小白所写 , 写的不好 , 请大神指点
目录
1 . Hadoop中有三个核心组件 :
2 . 大数据的基本概念 :
处理海量数据的核心技术 :
分布式存储的框架:
分布式的计算框架:
辅助类工具有:
HDFS%C2%A0-toc" style="margin-left:0px;">3 . 分布式文件存储系统HDFS
HDFS%E7%9A%84%E7%AE%80%E5%8D%95API-toc" style="margin-left:0px;">4 . Hadoop集群Shell端操作HDFS的简单API
HDFS%E4%B8%AD%E8%A7%92%E8%89%B2%EF%BC%88NameNode%EF%BC%8CDataNode%EF%BC%8CSecondary%20NameNode%EF%BC%8C%E5%85%83%E6%95%B0%E6%8D%AE%EF%BC%89%E7%9A%84%E7%90%86%E8%A7%A3-toc" style="margin-left:0px;">5 . HDFS中角色(NameNode,DataNode,Secondary NameNode,元数据)的理解
HDFS%E7%9A%84%E5%B7%A5%E4%BD%9C%E6%9C%BA%E5%88%B6%EF%BC%88checkpoint%E6%9C%BA%E5%88%B6%EF%BC%89-toc" style="margin-left:0px;">6 . HDFS的工作机制(checkpoint机制)
HDFS%E7%9A%84%E5%AE%89%E5%85%A8%E6%9C%BA%E5%88%B6-toc" style="margin-left:0px;">7 . HDFS的安全机制
8 . Hadoop的安装及各配置文件的配置
1 . Hadoop中有三个核心组件 :
1.分布式文件存储系统 HDFS .
2.分布式文件运算编程框架 MapReduce .
3.分布式资源调度平台 yarn .
准备接下来用三篇文章分别详细介绍 HDFS , MapReduce , yarn .
2 . 大数据的基本概念 :
大数据通常用来形容一个公司创造的大量非结构化数据和半结构化数据,这些数据在下载到关系型数据库用于分析时会花费大量的时间和金钱 。即海量数据的处理 .
处理海量数据的核心技术 :
1 . 海量数据的存储 , 即分布式文件存储系统 HDFS .
2 . 海量数据的运算处理 , 即分布式运算框架 MapReduce .
3 . 分布式资源调度平台 , 即 yarn.
由此可见 , 数据的存储,运算,以及资源的调度,都是在分布式平台上进行,那么什么是分布式?
分布式就是将一个文件存储在很多机器上,其实就是有一个系统帮助我们存储文件,这个系统看起来是由目录组成的,即有一个真实的路径,但其实该路径和机器上文件的真实存路径是不相关的,在将文件放到这个系统的时候,系统会将文件切分成不同的文件块进行存储,存放在不同的机器上,而且每个文件块会有多个备份。存储文件的机器叫做datanode,此外还有一个namenode记录文件的存储信息。但其实用户并不知道。这就是分布式存储。
分布式存储的框架:
分布式文件存储系统HDFS
分布式数据库系统HBASE。
分布式的计算框架:
MapReduce计算框架 ---> Hadoop中的计算框架
Spark计算框架 ---> 做离线批处理,实时流式处理
Strom计算框架 ---> 做实时流式处理
辅助类工具有:
Hive ---> 数据仓库工具 : 可以接收SQL,将SQL语句解析成MapReduce或者Spark程序处理
Flume ---> 数据采集
Sqoop ---> 数据迁移
ElasticSearch ---> 分布式数据搜索引擎
HDFS%C2%A0">3 . 分布式文件存储系统HDFS
虽说是文件存储系统,但是其实是一个软件,是一个帮助用户存储文件的软件。
往系统中存储文件的时候,会有一个统一的路径,顶层目录是“/”,与Linux相似,但是Linux是单机系统,HDFS是多系统的文件存储系统。该目录不是指特定的某个机器上的某个某个目录而是在底层有很多机器组合在一起来支撑HDFS文件系统的一个顶层目录,用于存储用户上传的文件。
