Apache Parquet是Apache Hadoop生态系统的一种免费的开源面向列的数据存储格式。 它类似于Hadoop中可用的其他列存储文件格式,如RCFile格式和ORC格式。本文将简单介绍一下Parquet文件的结构。
Parquet文件格式包含两部分:
data
metadata
数据首先写入文件,元数据最后写入单遍(single pass)写入。 首先让我们看一下Parquet文件的格式,然后再看一下元数据。
文件格式

HEADER
从整体上讲,Parquet包含一个header,一个或多个blocks 和一个footer。header和footer的最后包含了一个4-byte的魔术字(PAR1),这个魔术字表名此文件格式是Parquet格式。
所有的元数据信息保存在footer中。
DATA BLOCK
parquet文件中的块以嵌套结构的形式写入,如下所示
-Blocks
—Row Groups
—–Column Chunks
——-Page
parquet文件中的每个block以Row Group的形式存储。因此,parquet文件中的数据被划分为多个Row Group。这些Row Group由一个或多个column chunks组成,column chunks对应于数据集中的一列。每个column chunks的数据以page的形式写入。每个pages只包含特定列的值,因此pages是非常好的压缩候选对象,因为它们包含类似的值。

FOOTER
如上所述,文件元数据存储在footer中。
footer中的元数据包括version、schema、任何额外的键-值对,以及文件中列的元数据。列元数据包括类型、路径、编码、值的数量、压缩大小等。除了文件元数据之外,它还有一个4字节字段长度的footer length,以及一个4字节的魔术字(PAR1)。
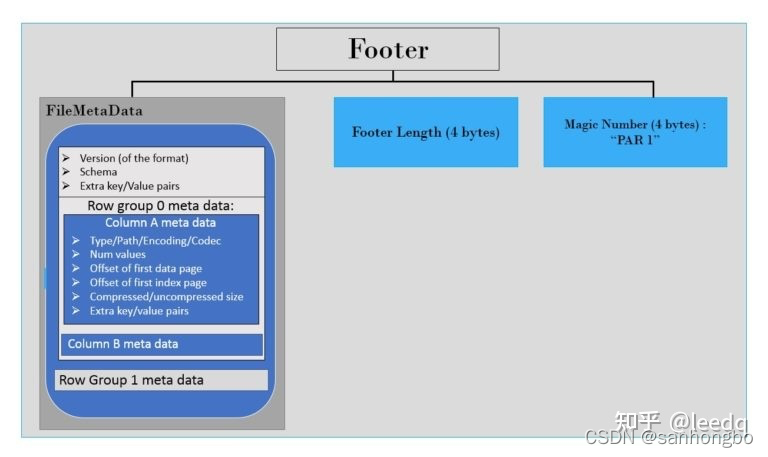
由于元数据存储在footer中,在读取parquet文件时,将首先查找footer metadata的长度,然后执行向后查找以读取元数据。
元数据是在所有块都写完之后才写的。