🐶5.1 hdfs的概念
HDFS分布式文件系统,全称为:Hadoop Distributed File System。
它是一个文件系统,用于存储文件,通过目录树来定位文件;其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色。
HDFS的使用场景:适合一次写入,多次读出的场景。一个文件经过创建、写入和关闭之后就不需要改变。
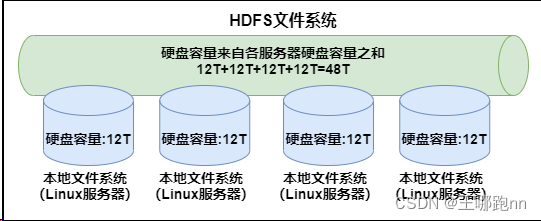
我一共三台linux服务器,每台机器内存60G,所以HDFS文件系统之和为180G
🐶5.2 为什么要用hdfs:
因为随着数据量越来越大,一台机器已经不能满足当前数据的存储,如果使用多台计算机进行存储,虽然解决了数据的存储问题,但是后期的管理和维护成本比较高,因为我们不能精准的知道哪台机器上存储了什么样的数据,所以我们迫切的需要一个能够帮助我们管理多台机器上的文件的一套管理系统,这就是分布式文件系统的作用,而hdfs就是这样的一套管理系统,而且他也只是其中的一种.
🐶5.3 hdfs的优缺点
5.3.1 优点:
🥙1. 高容错性:
数据自动保存多个副本。它通过增加副本的形式,提高容错性。

某一个副本丢失以后,它可以自动恢复。

🥙2. 高扩展性:
当HDFS系统的存储空间不够时,我们只需要添加一台新的机器到当前集群中即可完成扩容,这就是我们所说的横向扩容,而集群的存储能力,是按照整个集群中的所有的机器的存储能力来计算的,这也就是我们所说的高扩容性
🥙3. 适合处理大数据:
-
数据规模:能够处理数据规模达到GB、TB、甚至PB级别的数据。
-
文件规模:能够处理百万规模以上的文件数量,数量相当之大。
5.3.2 缺点:
🥙1. 不适合低延时数据访问;
-
比如毫秒级的来存储数据,这是不行的,它做不到。
-
它适合高吞吐率的场景,就是在某一时间内写入大量的数据。但是它在低延时的情况 下是不行的,比如毫秒级以内读取数据,这样它是很难做到的。
🥙2. 无法高效的对大量小文件进行存储
-
存储大量小文件的话,它会占用NameNode大量的内存来存储文件、目录和块信息。这样是不可取的,因为NameNode的内存总是有限的。
-
小文件存储的寻址时间会超过读取时间,它违反了HDFS的设计目标。
🥙3. 不支持并发写入、文件随机修改
-
一个文件只能有一个写,不允许多个线程同时写。

-
仅支持数据 append(追加),不支持文件的随机修改。
🐶5.4 HDFS架构
HDFS是一个主/从(Master/Slave)体系结构,架构中有三个角色:一个叫NameNode,一个叫DataNode,还有一个叫secondaryNameNode
主从架构示例图:
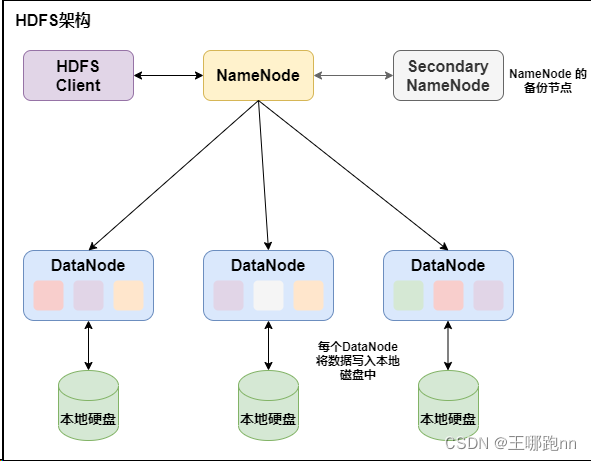
所以我们在搭建hdfs架构时,需要一台NameNode,三台DataNode,一台SecondaryNameNode.
1. NameNode
主要负责存储文件的元数据,比如集群id,文件存储所在的目录名称,文件的副本数,以及每个文件被切割成块以后的块列表和块列表所在的DataNode。
1)管理HDFS的名称空间。
2)配置副本策略
3)管理数据块(Block)映射信息。
2. DataNode
负责管理用户的文件数据块,每一个数据块都可以在多个 DataNode 上存储多个副本,默认为3个。
1)存储实际的数据块
2)执行数据块的读/写操作

| NameNode | DataNode |
| 存储元数据 | 存储文件内容 |
| 元数据保存在内存中 | 文件内容保存在磁盘 |
| 保存文件、block、DataNode之间的映射关系 | 维护了block id到DataNode本地文件的映射关系 |
3. SecondaryNameNode
并非NameNode的热备。当NameNode挂掉的时候,它并不能马上替换NameNode并提供服务。
1)辅助NameNode,分担其工作量,比如定期合并Fsimage和Edits,并推送给NameNode;
2) 在紧急情况下,可辅助恢复NameNode.
4. Client:就是客户端
1)文件切分。文件上传HDFS的时候,client将文件切分成一个一个的block,然后进行上传。
2)与namenode交互,获取文件的位置信息
3)与datanode交互,读取或者写入数据。
4)Client提供一些命令来管理HDFS,比如NameNode格式化
5)Client可以通过一些命令来访问HDFS,比如对HDFS增删查改操作。
🐶5.5 HDFS文件块大小(面试题)
HDFS中的文件在物理上是分块存储(Block), 块的大小可以通过配置参数(dfs blocksize)来规定,默认大小在Hadoop2x/3x版本中是128M,1x版本中是64M.
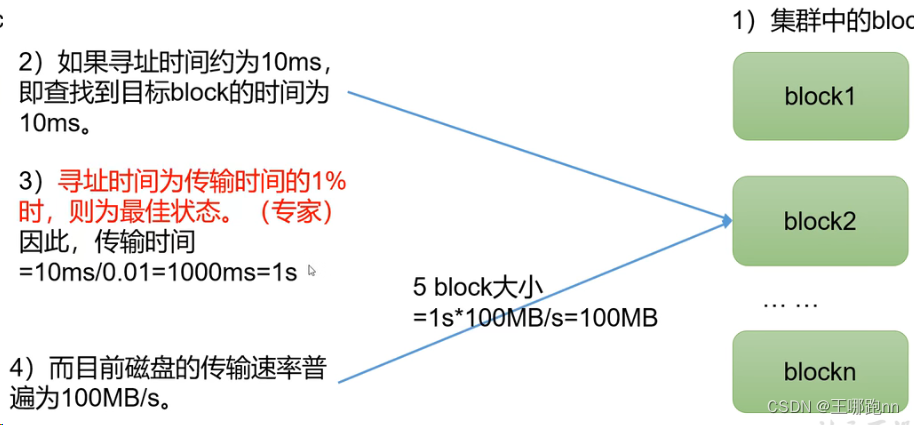
问题:能不能将块设置的小一些? 理论上是可以的,但是如果设置的块大小过小,会占用大量的namenode的元数据空间,而且在读写操作时,加大了寻址时间,所以不建议设置的过小 问题:不能过小,那能不能过大? 不建议,因为设置的过大,传输时间会远远大于寻址时间,增加了网络资源的消耗,而且如果在读写的过程中出现故障,恢复起来也很麻烦,所以不建议
总结:HDFS块的大小设置主要取决于磁盘传输速率。