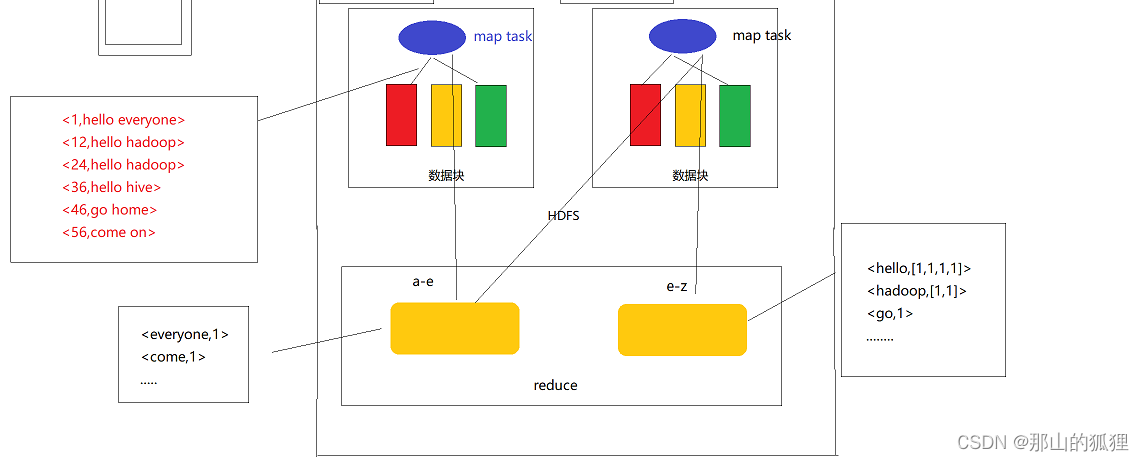
练习项目的代码地址:https://url56.ctfile.com/f/34653256-538963409-4254a0
一、基础环境要求:
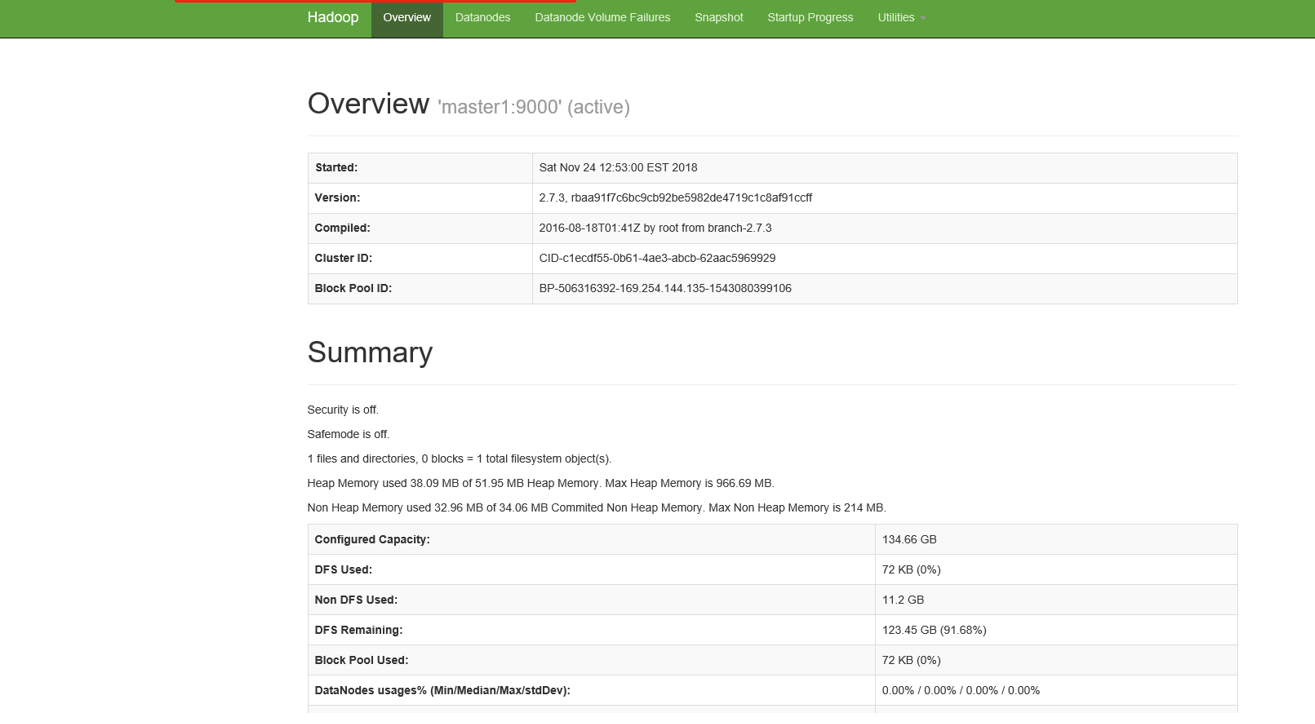
(一)首先保证虚拟机中Hadoop正常启动。
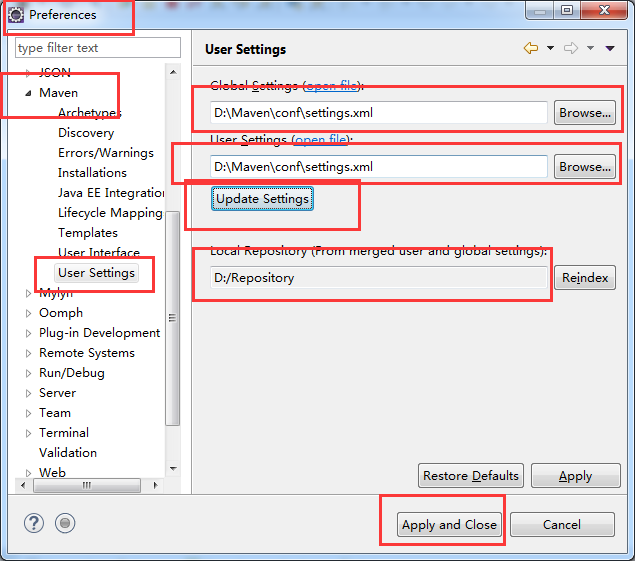
(二)Windows环境中是通过IDE(Eclipse) 创建项目,使用的是Maven环境,需要配置好并集成到IDE(Eclipse)中。
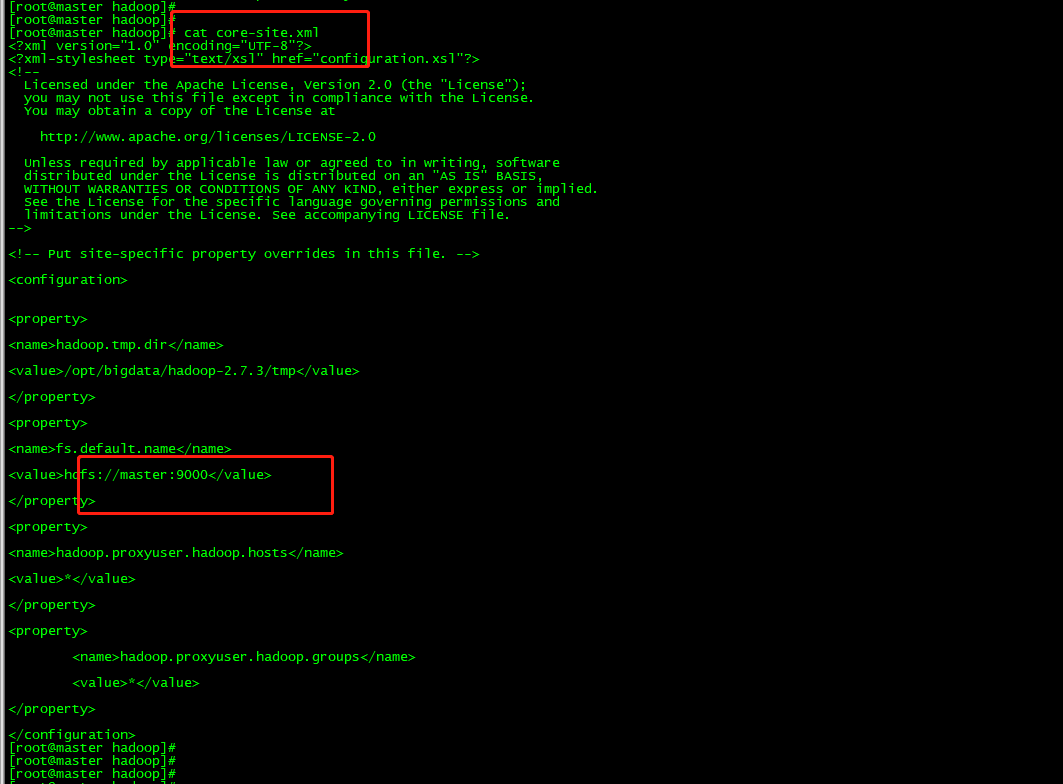
二、在Windows环境下可以对虚拟机中Linux环境下的HDFS进行操作。
(一)项目使用Maven创建,pom.xml配置文件如下:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 | <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.xlglvc.xxx.dsj</groupId>
<artifactId>hadooptest</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>hadooptest</name>
<description>hadooptest</description>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<hadoop.version>2.7.3</hadoop.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
</dependency>
</dependencies>
</project>
|
(二)代码:
1、集群中HDFS配置的是9000端口
2、创建主类
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 | package com.xlglvc.xxx.dsj.test;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import java.util.Arrays;
public class HadoopApp {
public static void main(String[] args) {
}
}
|
3、单独的方法
(1)创建目录:在IDE中执行代码可以在HDFS上创建文件夹。
代码如下:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 | private static void createDir01() {
String HDFS_PATH = "hdfs://192.168.155.100:9000/";
Configuration configuration = null;
FileSystem fileSystem = null;
configuration = new Configuration();
try {
fileSystem =FileSystem.get(new URI(HDFS_PATH),configuration,"root");
