详细记录Linux服务器搭建Hadoop3高可用集群
- 搭建Hadoop3高可用集群
- 下载Hadoop
- 修改集群环境
- 修改配置文件
- 修改环境变量
- 分发软件到其他节点
- 启动Zookeeper
- 启动JournalNode
- 格式化NameNode
- 启动ZKFC
- 启动HDFS
- 启动yarn
- 查看进程
- 主备切换测试
- 作业测试
搭建Hadoop3高可用集群
| Hadoop节点 | NameNode-1 | NameNode-2 | DataNode | ResourceManager | NodeManager | Zookeeper | ZKFC | JouralNode |
|---|---|---|---|---|---|---|---|---|
| node001 | * | * | * | * | * | * | * | |
| node002 | * | * | * | * | * | * | ||
| node003 | * | * | * | * | * |
下载Hadoop
下载地址:https://archive.apache.org/dist/hadoop/core/
cd /usr/local/program
wget https://archive.apache.org/dist/hadoop/core/hadoop-3.1.3/hadoop-3.1.3.tar.gz
tar -zxvf hadoop-3.1.3.tar.gz
mv hadoop-3.1.3 hadoop
修改集群环境
vim hadoop-env.sh
export JAVA_HOME=/usr/local/program/jdk8
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_ZKFC_USER=root
export HDFS_JOURNALNODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
修改配置文件
vim core-site.xml
<configuration>
<!-- 声明hdfs文件系统 指定某个ip地址,在ha模式中指定hdfs集群的逻辑名称 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://my-hdfs</value>
</property>
<!-- 声明hadoop工作目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/program/hadoop/datas/tmp</value>
</property>
<!--默认用户Root-->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<!-- 指定zookeeper集群的地址,用于管理hdfs集群 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>node001:2181,node002:2181,node003:2181</value>
</property>
</configuration>
vim hdfs-site.xml
<configuration>
<!-- 指定逻辑名称,自动寻找NameNode节点 -->
<property>
<name>dfs.nameservices</name>
<value>my-hdfs</value>
</property>
<!-- 把定义的逻辑名称指向各个namenode的别名 -->
<property>
<name>dfs.ha.namenodes.my-hdfs</name>
<value>nn1,nn2</value>
</property>
<!--NameNode远程调用地址-->
<property>
<name>dfs.namenode.rpc-address.my-hdfs.nn1</name>
<value>node001:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.my-hdfs.nn2</name>
<value>node002:8020</value>
</property>
<!-- 指定namenode别名对应的IP地址即NameNode连接地址-->
<property>
<name>dfs.namenode.http-address.my-hdfs.nn1</name>
<value>node001:9870</value>
</property>
<property>
<name>dfs.namenode.http-address.my-hdfs.nn2</name>
<value>node002:9870</value>
</property>
<!-- 配置JournalNode集群的地址 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node001:8485;node002:8485;node003:8485/my-hdfs</value>
</property>
<!-- 指定JouralNode节点存放编辑日志的存储路径-->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/usr/local/program/hadoop/datas/qjm</value>
</property>
<!-- 开启自动故障转移功能 -->
<property>
<name>dfs.client.failover.proxy.provider.my-hdfs</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 指定ha出现故障时的隔离方法 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
<value>shell(true)</value>
</property>
<!-- 指定隔离主机的私钥路径(主备节点间相互免密钥,指定私匙地址)-->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!-- 开启自动故障转移功能 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!--副本数量,默认3个-->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>
vim workers
node001
node002
node003
vim mapred-site.xml
<configuration>
<!-- 指定mr框架为yarn -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 指定mapreduce jobhistory地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>node001:10020</value>
</property>
<!-- 任务历史服务器的web地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node001:19888</value>
</property>
<!-- 配置运行过的日志存放在hdfs上的存放路径 -->
<property>
<name>mapreduce.jobhistory.done-dir</name>
<value>/history/done</value>
</property>
<!-- 配置正在运行中的日志在hdfs上的存放路径 -->
<property>
<name>mapreudce.jobhistory.intermediate.done-dir</name>
<value>/history/done/done_intermediate</value>
</property>
<!--以下必须配置,否则运行MapReduce会提示检查是否配置-->
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/program/hadoop</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/program/hadoop</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/program/hadoop</value>
</property>
</configuration>
vim yarn-site.xml
<configuration>
