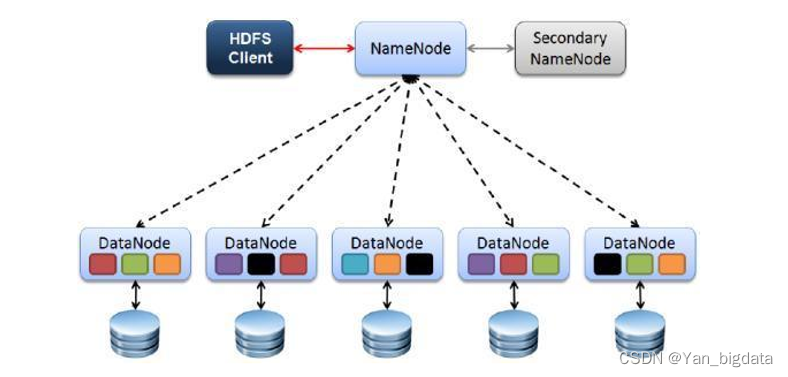
hdfs_0">1.hdfs分布式文件存储的特点
分布式存储:一次写入,多次读取
HDFS文件系统可存储超大文件,时效性较差.
HDFS基友硬件故障检测和自动快速恢复功能.
HDFS为数据存储提供很强的扩展能力.
HDFS存储一般为一次写入,多次读取,只支持追加写入,不支持随机修改.
HDFS可以在普通廉价的机器上运行.
2.HDFS架构
1、Client
发请求就是客户端。
文件切分。文件上传 HDFS 的时候,Client 将文件切分成 一个一个的Block,然后进行存储
与 NameNode 交互,获取文件的位置信息。
与 DataNode 交互,读取或者写入数据。
Client 提供一些命令来管理 和访问HDFS,比如启动或者关闭HDFS。
2、NameNode
就是 master,它是一个主管、管理者。
处理客户端读写请求。
管理 HDFS 元数据(文件路径,文件的大小,文件的名字,文件权限,文件切割后的块(block)信息…)。
配置3副本备份策略。
3、DataNode
就是Slave。NameNode 下达命令,DataNode 执行实际的操作。
存储实际的数据块(block)。
执行数据块的读/写操作。
定时向namenode汇报block信息。
4、Secondary NameNode
并非 NameNode 的备份节点。当NameNode 挂掉的时候,它并不能马上替换 NameNode 并提供服务。
只是辅助 NameNode,对HDFS元数据进行合并,合并后再交给NameNode。
在紧急情况下,可辅助恢复 NameNode 部分数据。