fileSystem.mkdirs(new Path("/HDFSJava"));//创建目录
} catch (Exception e) {
e.printStackTrace();
} finally {
fileSystem = null;
configuration = null;
System.out.println("--------------end---------------");
}
}
|
效果:运行代码后,目录已正确创建。
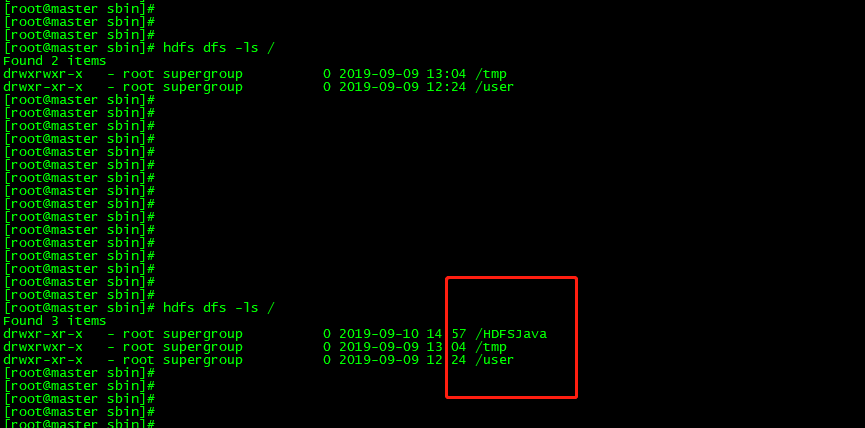
(2)创建文件:在IDE中执行代码可以在HDFS上创建文件。
代码如下:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 | private static void createFile02(){
String HDFS_PATH = "hdfs://192.168.155.100:9000/";
Configuration configuration = null;
FileSystem fileSystem = null;
configuration = new Configuration();
try {
fileSystem =FileSystem.get(new URI(HDFS_PATH),configuration,"root");
FSDataOutputStream output = fileSystem.create(new Path("/HDFSJava/mobiles.txt"));
output.write("111".getBytes());
output.flush();
output.close();
} catch (Exception e) {
e.printStackTrace();
} finally {
fileSystem = null;
configuration = null;
System.out.println("--------------end---------------");
}
}
|
效果:运行后查看文件,可以正确创建。

(3)重命名文件,在IDE中执行代码可以在HDFS上重命名文件。
代码如下:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 | private static void reameFile03(){
String HDFS_PATH = "hdfs://192.168.155.100:9000/";
Configuration configuration = null;
FileSystem fileSystem = null;
configuration = new Configuration();
try {
fileSystem =FileSystem.get(new URI(HDFS_PATH),configuration,"root");
Path oldPath = new Path("/HDFSJava/mobiles.txt");
Path newPath = new Path("/HDFSJava/newMobile.txt");
