HDFS进程启停命令
Hadoop HDFS组件内置了HDFS集群的一键启停脚本。
- $HADOOP_HOME/sbin/start-dfs.sh,一键启动HDFS集群
- $HADOOP_HOME/sbin/stop-dfs.sh,一键关闭HDFS集群
执行原理:
- 在执行此脚本的机器上,启动(关闭)SecondaryNameNode
- 读取core-site.xml内容(fs.defaultFS项),确认NameNode所在机器,启动(关闭)NameNode
- 读取workers内容,确认DataNode所在机器,启动(关闭)全部DataNode
除了一键启停外,也可以单独控制进程的启停
- $HADOOP_HOME/sbin/hadoop-daemon.sh,此脚本可以单独控制所在机器的进程的启停
用法:hadoop-daemon.sh (start|status|stop) (namenode|secondarynamenode|datanode) - $HADOOP_HOME/bin/hdfs,此程序也可以用以单独控制所在机器的进程的启停
用法:hdfs --daemon (start|status|stop) (namenode|secondarynamenode|datanode)
HDFS文件系统基本命令(跟Linux命令基本一样)
hadoop fs -mkdir -p /itest
hdfs dfs -mkdir -p /itest
- 上传文件到HDFS指定目录下(上传put,下载 get)
hadoop fs -put [-f] [-p] <localsrc> ... <dst>
hdfs dfs -put [-f] [-p] <localsrc> ... <dst>
hadoop fs -put test.txt /itest
hdfs dfs -put test.txt /itest
- 追加数据到HDFS文件中(appendToFile)
hadoop fs -appendToFile <localsrc> ... <dst>
hdfs dfs -appendToFile <localsrc> ... <dst>
hadoop fs -appendToFile 2.txt 3.txt /itest/1.txt
hdfs dfs -appendToFile 2.txt 3.txt /itest/1.txt
- HDFS数据删除操作(rm,skipTrash跳过回收站)
hadoop fs -rm -r [-skipTrash] URI [URI ...]
hdfs dfs -rm -r [-skipTrash] URI [URI ...]
hadoop fs -rm -r -skipTrash /itest
hdfs dfs -rm -r -skipTrash /itest
- HDFS shell其它命令(点此参照官方文档
- HDFS WEB浏览

使用WEB浏览操作文件系统,一般会遇到权限问题

这是因为WEB浏览器中是以匿名用户(dr.who)登陆的,其只有只读权限,多数操作是做不了的。
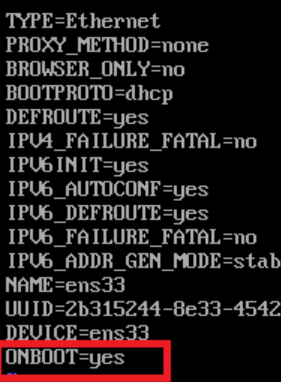
如果需要以特权用户在浏览器中进行操作,需要配置如下内容到core-site.xml并重启集群
<property>
<name>hadoop.http.staticuser.user</name>
<value>hadoop</value>
</property>
== 注意:不推荐这样做 ==
HDFS WEBUI,只读权限挺好的,简单浏览即可
如果给与高权限,会有很大的安全问题,造成数据泄露或丢失
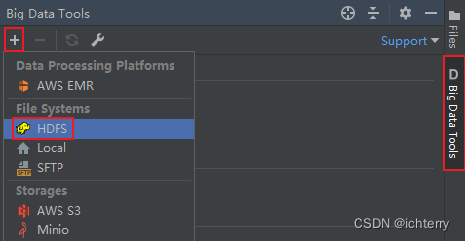
Big Data Tools插件
1、插件安装
在Jetbrains的产品中,均可以安装插件,其中:Big Data Tools插件可以帮助我们方便的操作HDFS,以下均支持Bigdata Tool插件,如
- IntelliJ IDEA(Java IDE)
- PyCharm(Python IDE)
- DataGrip(SQL IDE)
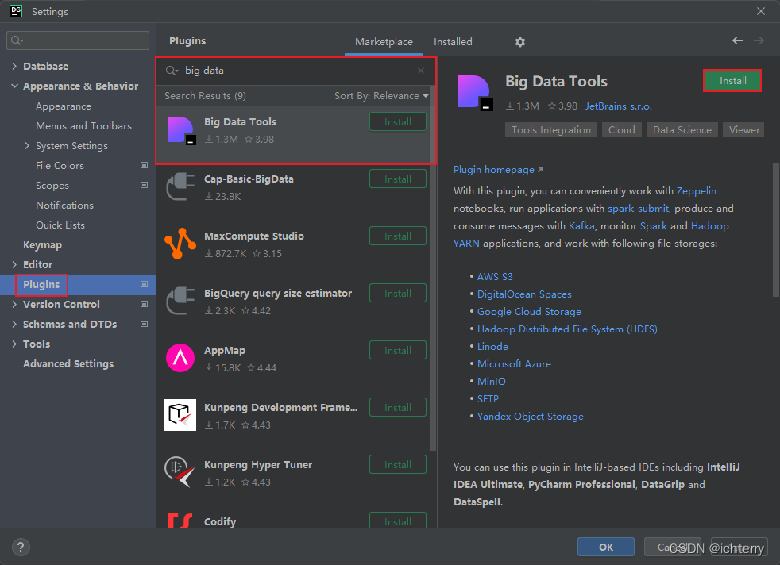
如图,在设置->Plugins(插件)-> Marketplace(市场),搜索Big Data Tools,点击Install安装即可
2、配置Windows
需要对Windows系统做一些基础设置,配合插件使用

![P8611 [蓝桥杯 2014 省 AB] 蚂蚁感冒](https://img-blog.csdnimg.cn/direct/a9ce92685fda4b3aa402b1b1e939403f.png#pic_center)