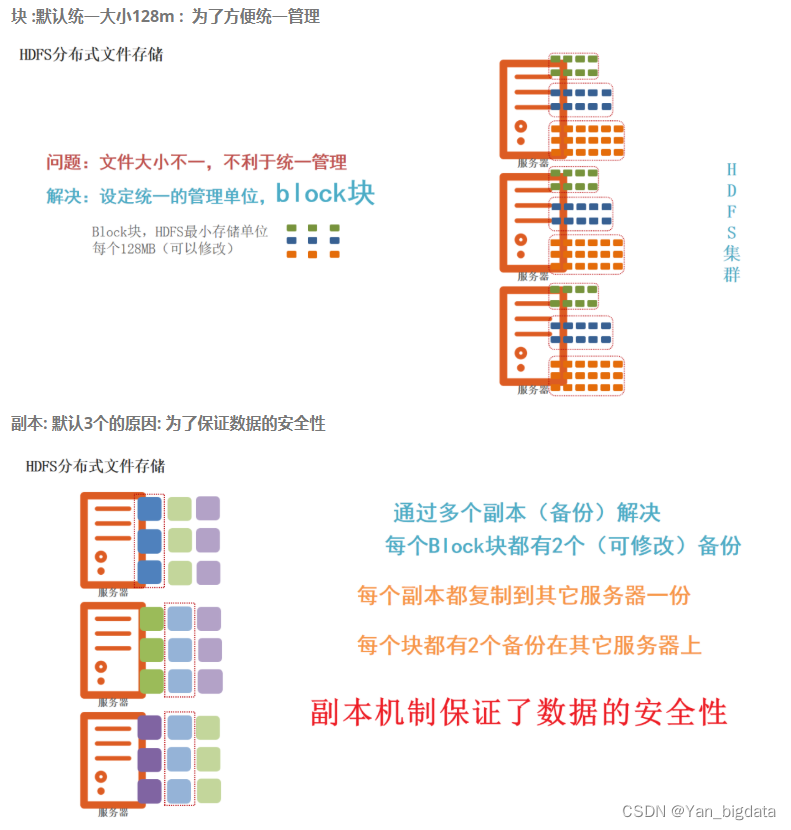
3.块和副本
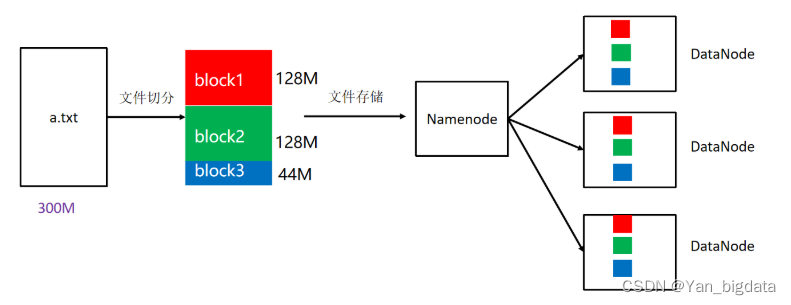
block块: HDFS被设计成能够在一个大集群中跨机器可靠地存储超大文件。它将每个文件拆分成一系列的数据块进行存储,这个数据块被称为block,除了最后一个,所有的数据块都是同样大小的。
block 块大小默认: 128M(134217728字节) 注意: 块同样大小方便统一管理
副本系数默认: 3个 副本好处: 副本为了保证数据安全(用消耗存储资源方式保证安全,导致了大数据瓶颈是数据存储)
注意: 为了容错,文件的所有block都会有副本。每个文件的数据块大小和副本系数都是可配置的。
hdfs默认文件配置:https://hadoop.apache.org/docs/r3.3.4/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
如何修改块大小和副本数量呢?可以在hdfs-site.xml中配置如下属性:
<property>
<name>dfs.blocksize</name>
<value>134217728</value>
<description>设置HDFS块大小,单位是b</description>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
4.三大机制
4.1副本机制
为了保证数据安全和效率,block块信息存储多个副本,第一副本保存在客户端所在服务器,第二副本保存在和第一副本不同机架服务器上,第三副本保存在和第二副本相同机架不同服务器
机架感知机制
副本机制如何识别是否为同一个机架以及服务器?
