1、启动Hadoop集群
想要使用hdfs文件系统,就先要启动Hadoop集群。
启动集群:
start-dfs.sh
关闭集群:
stop-dfs.sh

2、文件系统构成
(1)基础介绍
其实hdfs作为分布式存储的文件系统,其构成和Linux文件系统构成差不多一样,均是以“/”作为根目录的组织形式。

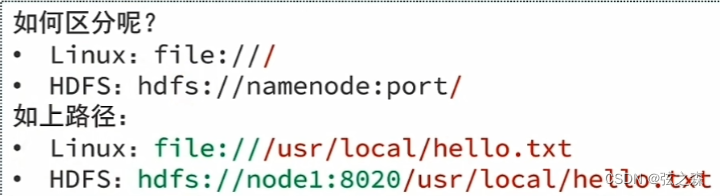
(2)区分路径
在以Hadoop用户作为Linux本地用户使用hdfs文件系统时,因为两者的命令结构十分相似,这里我们该如何区分呢?

3、hdfs命令体系

4、hdfs文件系统基础操作
(1)前言
在学习hdfs文件系统基础操作之后,你会发现hdfs文件系统的操作和Linux文件系统的操作十分相似,两者之间为数不多的区别就是hdfs文件系统在使用命令名时,需要在命令名前加上“-”。
(2)创建文件夹

(3)查看指定目录内容
·基础命令格式

·实际操作基础演示
hadoop@node1:~$ hadoop fs -ls /
Found 1 items
drwxr-xr-x - hadoop supergroup 0 2023-11-16 23:34 /home
hadoop@node1:~$ hdfs dfs -ls /
Found 1 items
drwxr-xr-x - hadoop supergroup 0 2023-11-16 23:34 /home·-R选项演示
【解释】:-R选项会将当前目录下的所有文件关系罗列出来,就像二叉树的遍历一样。
hadoop@node1:~$ hdfs dfs -ls -R /
drwxr-xr-x - hadoop supergroup 0 2023-11-18 10:27 /home
drwxr-xr-x - hadoop supergroup 0 2023-11-18 10:27 /home/code1
drwxr-xr-x - hadoop supergroup 0 2023-11-18 10:27 /home/code1/thing
drwxr-xr-x - hadoop supergroup 0 2023-11-18 10:27 /home/code2
drwxr-xr-x - hadoop supergroup 0 2023-11-18 10:27 /home/code3(4)上传文件
·基础格式