<!-- 开启RM高可用 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 指定RM的cluster id -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>my-hdfs</value>
</property>
<!-- 指定RM的名字 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 分别指定RM的地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>node001</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>node003</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>node001:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>node003:8088</value>
</property>
<!-- 指定zk集群地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>node001:2181,node002:2181,node003:2181</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 开启日志聚合 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>86400</value>
</property>
<!-- 启用自动恢复 -->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!-- 制定resourcemanager的状态信息存储在zookeeper集群上 -->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<!-- 是否对虚拟内存限制 -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!-- 物理内存不够,大量占用虚拟内存,超过一定比例则报错 -->
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>3</value>
</property>
</configuration>
修改环境变量
vim /etc/profile
export HADOOP_HOME=/usr/local/program/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
将环境变量配置同步到其他节点
scp /etc/profile node002:/etc/profile
scp /etc/profile node003:/etc/profile
重新加载三台服务器的环境变量配置
source /etc/profile
分发软件到其他节点
scp -r hadoop node002:`pwd`
scp -r hadoop node003:/usr/local/program
启动Zookeeper
Zookeeper集群安装
启动JournalNode
所有节点都启动JournalNode
[root@node001 hadoop]# hdfs --daemon start journalnode
WARNING: /usr/local/program/hadoop/logs does not exist. Creating.
[root@node001 hadoop]# ls
bin datas etc include lib libexec LICENSE.txt logs NOTICE.txt README.txt sbin share
drwxr-xr-x 2 root root 4096 Apr 10 22:29 qjm
[root@node001 hadoop]# ll datas/qjm/
total 0
格式化NameNode
[root@node001 hadoop]# hdfs namenode -format
************************************************************/
2022-04-10 22:38:39,922 INFO namenode.NameNode: registered UNIX signal handlers for [TERM, HUP, INT]
2022-04-10 22:38:40,004 INFO namenode.NameNode: createNameNode [-format]
Java HotSpot(TM) Server VM warning: You have loaded library /usr/local/program/hadoop/lib/native/libhadoop.so.1.0.0 which might have disabled stack guard. The VM will try to fix the stack guard now.
It's highly recommended that you fix the library with 'execstack -c <libfile>', or link it with '-z noexecstack'.
2022-04-10 22:38:40,112 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Formatting using clusterid: CID-a5a06459-360f-4d62-855d-e0c3db1654d4
2022-04-10 22:38:40,528 INFO namenode.FSEditLog: Edit logging is async:true
2022-04-10 22:38:40,543 INFO namenode.FSNamesystem: KeyProvider: null
2022-04-10 22:38:40,544 INFO namenode.FSNamesystem: fsLock is fair: true
2022-04-10 22:38:40,545 INFO namenode.FSNamesystem: Detailed lock hold time metrics enabled: false
2022-04-10 22:38:40,550 INFO namenode.FSNamesystem: fsOwner = root (auth:SIMPLE)
2022-04-10 22:38:40,550 INFO namenode.FSNamesystem: supergroup = supergroup
2022-04-10 22:38:40,550 INFO namenode.FSNamesystem: isPermissionEnabled = true
2022-04-10 22:38:40,550 INFO namenode.FSNamesystem: Determined nameservice ID: my-hdfs
2022-04-10 22:38:40,550 INFO namenode.FSNamesystem: HA Enabled: true
2022-04-10 22:38:40,591 INFO common.Util: dfs.datanode.fileio.profiling.sampling.percentage set to 0. Disabling file IO profiling
2022-04-10 22:38:40,611 INFO blockmanagement.DatanodeManager: dfs.block.invalidate.limit: configured=1000, counted=60, effected=1000
2022-04-10 22:38:40,611 INFO blockmanagement.DatanodeManager: dfs.namenode.datanode.registration.ip-hostname-check=true
2022-04-10 22:38:40,616 INFO blockmanagement.BlockManager: dfs.namenode.startup.delay.block.deletion.sec is set to 000:00:00:00.000
2022-04-10 22:38:40,616 INFO blockmanagement.BlockManager: The block deletion will start around 2022 Apr 10 22:38:40