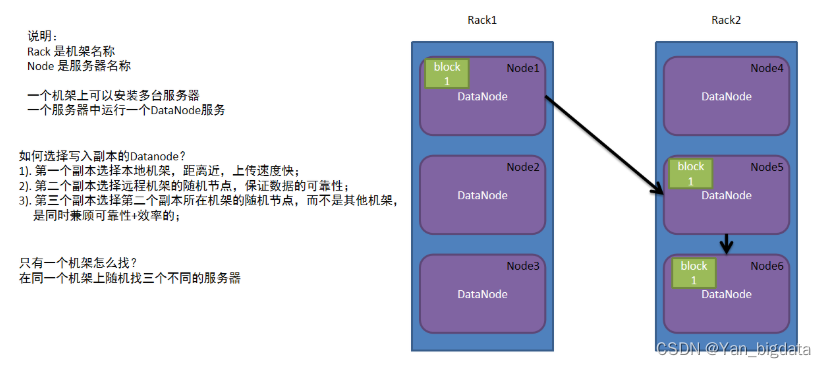
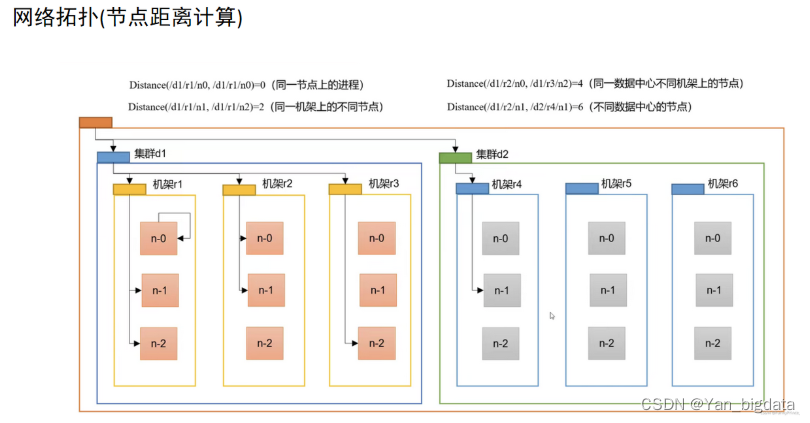
网络拓扑图
4.2负载均衡机制
namenode为了保证不同的datanode中block块信息大体一样,分配存储任务的时候会优先保存在距离近且余量比较大的datanaode上
4.3心跳机制
datanode每隔3秒钟向namenode汇报自己的状态信息,如果某个时刻,datanode连续10次不汇报了,namenode会认为datanode有可能宕机了,namenode就会每5分钟(300000毫秒)发送一次确认消息,连续2次没有收到回复,就认定datanode此时一定宕机了(确认datanode宕机总时间310+52*60=630秒)
5. 写入数据原理
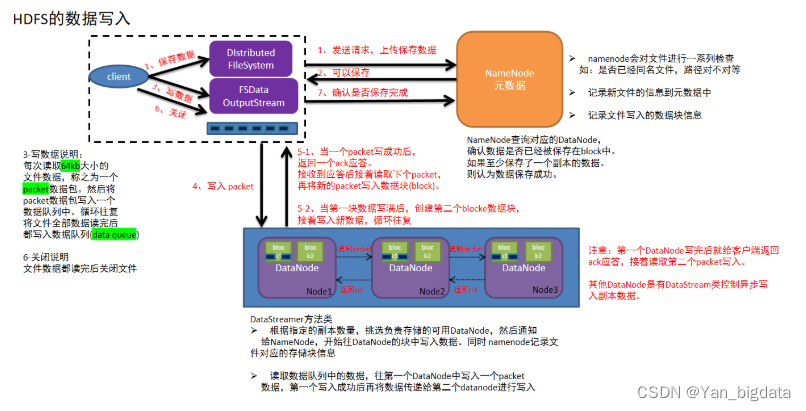
1.客户端发起写入数据的请求给namenode
2.namenode接收到客户端请求,开始校验(是否有权限,路径是否存在,文件是否存在等),如果校验没问题,就告知客户端可以写入
3.客户端收到消息,开始把文件数据分割成默认的128m大小的的block块,并且把block块数据拆分成64kb的packet数据包,放入传输序列
4.客户端携带block块信息再次向namenode发送请求,获取能够存储block块数据的datanode列表
5.namenode查看当前距离上传位置较近且不忙的datanode,放入列表中返回给客户端
6.客户端连接datanode,开始发送packet数据包,第一个datanode接收完后就给客户端ack应答(客户端就可以传入下一个packet数据包),同时第一个datanode开始复制刚才接收到的数据包给node2,node2接收到数据包也复制给node3(复制成功也需要返回ack应答),最终建立了pipeline传输通道以及ack应答通道
7.其他packet数据根据第一个packet数据包经过的传输通道和应答通道,循环传入packet,直到当前block块数据传输完成(存储了block信息的datanode需要把已经存储的块信息定期的同步给namenode)
8.其他block块数据存储,循环执行上述4-7步,直到所有block块传输完成,意味着文件数据被写入成功(namenode把该文件的元数据保存上)
9.最后客户端和namenode互相确认文件数据已经保存完成(也会汇报不能使用的datanode)
6.读取数据原理
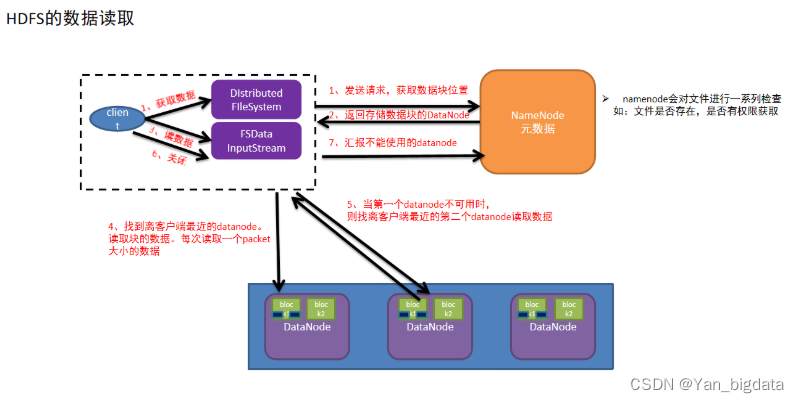
1.客户端发送读取文件请求给namenode
2.namdnode接收到请求,然后进行一系列校验(路径是否存在,文件是否存在,是否有权限等),如果没有问题,就告知可以读取
3.客户端需要再次和namenode确认当前文件在哪些datanode中存储
4.namenode查看当前距离下载位置较近且不忙的datanode,放入列表中返回给客户端