System.out.println(fileSystem.rename(oldPath,newPath));
} catch (Exception e) {
e.printStackTrace();
} finally {
fileSystem = null;
configuration = null;
System.out.println("--------------end---------------");
}
}
|
效果:查看文件已经重新命名。
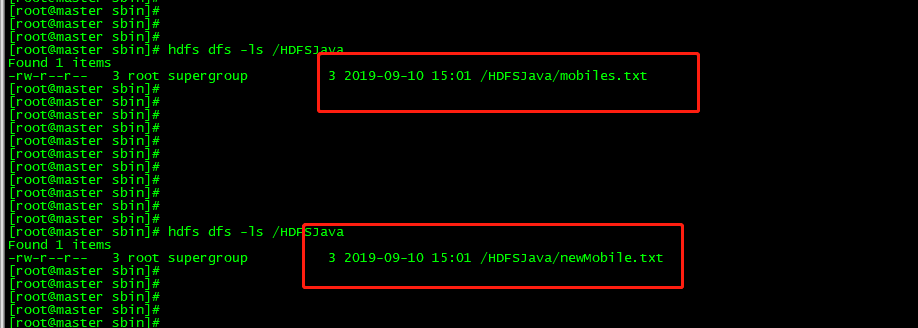
(4)将本地系统文件上传,在IDE中执行代码可以将Windows系统上的文件上传到Linux环境中的HDFS上。
代码如下:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 | private static void copyFromLocalFile04(){
String HDFS_PATH = "hdfs://192.168.155.100:9000/";
Configuration configuration = null;
FileSystem fileSystem = null;
configuration = new Configuration();
try {
fileSystem =FileSystem.get(new URI(HDFS_PATH),configuration,"root");
Path srcPath = new Path("E://errlog.txt");//本地系统上的目录
Path destPath = new Path("/HDFSJava");
fileSystem.copyFromLocalFile(srcPath,destPath);
} catch (Exception e) {
e.printStackTrace();
} finally {
fileSystem = null;
configuration = null;
System.out.println("--------------end---------------");
}
}
|
效果:查看本地系统的文件已经上传。

(5)查看指定目录下的所有文件,,在IDE中执行代码可以将Linux环境中的HDFS上的特定目录下的文件信息展示。
代码如下:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 | private static void listFiles05(){
String HDFS_PATH = "hdfs://192.168.155.100:9000/";
Configuration configuration = null;
FileSystem fileSystem = null;
configuration = new Configuration();
try {
fileSystem =FileSystem.get(new URI(HDFS_PATH),configuration,"root");
FileStatus[] list = fileSystem.listStatus(new Path("/HDFSJava"));//HDFSJava目录下
for (FileStatus fileStatus : list) {