·路径:
Linux——>hdfs
·实际操作演示
【解释】:这里将本地Hadoop用户根目录下的text.txt文件,上传到hdfs文件系统根目录下。
hadoop@node1:~$ ls
text.txt
hadoop@node1:~$ hdfs dfs -put file:///home/hadoop/text.txt hdfs://node1:8020/
hadoop@node1:~$ hdfs dfs -ls /
Found 2 items
drwxr-xr-x - hadoop supergroup 0 2023-11-18 10:27 /home
-rw-r--r-- 3 hadoop supergroup 22 2023-11-18 10:38 /text.txt(5)查看文件内容
·基础格式
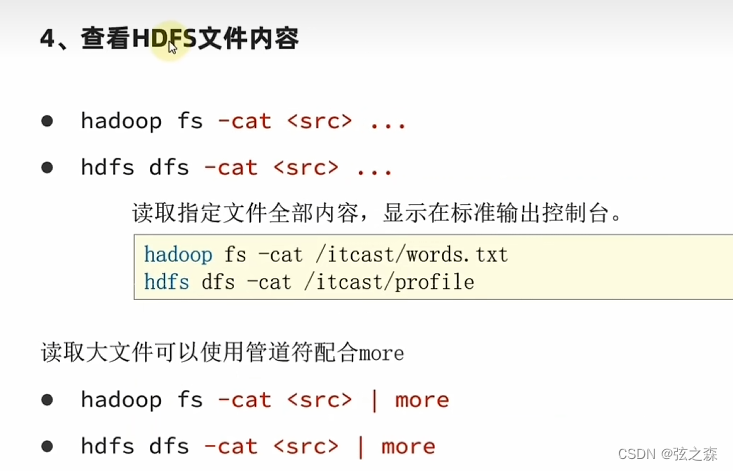
·实际操作演示
【解释】:这里查看hdfs文件系统根目录下text.txt的文件内容
hadoop@node1:~$ hdfs dfs -cat hdfs://node1:8020/text.txt
yanghaitao
hahaha
666·管道符and“more”的使用
但是对于hadoop来说,通常都是处理几十个G的大数据,这里我们可以借助管道符more进行操作查看。more:Linux中,文件内容进行翻页的命令:
hadoop@node1:~$ hdfs dfs -cat hdfs://node1:8020/code.txt
不写协议头
上传文件
从Linux文件系统——>hdfs文件系统
yanghaitao
hahaha
666
yanghaitao
hahaha
666
yanghaitao
hahaha
666
yanghaitao
hahaha
666
yanghaitao
hahaha
666
yanghaitao
hahaha
666
yanghaitao
hahaha
666
[more]……(6)下载内容
·路径
hdfs——>Linux
·基础格式
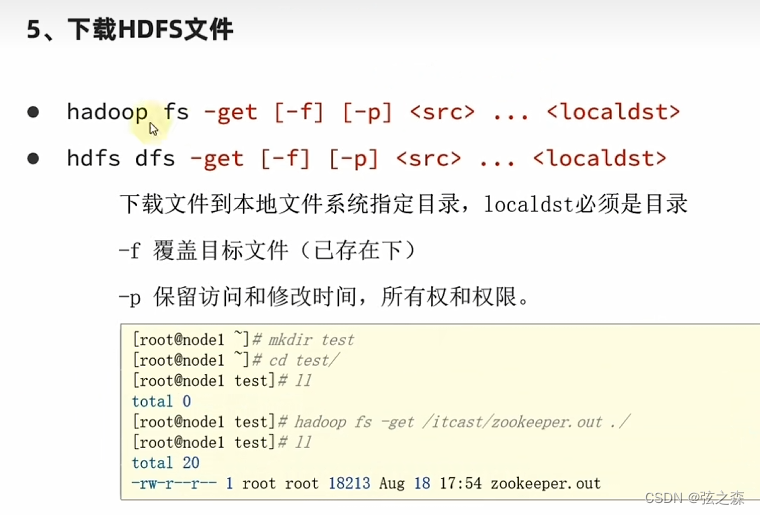
·实际操作演示
在hadoop本地创建一个文件夹mkdir YHT,将从hdfs下载的文件存储到该文件夹中。
hadoop@node1:~$ hdfs dfs -get hdfs://node1:8020/text.txt ./YHT
hadoop@node1:~$ cd YHT
hadoop@node1:~/YHT$ ls
text.txt(7)拷贝文件
·路径
·基础格式

·实际操作演示
【解释】:为了方便,这里我们删除hdfs://node1:8020/home目录下的所有文件,然后将hdfs根目录下code.txt的文件复制到hdfs根目录下的home目录内:
hadoop@node1:~$ hdfs dfs -cp hdfs://node1:8020/code.txt hdfs://node1:8020/home
hadoop@node1:~$ hdfs dfs -ls hdfs://node1:8020/home
Found 1 items
-rw-r--r-- 3 hadoop supergroup 667 2023-11-18 11:17 hdfs://node1:8020/home/code.txt还有,我们在复制的同时,实现文件的重命名工作:
【操作解释】:此处将hdfs://node1:8020/text.txt复制到hdfs://node1:8020/home/new.txt,并将文件名改为new.txt
hadoop@node1:~$ hdfs dfs -cp hdfs://node1:8020/text.txt hdfs://node1:8020/home/new.txt
hadoop@node1:~$ hdfs dfs -ls hdfs://node1:8020/home
Found 2 items
-rw-r--r-- 3 hadoop supergroup 667 2023-11-18 11:17 hdfs://node1:8020/home/code.txt
-rw-r--r-- 3 hadoop supergroup 22 2023-11-18 11:22 hdfs://node1:8020/home/new.txt·注意
整个hdfs文件系统,文件的修改只支持两种,那就是删除和追加。
(8)追加数据
·路径
Linux——>hdfs
·基础格式