2022-04-10 22:38:40,618 INFO util.GSet: Computing capacity for map BlocksMap
2022-04-10 22:38:40,618 INFO util.GSet: VM type = 32-bit
2022-04-10 22:38:40,619 INFO util.GSet: 2.0% max memory 810.8 MB = 16.2 MB
2022-04-10 22:38:40,619 INFO util.GSet: capacity = 2^22 = 4194304 entries
2022-04-10 22:38:40,627 INFO blockmanagement.BlockManager: dfs.block.access.token.enable = false
2022-04-10 22:38:40,633 INFO Configuration.deprecation: No unit for dfs.namenode.safemode.extension(30000) assuming MILLISECONDS
2022-04-10 22:38:40,633 INFO blockmanagement.BlockManagerSafeMode: dfs.namenode.safemode.threshold-pct = 0.9990000128746033
2022-04-10 22:38:40,633 INFO blockmanagement.BlockManagerSafeMode: dfs.namenode.safemode.min.datanodes = 0
2022-04-10 22:38:40,634 INFO blockmanagement.BlockManagerSafeMode: dfs.namenode.safemode.extension = 30000
2022-04-10 22:38:40,634 INFO blockmanagement.BlockManager: defaultReplication = 2
2022-04-10 22:38:40,634 INFO blockmanagement.BlockManager: maxReplication = 512
2022-04-10 22:38:40,634 INFO blockmanagement.BlockManager: minReplication = 1
2022-04-10 22:38:40,634 INFO blockmanagement.BlockManager: maxReplicationStreams = 2
2022-04-10 22:38:40,634 INFO blockmanagement.BlockManager: redundancyRecheckInterval = 3000ms
2022-04-10 22:38:40,634 INFO blockmanagement.BlockManager: encryptDataTransfer = false
2022-04-10 22:38:40,634 INFO blockmanagement.BlockManager: maxNumBlocksToLog = 1000
2022-04-10 22:38:40,655 INFO namenode.FSDirectory: GLOBAL serial map: bits=24 maxEntries=16777215
2022-04-10 22:38:40,670 INFO util.GSet: Computing capacity for map INodeMap
2022-04-10 22:38:40,670 INFO util.GSet: VM type = 32-bit
2022-04-10 22:38:40,670 INFO util.GSet: 1.0% max memory 810.8 MB = 8.1 MB
2022-04-10 22:38:40,670 INFO util.GSet: capacity = 2^21 = 2097152 entries
2022-04-10 22:38:40,671 INFO namenode.FSDirectory: ACLs enabled? false
2022-04-10 22:38:40,671 INFO namenode.FSDirectory: POSIX ACL inheritance enabled? true
2022-04-10 22:38:40,671 INFO namenode.FSDirectory: XAttrs enabled? true
2022-04-10 22:38:40,672 INFO namenode.NameNode: Caching file names occurring more than 10 times
2022-04-10 22:38:40,676 INFO snapshot.SnapshotManager: Loaded config captureOpenFiles: false, skipCaptureAccessTimeOnlyChange: false, snapshotDiffAllowSnapRootDescendant: true, maxSnapshotLimit: 65536
2022-04-10 22:38:40,678 INFO snapshot.SnapshotManager: SkipList is disabled
2022-04-10 22:38:40,682 INFO util.GSet: Computing capacity for map cachedBlocks
2022-04-10 22:38:40,682 INFO util.GSet: VM type = 32-bit
2022-04-10 22:38:40,682 INFO util.GSet: 0.25% max memory 810.8 MB = 2.0 MB
2022-04-10 22:38:40,682 INFO util.GSet: capacity = 2^19 = 524288 entries
2022-04-10 22:38:40,689 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.window.num.buckets = 10
2022-04-10 22:38:40,689 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.num.users = 10
2022-04-10 22:38:40,689 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.windows.minutes = 1,5,25
2022-04-10 22:38:40,693 INFO namenode.FSNamesystem: Retry cache on namenode is enabled
2022-04-10 22:38:40,693 INFO namenode.FSNamesystem: Retry cache will use 0.03 of total heap and retry cache entry expiry time is 600000 millis
2022-04-10 22:38:40,694 INFO util.GSet: Computing capacity for map NameNodeRetryCache
2022-04-10 22:38:40,694 INFO util.GSet: VM type = 32-bit
2022-04-10 22:38:40,694 INFO util.GSet: 0.029999999329447746% max memory 810.8 MB = 249.1 KB
2022-04-10 22:38:40,694 INFO util.GSet: capacity = 2^16 = 65536 entries
2022-04-10 22:38:41,459 INFO namenode.FSImage: Allocated new BlockPoolId: BP-1518036941-172.29.234.1-1649601521458
2022-04-10 22:38:41,468 INFO common.Storage: Storage directory /usr/local/program/hadoop/datas/tmp/dfs/name has been successfully formatted.