1 . HDFS是可以一次写入,多次读出的,但是不支持文件的修改。
2 . HDFS在物理上是分块(block)存储的,块的大小可以通过配置参数(dfs.blocksize)来设置。默认大小在Hadoop2.x版本中是128M,之前版本是64M。
3 . HDFS分布式文件存储系统会给客户端提供一个统一的抽象目录树,客户端通过路径来访问文件。
4 . NameNode是HDFS分布式文件存储系统的主节点,负责维护整个HDFS文件系统的目录树,以及每一个路径(文件)所对应的block块信息(块的id,块的大小,块的副本数以及块所在的服务器)
5 . Datanode会定期向Namenode汇报自身所保存的文件block信息,而namenode则会负责保持文件的副本数量
HDFS%E7%9A%84%E7%AE%80%E5%8D%95API">4 . Hadoop集群Shell端操作HDFS的简单API
1 . hdfs dfs -ls / 或者 hadoop fs -ls /
查看文件系统上的目录内容,查看的并不是Linux的根目录,而是HDFS文件存储系统的根目录。
2 . hdfs dfs -cat /word.txt
查看某个文件的内容
3 . hdfs dfs -put /word.txt /
将本地文件word.txt上传到HDFS的根目录
4 . hdfs dfs -get /word.txt /
下载HDFS根目录下的word.txt 文件到本地的根目录
5 . hdfs dfs -mkdir -p /hadoop/hdfs
在HDFS系统上递归创建多级目录
6 . hdfs dfs -mv /word.txt /hadoop/hdfs/
将HDFS系统根目录下的word.txt文件移动到/hadoop/hdfs/目录下
7 . hdfs dfs -rm -r /word.txt
递归删除文件或文件夹
8 . hdfs dfs -tail /word.txt 或者 hdfs dfs -cat /word.txt
查看文件内容
9 . hdfs dfs -cp /word.txt /hadoop
将一个文件复制到另一个位置
10 . hadoop fs -df -h /
统计文件系统的可用空间信息
11 . hadoop fs -du -s -h /aaa/*
统计文件夹的大小
HDFS%E4%B8%AD%E8%A7%92%E8%89%B2%EF%BC%88NameNode%EF%BC%8CDataNode%EF%BC%8CSecondary%20NameNode%EF%BC%8C%E5%85%83%E6%95%B0%E6%8D%AE%EF%BC%89%E7%9A%84%E7%90%86%E8%A7%A3">5 . HDFS中角色(NameNode,DataNode,Secondary NameNode,元数据)的理解
元数据 :
1 . 元数据包括HDFS文件系统的目录结构 , 每一个文件块的信息 (块ID , 块大小 , 块的副本数量 , 块的位置)
2 . 元数据记录在NameNode的工作目录里面 , NameNode将元数据记录在内存里面 , 内存中的元数据将定期序列化到本地磁盘中
NameNode :
1 . 用于记录 HDFS 文件系统存储的元数据
2 . 记录文件的信息 , 文件的大小 , 切分的块数 , 每一块的副本数和存储在DataNode上的位置
3 . NameNode 中的元数据目录下的 fsimage 文件是用来存储元数据的
4 . NameNode 中的元数据目录下的 VERSION 文件里面存储的是一系列的 ID ,相当于该集群的标识 .
DataNode :
1 . 用于存储用户上传的文件数据
2 . 数据是存储在该 NameNode 软件所在服务器的本地磁盘中
3 . DataNode 中的数据保存目录下的 VERSION 文件里面存储的一系列的 ID 跟 NameNode 里面的完全一致(说明他们是属于同一个集群的)
4 . DataNode 是怎么知道 NameNode 上面的集群ID是多少? DataNode启动之后会去读配置文件, 通过配置文件获取到 NameNode 的地址和内部请求端口 , 然后去跟 NameNode 联系 , 之后就会获取到 NameNode 的集群 ID .
