不可用,则会选择另外一个 DataNode。
(4)客户端向选择的 DataNode 发送读取请求,请求包括要读取的块的起始位置和长度。
(5)DataNode 接收到读取请求后,从本地磁盘读取数据块,并将数据块返回给客户端