5.客户端找到最近的datanode开始读取文件对应的block块信息(每次传输是以64kb的packet数据包),放到内存缓冲区中
6.接着读取其他block块信息,循环上述3-5步,直到所有block块读取完毕(根据块编号拼接成完整数据)
7.最后从内存缓冲区把数据通过流写入到目标文件中
8.最后客户端和namenode互相确认文件数据已经读取完成(也会汇报不能使用的datanode)
7.元数据存储的原理
7.1 edits和fsimage文件
namenode管理元数据: 基于edits和FSImage的配合,完成整个文件系统文件的管理。每次对HDFS的操作,均被edits文件记录, edits达到大小上限后,开启新的edits记录,定期进行edits的合并操作
如当前没有fsimage文件, 将全部edits合并为第一个fsimage文件
如当前已存在fsimage文件,将全部edits和已存在的fsimage进行合并,形成新的fsimage
edits编辑文件: 记录hdfs每次操作(namenode接收处理的每次客户端请求)
fsimage镜像文件: 记录某一个时间节点前的当前文件系统全部文件的状态和信息(namenode所管理的文件系统的一个镜像)
SecondaryNameNode辅助合并元数据: SecondaryNameNode会定期从NameNode拉取数据(edits和fsimage)然后合并完成后提供给NameNode使用。
对于元数据的合并,是一个定时过程,基于两个条件:
dfs.namenode.checkpoint.period:默认3600(秒)即1小时
dfs.namenode.checkpoint.txns: 默认1000000,即100W次事务
dfs.namenode.checkpoint.check.period: 检查是否达到上述两个条件,默认60秒检查一次,只要有一个达到条件就执行拉取合并

查看历史编辑文件
命令: hdfs oev -i edits文件名 -o 自定义文件名.xml
[root@node1 current]# cd /export/data/hadoop/dfs/name/current
[root@node1 current]# hdfs oev -i edits_0000000000000033404-0000000000000033405 -o 405_edit.xml
[root@node1 current]# cat 405_edit.xml
查看镜像文件
命令: hdfs oiv -i fsimage文件名 -p XML -o 自定义文件名.xml
[root@node1 current]# cd /export/data/hadoop/dfs/name/current
[root@node1 current]# hdfs oiv -i fsimage_0000000000000033405 -p XML -o 405_fsimage.xml