2022-04-10 22:38:41,550 INFO namenode.FSImageFormatProtobuf: Saving image file /usr/local/program/hadoop/datas/tmp/dfs/name/current/fsimage.ckpt_0000000000000000000 using no compression
2022-04-10 22:38:41,627 INFO namenode.FSImageFormatProtobuf: Image file /usr/local/program/hadoop/datas/tmp/dfs/name/current/fsimage.ckpt_0000000000000000000 of size 388 bytes saved in 0 seconds .
2022-04-10 22:38:41,635 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
2022-04-10 22:38:41,653 INFO namenode.FSImage: FSImageSaver clean checkpoint: txid = 0 when meet shutdown.
2022-04-10 22:38:41,653 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at node001/172.29.234.1
************************************************************/
[root@node001 hadoop]# ll datas/tmp/dfs/name/current/
total 16
-rw-r--r-- 1 root root 388 Apr 10 22:38 fsimage_0000000000000000000
-rw-r--r-- 1 root root 62 Apr 10 22:38 fsimage_0000000000000000000.md5
-rw-r--r-- 1 root root 2 Apr 10 22:38 seen_txid
-rw-r--r-- 1 root root 215 Apr 10 22:38 VERSION
启动node001的NameNode
[root@node001 hadoop]# hdfs --daemon start namenode
[root@node001 hadoop]# jps
515 NameNode
615 Jps
30187 JournalNode
25517 QuorumPeerMain
启动node002的备用NameNode
[root@node002 hadoop]# hdfs namenode -bootstrapStandby
STARTUP_MSG: java = 1.8.0_321
************************************************************/
2022-04-16 22:24:47,779 INFO namenode.NameNode: registered UNIX signal handlers for [TERM, HUP, INT]
2022-04-16 22:24:47,865 INFO namenode.NameNode: createNameNode [-bootstrapStandby]
2022-04-16 22:24:47,977 INFO ha.BootstrapStandby: Found nn: nn1, ipc: node001/172.29.234.1:8020
Java HotSpot(TM) Server VM warning: You have loaded library /usr/local/program/hadoop/lib/native/libhadoop.so which might have disabled stack guard. The VM will try to fix the stack guard now.
It's highly recommended that you fix the library with 'execstack -c <libfile>', or link it with '-z noexecstack'.
2022-04-16 22:24:48,367 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
=====================================================
About to bootstrap Standby ID nn2 from:
Nameservice ID: my-hdfs
Other Namenode ID: nn1
Other NN's HTTP address: http://node001:9870
Other NN's IPC address: node001/172.29.234.1:8020
Namespace ID: 1859445341
Block pool ID: BP-1879252727-172.29.234.1-1650119036916
Cluster ID: CID-2c62e424-b2fb-494a-8331-03f4f789042e
Layout version: -64
isUpgradeFinalized: true
=====================================================
2022-04-16 22:24:48,700 INFO common.Storage: Storage directory /usr/local/program/hadoop/datas/tmp/dfs/name has been successfully formatted.
2022-04-16 22:24:48,758 INFO namenode.FSEditLog: Edit logging is async:true
2022-04-16 22:24:48,831 INFO namenode.TransferFsImage: Opening connection to http://node001:9870/imagetransfer?getimage=1&txid=0&storageInfo=-64:1859445341:1650119036916:CID-2c62e424-b2fb-494a-8331-03f4f789042e&bootstrapstandby=true
2022-04-16 22:24:48,921 INFO common.Util: Combined time for file download and fsync to all disks took 0.00s. The file download took 0.00s at 0.00 KB/s. Synchronous (fsync) write to disk of /usr/local/program/hadoop/datas/tmp/dfs/name/current/fsimage.ckpt_0000000000000000000 took 0.00s.