· 实际操作演示
在这里,我们将Hadoop用户根目录下的append.txt文件,追加到hdfs文件系统的根目录下text.txt的文件中。
hadoop@node1:~$ hdfs dfs -cat hdfs://node1:8020/text.txt
yanghaitao
hahaha
666
hadoop@node1:~$ cat append.txt
I'm append things.
from hadoop to hdfs://node1:8020/text.txt
hadoop@node1:~$ hdfs dfs -appendToFile append.txt hdfs://node1:8020/text.txt
hadoop@node1:~$ hdfs dfs -cat hdfs://node1:8020/text.txt
yanghaitao
hahaha
666
I'm append things.
from hadoop to hdfs://node1:8020/text.txt(9)移动文件数据
·路径
·基础格式

·实际操作演示
hadoop@node1:~$ hdfs dfs -ls hdfs://node1:8020/
Found 2 items
drwxr-xr-x - hadoop supergroup 0 2023-11-18 11:22 hdfs://node1:8020/home
-rw-r--r-- 3 hadoop supergroup 83 2023-11-18 11:33 hdfs://node1:8020/text.txt
hadoop@node1:~$ hdfs dfs -mv hdfs://node1:8020/text.txt hdfs://node1:8020/home/
hadoop@node1:~$ hdfs dfs -ls hdfs://node1:8020/home
Found 3 items
-rw-r--r-- 3 hadoop supergroup 667 2023-11-18 11:17 hdfs://node1:8020/home/code.txt
-rw-r--r-- 3 hadoop supergroup 22 2023-11-18 11:22 hdfs://node1:8020/home/new.txt
-rw-r--r-- 3 hadoop supergroup 83 2023-11-18 11:33 hdfs://node1:8020/home/text.txt(10)删除数据
·基础格式

·实际操作演示
【解释】:删除hdfs://node1:8020/home文件夹
hadoop@node1:~$ hdfs dfs -rm -r hdfs://node1:8020/home/
Deleted hdfs://node1:8020/home
hadoop@node1:~$ hdfs dfs -ls hdfs://node1:8020/(11)配置回收站
·第一步:修改配置文件
vim /export/server/hadoop/etc/hadoop/core-site.xml·第二步:修改参数
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
<property>
<name>fs.trash.checkpoint.interval</name>
<value>120</value>
</property>·第三步:实际操作演示
回收站地址:
hdfs://node1:8020/user/hadoop/.Trash/Current在hdfs://node1:8020/home目录下创建名为thing.txt的文件,删除演示:
# 删除hdfs文件系统home目录下的thing.txt文件
hadoop@node1:~$ hdfs dfs -ls hdfs://node1:8020/home/
Found 1 items
-rw-r--r-- 3 hadoop supergroup 0 2023-11-18 12:27
hdfs://node1:8020/home/thing.txt
hadoop@node1:~$ hdfs dfs -rm -r hdfs://node1:8020/home/thing.txt
2023-11-18 12:28:08,439 INFO fs.TrashPolicyDefault:Moved:'hdfs://node1:8020/home/thing.txt' to trash at: hdfs://node1:8020/user/hadoop/.Trash/Current/home/thing.txt
# 进入回收,可以看到刚刚被删除的thing.txt文件
hadoop@node1:~$ hdfs dfs -ls hdfs://node1:8020/user/hadoop/.Trash/Current
Found 1 items
drwx------ - hadoop supergroup 0 2023-11-18 12:28 hdfs://node1:8020/user/hadoop/.Trash/Current/home