String isDirectory = fileStatus.isDirectory()?"文件夹":"文件";
String permission = fileStatus.getPermission().toString();//权限
short replication = fileStatus.getReplication();//副本系数
long len = fileStatus.getLen();//长度
String path = fileStatus.getPath().toString();//路径
System.out.println(isDirectory + "\t" +permission+"\t"+ replication+"\t"+len+"\t"+path);
}
} catch (Exception e) {
e.printStackTrace();
} finally {
fileSystem = null;
configuration = null;
System.out.println("--------------end---------------");
}
}
|
效果:可以看到在Wndows环境下的IDE的打印区域,看到Linux中HDFS上的文件信息。

(6)查看上传的文件块信息,在IDE中执行代码可以查看Linux环境中的HDFS上的文件块信息。
代码如下:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 | private static void blockLocations06(){
String HDFS_PATH = "hdfs://192.168.155.100:9000/";
Configuration configuration = null;
FileSystem fileSystem = null;
configuration = new Configuration();
try {
fileSystem =FileSystem.get(new URI(HDFS_PATH),configuration,"root");
FileStatus fileStatus = fileSystem.getFileStatus(new Path(HDFS_PATH + "HDFSJava/errlog.txt"));
BlockLocation[] blockLocations = fileSystem.getFileBlockLocations(fileStatus,
0, fileStatus.getLen());
for (BlockLocation block : blockLocations) {
System.out.println(Arrays.toString(block.getHosts()) + "\t"
+ Arrays.toString(block.getNames()));
}
} catch (Exception e) {
e.printStackTrace();
} finally {
fileSystem = null;
configuration = null;
System.out.println("--------------end---------------");
}
}
|
效果:可以正确查看到文件的信息。