2022-04-16 22:24:48,921 INFO namenode.TransferFsImage: Downloaded file fsimage.ckpt_0000000000000000000 size 391 bytes.
2022-04-16 22:24:48,934 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at node002/172.29.234.2
************************************************************/
启动ZKFC
[root@node001 hadoop]# hdfs zkfc -formatZK
2022-04-16 22:26:39,842 INFO zookeeper.ZooKeeper: Client environment:java.library.path=/usr/local/program/hadoop/lib/native
2022-04-16 22:26:39,842 INFO zookeeper.ZooKeeper: Client environment:java.io.tmpdir=/tmp
2022-04-16 22:26:39,842 INFO zookeeper.ZooKeeper: Client environment:java.compiler=<NA>
2022-04-16 22:26:39,842 INFO zookeeper.ZooKeeper: Client environment:os.name=Linux
2022-04-16 22:26:39,842 INFO zookeeper.ZooKeeper: Client environment:os.arch=i386
2022-04-16 22:26:39,842 INFO zookeeper.ZooKeeper: Client environment:os.version=3.10.0-957.21.3.el7.x86_64
2022-04-16 22:26:39,842 INFO zookeeper.ZooKeeper: Client environment:user.name=root
2022-04-16 22:26:39,842 INFO zookeeper.ZooKeeper: Client environment:user.home=/root
2022-04-16 22:26:39,842 INFO zookeeper.ZooKeeper: Client environment:user.dir=/usr/local/program/hadoop
2022-04-16 22:26:39,843 INFO zookeeper.ZooKeeper: Initiating client connection, connectString=node001:2181,node002:2181,node003:2181 sessionTimeout=10000 watcher=org.apache.hadoop.ha.ActiveStandbyElector$WatcherWithClientRef@1862a7f
2022-04-16 22:26:39,857 INFO zookeeper.ClientCnxn: Opening socket connection to server node003/172.29.234.3:2181. Will not attempt to authenticate using SASL (unknown error)
2022-04-16 22:26:39,862 INFO zookeeper.ClientCnxn: Socket connection established to node003/172.29.234.3:2181, initiating session
2022-04-16 22:26:39,881 INFO zookeeper.ClientCnxn: Session establishment complete on server node003/172.29.234.3:2181, sessionid = 0x3000112ea4a0000, negotiated timeout = 10000
2022-04-16 22:26:39,883 INFO ha.ActiveStandbyElector: Session connected.
2022-04-16 22:26:39,907 INFO ha.ActiveStandbyElector: Successfully created /hadoop-ha/my-hdfs in ZK.
2022-04-16 22:26:39,910 INFO zookeeper.ZooKeeper: Session: 0x3000112ea4a0000 closed
2022-04-16 22:26:39,912 INFO zookeeper.ClientCnxn: EventThread shut down for session: 0x3000112ea4a0000
2022-04-16 22:26:39,913 INFO tools.DFSZKFailoverController: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down DFSZKFailoverController at node001/172.29.234.1
************************************************************/
启动HDFS
[root@node001 hadoop]# start-dfs.sh
[root@node001 hadoop]# start-dfs.sh
Starting namenodes on [node001 node002]
Last login: Sun Apr 10 22:58:05 CST 2022 on pts/2
Starting datanodes
Last login: Sun Apr 10 22:58:10 CST 2022 on pts/2
Starting journal nodes [node003 node002 node001]
Last login: Sun Apr 10 22:58:13 CST 2022 on pts/2
Java HotSpot(TM) Server VM warning: You have loaded library /usr/local/program/hadoop/lib/native/libhadoop.so.1.0.0 which might have disabled stack guard. The VM will try to fix the stack guard now.
It's highly recommended that you fix the library with 'execstack -c <libfile>', or link it with '-z noexecstack'.