Secondary NameNode :
1 . Secondary NameNode 定期的将 NameNode 上的 fsimage 的镜像文件下载到本地磁盘 , 同时将 edits 文件也下载到本地磁盘 , 定期的将fsimage反序列化到内存中 , 另外会启动一个程序去读取edits日志文件更新元数据 , 更新完元数据之后 , Secondary NameNode 会将更新完成的元数据序列化到本地磁盘中的 fsimage 中 , 并且编号为反序列化的是 edits 的最大编号 , 并将元数据上传到 NameNode 上(默认情况是一个小时同步一次)
HDFS%E7%9A%84%E5%B7%A5%E4%BD%9C%E6%9C%BA%E5%88%B6%EF%BC%88checkpoint%E6%9C%BA%E5%88%B6%EF%BC%89">6 . HDFS的工作机制(checkpoint机制)
1 . 用户上传的文件,被切分成多块分布式的存储在HDFS文件系统中的多个 DataNode 服务器上,而文件的大小,切分的块数,每一块的副本数和存储在 DataNode 上的位置以及存储在哪几个 DataNode 上,由 NameNode 记录(切分的文件块的大小可以自定义,2.0以后的版本默认128M,1.0版本默认64M)
2 . 客户端写数据到HDFS的流程

3 . 客户端从HDFS读数据的流程
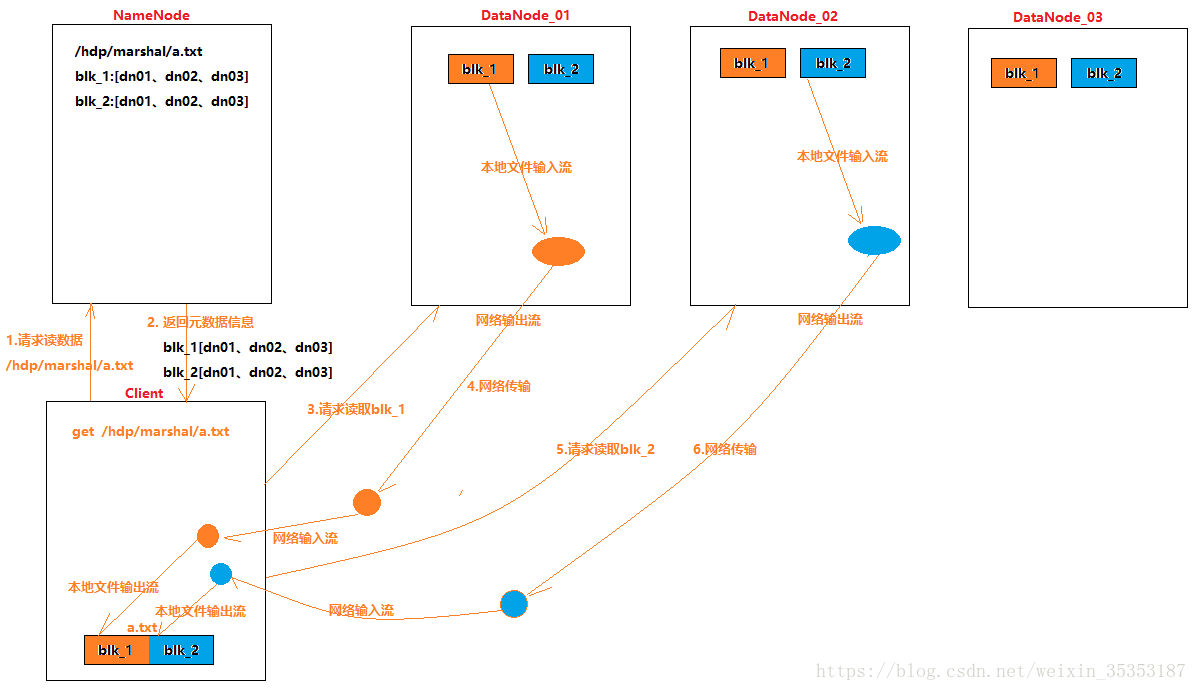
以上流程图来自多易教案
7 . HDFS的安全机制
为了保证数据的安全性,用户上传的文件被切分成多个文件块之后,可以保存多个副本(副本数量可以自己设置,默认3个)以增强文件的安全性。
namenode一旦进入安全模式,就无法再操作hdfs中的文件(上传、删除、改名、下载),只是可以查看目录
- namenode机器的资源问题(磁盘空间不足,内存不足)
- namenode觉得集群中的block丢失率超出>0.01%
(namenode是如何知道block丢失了多少?namenode元数据中记录了所有文件的所有block,然后datanode会定期向namenode汇报自身所持有的block信息)
引申:集群在启动的阶段,namenode会维持一段时间的安全模式!!!
安全模式的强行退出命令:hdfs dfsadmin -safemode leave
8 . Hadoop的安装及各配置文件的配置
各配置文件的配置及各个参数的意义参考文章:HDFS各个配置文件的参数配置及其参数意义
关于Hadoop的三大核心技术 :
分布式文件管理系统HDFS,分布式计算框架MapReduce,以及分布式资源管理调度平台YARN的文章请参考:
HDFS个人浅谈 : https://blog.csdn.net/weixin_35353187/article/details/82047892
MapReduce个人浅谈 : https://blog.csdn.net/weixin_35353187/article/details/82108388
YARN个人浅谈 : https://blog.csdn.net/weixin_35353187/article/details/82112174
Hadoop的各配置文件的配置以及参数的意义请参考文章 :
Hadoop的各个配置文件的配置 : https://blog.csdn.net/weixin_35353187/article/details/81780439