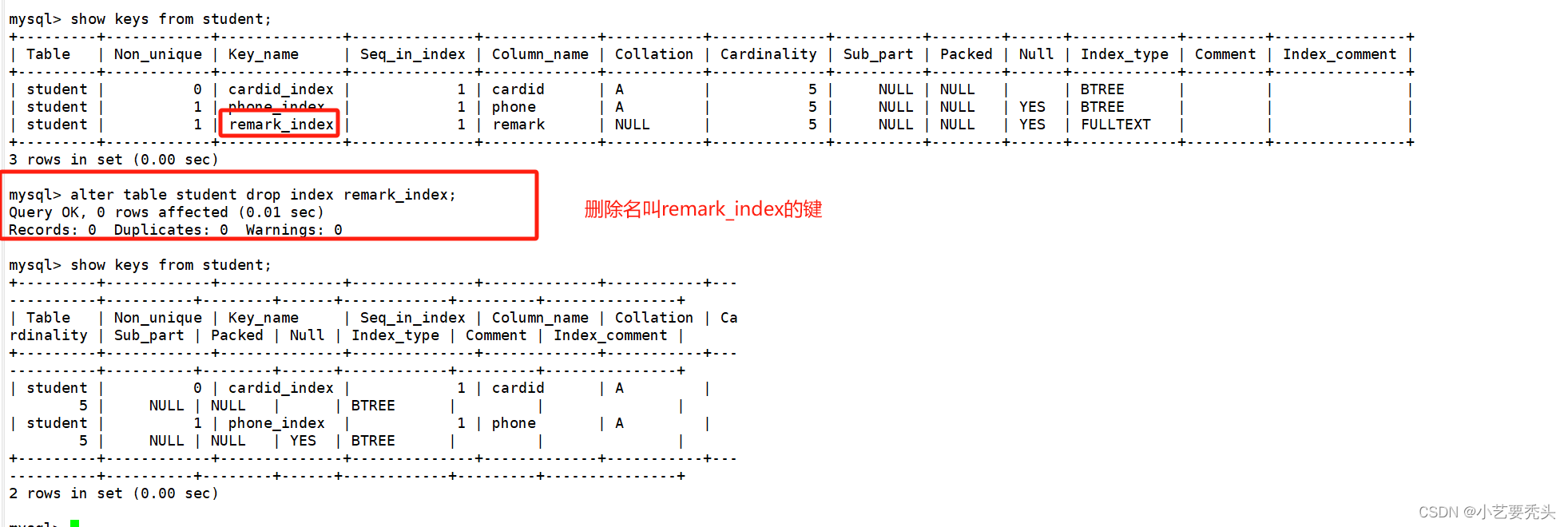
IDE 连接
在本地电脑上解压 hadoop.tar.gz,配置环境变量
之后 去github 上 把 winutil.exe 和 hadoop.dll 下载到 hadoop 的bin 文件夹下
再修改 etc/hadoop-env.cmd 中的 JDK 路径
我们使用 IDEA 打开一个 JAVA Maven项目,进行测试
注意,这里的包导入全部都是在 hadoop 下的导入:
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.3.6</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.3.6</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.3.6</version>
</dependency>
进行简单的入门级体会:
public class HDFSApi {
@Test
public void getFileSystemTest() throws IOException {
// 创建配置文件对象用于读取配置文件信息
// 其默认会读取 core-default.xml hdfs-site.xml mapred-default.xml yarn-default.xml 四大配置文件
// 如果项目中存在配置文件 core-site.xml hdfs-site.xml mapred-site.xml yarn-site.xml 则会读取这四个配置文件
// 配置文件读取完成之后,我们还可以对配置文件进行修改
Configuration conf = new Configuration();
// 进行 属性配置,若不配置 获取的是 org.apache.hadoop.fs.LocalFileSystem 这个不是我们需要的对象
// 进行配置之后,获取到的就是 org.apache.hadoop.hdfs.DistributedFileSystem 对象了,这个对象使我们操作 HDFS 所需要的核心对象
conf.set("fs.defaultFS", "hdfs://192.168.202.101:9820");
FileSystem fs = FileSystem.get(conf);
System.out.println(fs.getClass().getName());
}
}
文件操作
上传与下载
文件的上传与下载操作
/**
* 另外要注意的问题是:在操作 HDFS 时,我们操作 HDFS 使用的用户和我们操作当前操作系统的用户保持了一致,这样会导致我们没有对于当前用户的写操作的权限
* 这就需要我们配置操作 HDFS 的用户
*/
public class HDFSApi {
FileSystem fs;
@Before
public void getFileSystemTest() throws IOException {
// 配置操作 HDFS 的用户
System.setProperty("HADOOP_USER_NAME", "hadoop");
// 创建配置文件对象用于读取配置文件信息
// 其默认会读取 core-default.xml hdfs-site.xml mapred-default.xml yarn-default.xml 四大配置文件
// 如果项目中存在配置文件 core-site.xml hdfs-site.xml mapred-site.xml yarn-site.xml 则会读取这四个配置文件
// 配置文件读取完成之后,我们还可以对配置文件进行修改
Configuration conf = new Configuration();
// 进行 属性配置,若不配置 获取的是 org.apache.hadoop.fs.LocalFileSystem 这个不是我们需要的对象
// 进行配置之后,获取到的就是 org.apache.hadoop.hdfs.DistributedFileSystem 对象了,这个对象使我们操作 HDFS 所需要的核心对象
conf.set("fs.defaultFS", "hdfs://192.168.202.101:8020");
fs = FileSystem.get(conf);
System.out.println(fs.getClass().getName());
}
@After
public void closeFileSystem() throws IOException {
fs.close();
}
/**
* 文件上传
*/
@Test
public void uploadTest() throws IOException {
// 配置要上传的文件和文件上传的目标路径
Path src = new Path("C:/Users/M_Bai/Desktop/bejson_gen_beans.zip");
Path dst = new Path("/");
// 上传文件
fs.copyFromLocalFile(src, dst);
}
/**
* 文件下载
*/
@Test
public void downloadTest() throws IOException {
// 配置要下载的文件路径以及文件要下载到的位置
Path src = new Path("/bejson_gen_beans.zip");
Path dst = new Path("C:/Users/M_Bai/Desktop/new.mp4");
fs.copyToLocalFile(src, dst);
}
}
文件夹操作
@Test
public void mkdirTest() throws IOException {
fs.mkdirs(new Path("/test_mkdir"));
}
@Test