2022-04-10 22:58:20,804 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Starting ZK Failover Controllers on NN hosts [node001 node002]
Last login: Sun Apr 10 22:58:17 CST 2022 on pts/2
启动yarn
start-yarn.sh
stop-yarn.sh
查看进程
[root@node001 hadoop]# start-yarn.sh
Starting resourcemanagers on [ node001 node003]
Last login: Sat Apr 16 22:27:10 CST 2022 on pts/0
Starting nodemanagers
Last login: Sat Apr 16 22:28:59 CST 2022 on pts/0
[root@node001 hadoop]# jps
18946 QuorumPeerMain
25123 NameNode
26628 DFSZKFailoverController
26182 DataNode
27368 ResourceManager
27561 NodeManager
24666 JournalNode
27965 Jps
[root@node002 hadoop]# jps
26515 Jps
25939 NameNode
21860 QuorumPeerMain
26055 DataNode
26217 DFSZKFailoverController
26398 NodeManager
25247 JournalNode
[root@node003 hadoop]# jps
28421 NodeManager
28327 ResourceManager
27783 DataNode
28727 Jps
24650 QuorumPeerMain
27583 JournalNode
访问 node001:7890
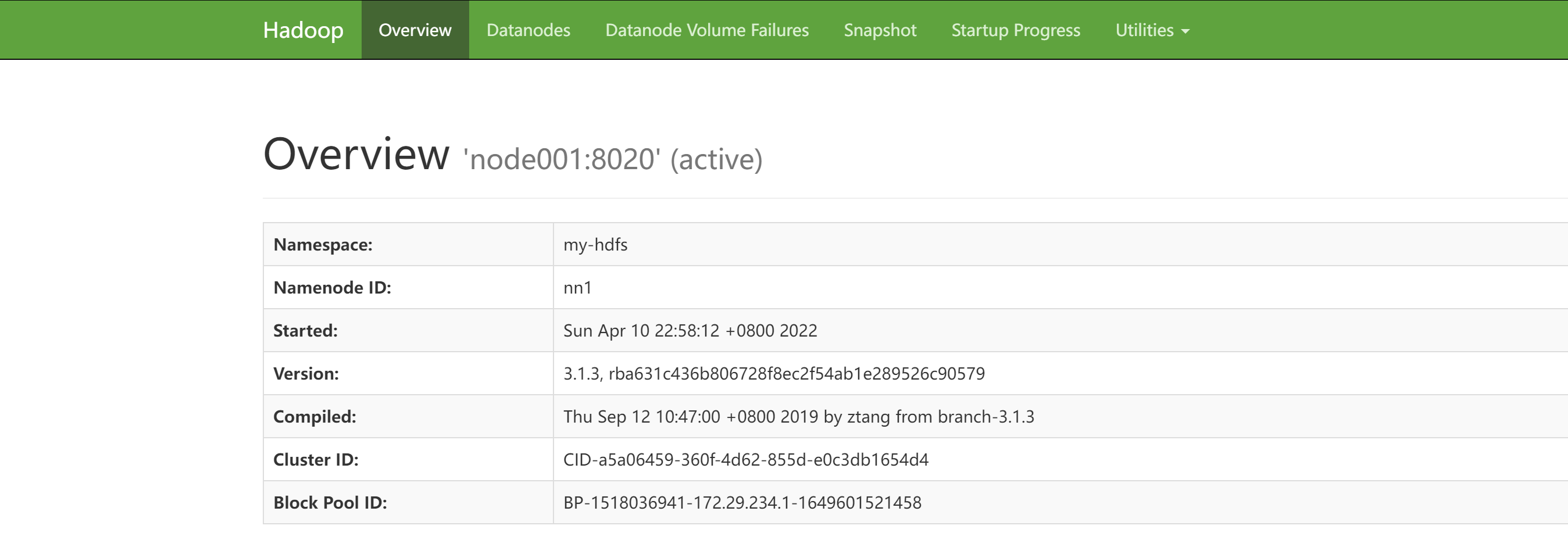
访问 node002:7890
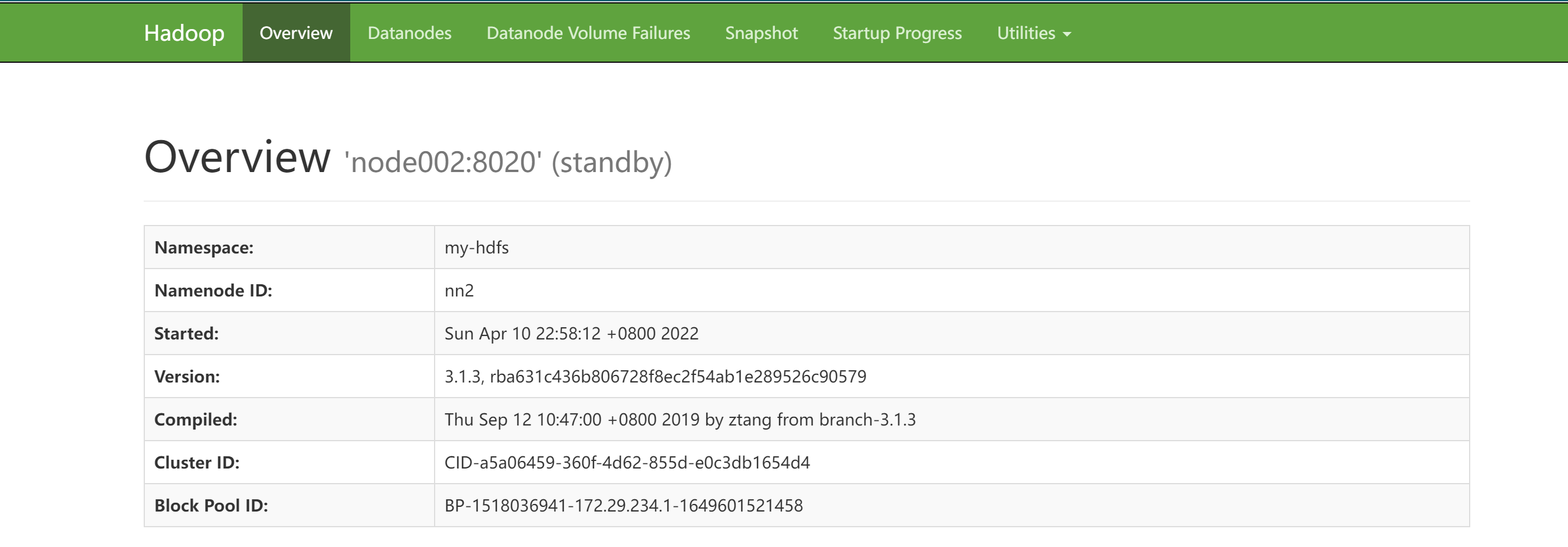
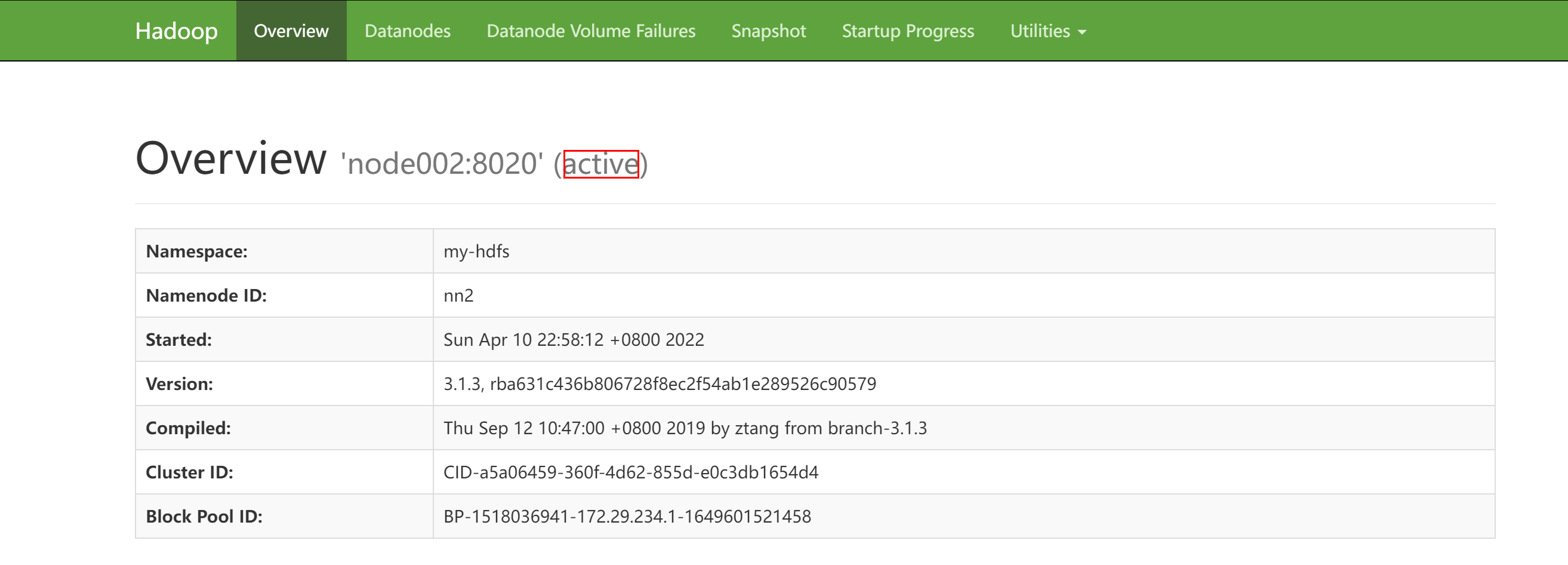
主备切换测试
node001停止NameNode
[root@node001 hadoop]# hdfs --daemon stop namenode
作业测试
[root@node001 hadoop]# hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input /output
2022-04-16 22:37:17,206 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/root/.staging/job_1650119343361_0002