[root@node1 current]# cat 405_fsimage.xml
7.2 内存/文件元数据
namenode和secondarynamenode: 配合完成对元数据的保存
元数据: 内存元数据和文件元数据两种分别在内存和磁盘上
内存元数据: namnode运行过程中产生的元数据会先保存在内存中,再保存到文件元数据中。
内存元数据优缺点:
优点: 因为内存处理数据的速度要比磁盘快。
缺点: 内存一断电,数据全部丢失
文件元数据: Edits 编辑日志文件和fsimage 镜像文件
Edits编辑日志文件: 存放的是Hadoop文件系统的所有更改操作(文件创建,删除或修改)的日志,文件系统客户端执行的更改操作首先会被记录到edits文件中
Fsimage镜像文件: 是元数据的一个持久化的检查点,包含Hadoop文件系统中的所有目录和文件元数据信息,但不包含文件块位置的信息。文件块位置信息只存储在内存中,是在 datanode加入集群的时候,namenode询问datanode得到的,并且不间断的更新
fsimage和edits关系: 两个文件都是经过序列化的,只有在NameNode启动的时候才会将fsimage文件中的内容加载到内存中,之后NameNode把增删改查等操作记录同步到edits文件中.使得内存中的元数据和实际的同步,存在内存中的元数据支持客户端的读操作,也是最完整的元数据。
7.3 元数据存储的原理
注意: 第一次启动namenode的时候是没有编辑日志文件和镜像文件的,下图主要介绍的是第二次及以后访问的时候情况流程
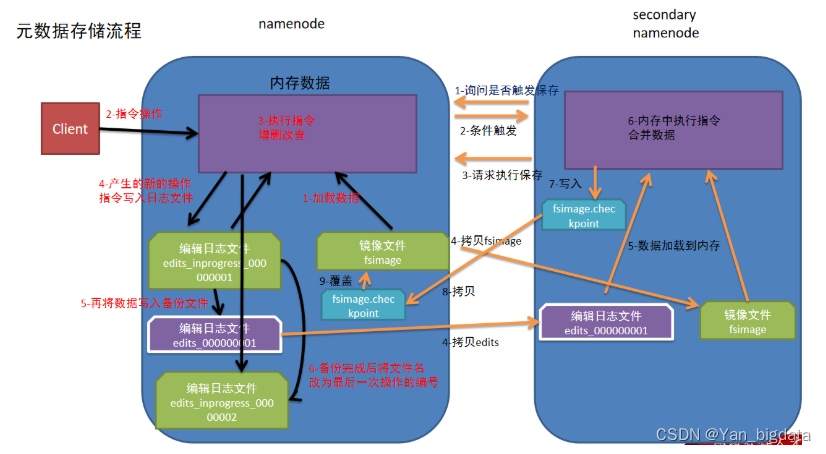
1.namenode第一次启动的时候先把最新的fsimage文件中内容加载到内存中,同时把edits文件中内容也加载到内存中
2.客户端发起指令(增删改查等操作),namenode接收到客户端指令把每次产生的新的指令操作先放到内存中
3.然后把刚才内存中新的指令操作写入到edits_inprogress文件中
4.edits_inprogress文件中数据到了一定阈值的时候,把文件中历史操作记录写入到序列化的edits备份文件中
5.namenode就在上述2-4步中循环操作…
6.当secondarynamenode检测到自己距离上一次检查点(checkpoint)已经1小时或者事务数达到100w,就触发secondarynamenode询问namenode是否对edits文件和fsimage文件进行合并操作
7.namenode告知可以进行合并
8.secondarynamenode将namenode上积累的所有edits和一个最新的fsimage下载到本地,并加载到内存进行合并(这个过程称checkpoint)
9.secondarynamenode把刚才合并后的fsimage.checkpoint文件拷贝给namenode
10.namenode把拷贝过来的最新的fsimage.checkpoint文件,重命名为fsimage,覆盖原来的文件