public void deleteTest() throws IOException {
// 这里的第二个 bool 型参数代表是否递归删除
fs.delete(new Path("/test_mkdir"), true);
// 删除单个文件
fs.delete(new Path("/file_test.txt"));
}
// 重命名
@Test
public void renameTest() throws IOException {
fs.rename(new Path("/file_test.txt"), new Path("/file.txt"));
}
// 判断文件、文件夹是否存在
@Test
public void existTest() throws IOException {
boolean isExist = fs.exists(new Path("file.txt"));
System.out.println(isExist);
}
IOUtils
上传文件
@Test
public void ioUtilsTest() throws IOException {
// 基础配置与 FileSystem 对象的创建
System.setProperty("HADOOP_USER_NAME", "hadoop");
Configuration configuration = new Configuration();
configuration.set("fs.defaultFS", "hdfs://192.168.202.101:8020");
FileSystem fileSystem = FileSystem.get(configuration);
// 将要上传的文件转换为流
FileInputStream input = new FileInputStream("D:/BigData/hadoopTest/hadoopAPI/hadoopAPI/src/main/java/qinghe/hdfs/TestApi.java");
// 创建输出到 HDFS 的文件的流
FSDataOutputStream output = fileSystem.create(new Path("/TestApi.java"));
// 利用 IOUtils 将输入流复制给输出流,也就是将输出流写入到 HDFS 的文件中
IOUtils.copyBytes(input, output, configuration);
// 关闭流
IOUtils.closeStream(input);
IOUtils.closeStream(output);
}
下载一个文件:
@Test
public void ioUtilsTestDownload() throws IOException {
System.setProperty("HADOOP_USER_NAME", "hadoop");
Configuration configuration = new Configuration();
configuration.set("fs.defaultFS", "hdfs://192.168.202.101:8020");
FileSystem fileSystem = FileSystem.get(configuration);
// 将要下载的文件转化为流
FSDataInputStream input = fileSystem.open(new Path("/TestApi.java"));
// 创建写入到本地的流
FileOutputStream output = new FileOutputStream("C:/Users/M_Bai/Desktop/nnnnnnnnnnnnnnnnnnnnnn.mp4");
IOUtils.copyBytes(input, output, configuration);
IOUtils.closeStream(input);
IOUtils.closeStream(output);
}
文件信息的查看:
/**
* 查看文件的状态信息
*/
@Test
public void listFileStatusTest() throws IOException {
// 文件信息需要使用 iterator 进行遍历,每一个文件占用一个迭代器
RemoteIterator<LocatedFileStatus> iterator = fs.listLocatedStatus(new Path("/TestApi.java"));
while (iterator.hasNext()) {
// 获取到当前遍历的文件
LocatedFileStatus fileStatus = iterator.next();
System.out.println("基本信息:" + fileStatus);
// 获取到当前文件的块的集合
BlockLocation[] blockLocations = fileStatus.getBlockLocations();
// 遍历该文件所在的所有块
for (BlockLocation blockLocation : blockLocations) {
System.out.println("当前块的所有副本信息:" + Arrays.toString(blockLocation.getHosts()));
System.out.println("当前块的大小:" + blockLocation.getLength());
System.out.println("当前块的副本的 IP 地址:" + Arrays.toString(blockLocation.getNames()));
}
System.out.println("系统块的大小:" + fileStatus.getBlockSize());
System.out.println("当前文件的总大小:" + fileStatus.getLen());
}
}