2022-04-16 22:37:17,414 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
2022-04-16 22:37:18,125 INFO input.FileInputFormat: Total input files to process : 0
2022-04-16 22:37:18,153 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
2022-04-16 22:37:18,340 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
2022-04-16 22:37:18,758 INFO mapreduce.JobSubmitter: number of splits:0
2022-04-16 22:37:18,872 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
2022-04-16 22:37:19,308 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1650119343361_0002
2022-04-16 22:37:19,308 INFO mapreduce.JobSubmitter: Executing with tokens: []
2022-04-16 22:37:19,473 INFO conf.Configuration: resource-types.xml not found
2022-04-16 22:37:19,474 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2022-04-16 22:37:19,545 INFO impl.YarnClientImpl: Submitted application application_1650119343361_0002
2022-04-16 22:37:19,587 INFO mapreduce.Job: The url to track the job: http://node003:8088/proxy/application_1650119343361_0002/
2022-04-16 22:37:19,587 INFO mapreduce.Job: Running job: job_1650119343361_0002
2022-04-16 22:37:25,682 INFO mapreduce.Job: Job job_1650119343361_0002 running in uber mode : false
2022-04-16 22:37:25,683 INFO mapreduce.Job: map 0% reduce 0%
2022-04-16 22:37:31,809 INFO mapreduce.Job: map 0% reduce 100%
2022-04-16 22:37:32,821 INFO mapreduce.Job: Job job_1650119343361_0002 completed successfully
2022-04-16 22:37:32,895 INFO mapreduce.Job: Counters: 40
File System Counters
FILE: Number of bytes read=0
FILE: Number of bytes written=220867
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=0
HDFS: Number of bytes written=0
HDFS: Number of read operations=5
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched reduce tasks=1
Total time spent by all maps in occupied slots (ms)=0
Total time spent by all reduces in occupied slots (ms)=3165
Total time spent by all reduce tasks (ms)=3165
Total vcore-milliseconds taken by all reduce tasks=3165
Total megabyte-milliseconds taken by all reduce tasks=3240960
Map-Reduce Framework
Combine input records=0
Combine output records=0
Reduce input groups=0
Reduce shuffle bytes=0
Reduce input records=0
Reduce output records=0
Spilled Records=0
Shuffled Maps =0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=70
CPU time spent (ms)=240
Physical memory (bytes) snapshot=164323328
Virtual memory (bytes) snapshot=1358331904
Total committed heap usage (bytes)=167247872
Peak Reduce Physical memory (bytes)=164323328
Peak Reduce Virtual memory (bytes)=1358331904
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Output Format Counters
Bytes Written=0
HDFS存储记录

作业日志信息