Tez简介
Tez是一个Hive的运行引擎,由于没有中间存盘的过程,性能优于MR。Tez可以将多个依赖作业转换成一个作业,这样只需要写一次HDFS,中间节点少,提高作业的计算性能。

Tez的安装步骤
1)下载安装包到hive所在的66服务器,然后解压缩。
wget https://mirrors.bfsu.edu.cn/apache/tez/0.10.0/apache-tez-0.10.0-bin.tar.gz
tar -xzvf apache-tez-0.10.0-bin.tar.gz2)在HIVE中配置tez
2.1)修改hive-env.sh文件,添加如下配置,然后将tez的jar复制到hive 的lib目录下
[user@NewBieMaster conf]$ cat hive-env.sh
。。。。。。
export TEZ_HOME=/home/user/apache-tez #tez解压目录
export TEZ_JARS=""
for jar in `ls $TEZ_HOME |grep jar`; do
export TEZ_JARS=$TEZ_JARS:$TEZ_HOME/$jar
done
for jar in `ls $TEZ_HOME/lib`; do
export TEZ_JARS=$TEZ_JARS:$TEZ_HOME/lib/$jar
done
export HIVE_AUX_JARS_PATH=/home/user/hadoop-3.2.2/share/hadoop/common/hadoop-lzo-0.4.21-SNAPSHOT.jar$TEZ_JARS
[user@NewBieSlave1 conf]$
[user@NewBieMaster apache-tez]$ cp -ri /home/user/apache-tez/*.jar /home/user/apache-hive/lib/
[user@NewBieMaster apache-tez]$ cp -ri /home/user/apache-tez/lib/*.jar /home/user/apache-hive/lib/
2.2)修改hive-default.xml文件,修改计算引擎为tez。

2.3)创建tez-site.xml文件并添加如下内容。
[user@NewBieSlave1 conf]$ cat tez-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xml"?>
<configuration>
<property>
<name>tez.lib.uris</name>
<value>${fs.defaultFS}/tez/apache-tez-0.10.0-bin.tar.gz</value>
</property>
<!--tez是否可用Hadoop的jar包 -->
<property>
<name>tez.use.cluster.hadoop-libs</name>
<value>true</value>
</property>
<property>
<name>tez.history.logging.service.class</name>
<value>org.apache.tez.dag.history.logging.ats.ATSHistoryLoggingService</value>
</property>
</configuration>
[user@NewBieSlave1 conf]$
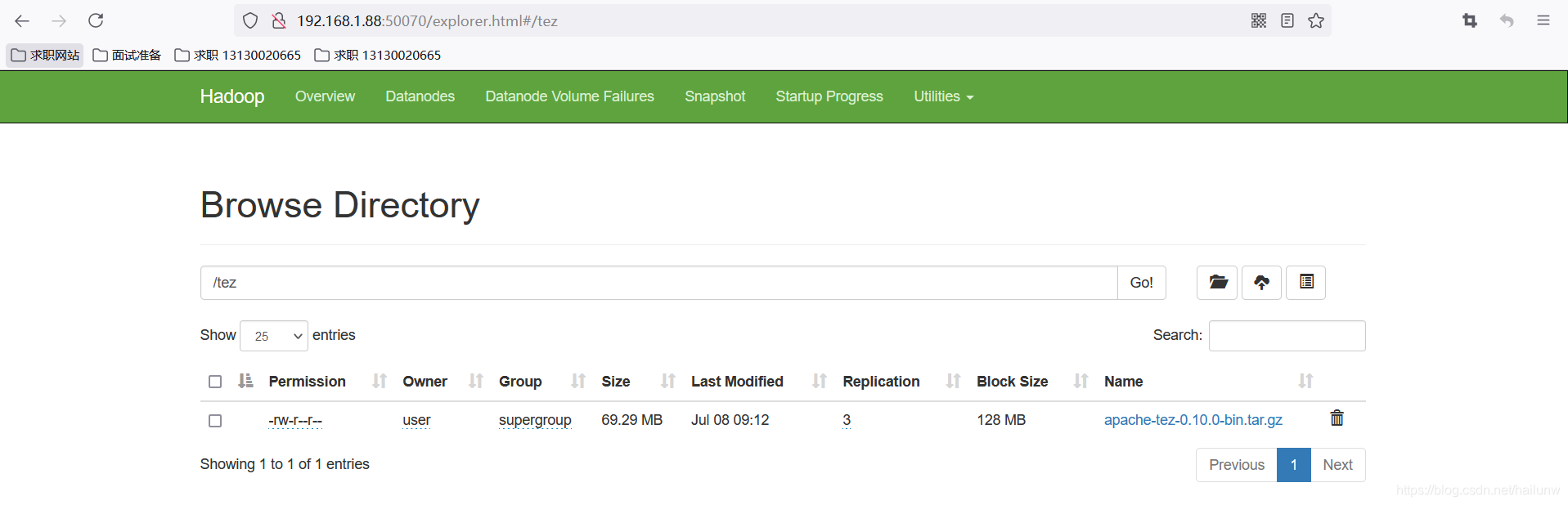
3)将/home/user/apache-tez传到HDFS的/tez路径,并且测试配置是否成功。
[user@NewBieMaster conf]$ hadoop fs -mkdir /tez
hive> create table student (int[user@NewBieSlave1 lib]$ hive
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/home/user/apache-tez/lib/slf4j-log4j12-1.7.10.jar.bkp!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/home/user/apache-tez/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/home/user/hadoop-3.2.2/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
which: no hbase in (/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/home/user/.local/bin:/home/user/bin:/home/user/jdk1.8.0_202/jre/bin:/home/user/jdk1.8.0_202/bin:/home/user/hadoop-3.2.2/bin:/home/user/hadoop-3.2.2/sbin:/home/user/apache-hive/bin:/home/user/apache-hive/sbin:/home/user/apache-zookeeper/bin:/home/user/spark-3.1.2-bin-hadoop3.2/bin:/home/user/spark-3.1.2-bin-hadoop3.2/sbin:/home/user/apache-maven-3.8.1/bin:/home/user/kafka/bin)
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/home/user/apache-tez/lib/slf4j-log4j12-1.7.10.jar.bkp!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/home/user/apache-tez/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/home/user/apache-hive/lib/log4j-slf4j-impl-2.10.0.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/home/user/apache-hive/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/home/user/hadoop-3.2.2/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
Hive Session ID = 4da8b861-e768-4159-8676-3aa0a241d191
Logging initialized using configuration in jar:file:/home/user/apache-hive/lib/hive-common-3.1.2.jar!/hive-log4j2.properties Async: true
Hive Session ID = 9945ba2b-bb79-41d5-8f81-204a8344c40f
hive> show databases;
OK
default
Time taken: 1.501 seconds, Fetched: 1 row(s)
hive> create table student( id int, name string)
> ;
OK
Time taken: 0.916 seconds
hive> select * from student;
OK
Time taken: 1.877 seconds
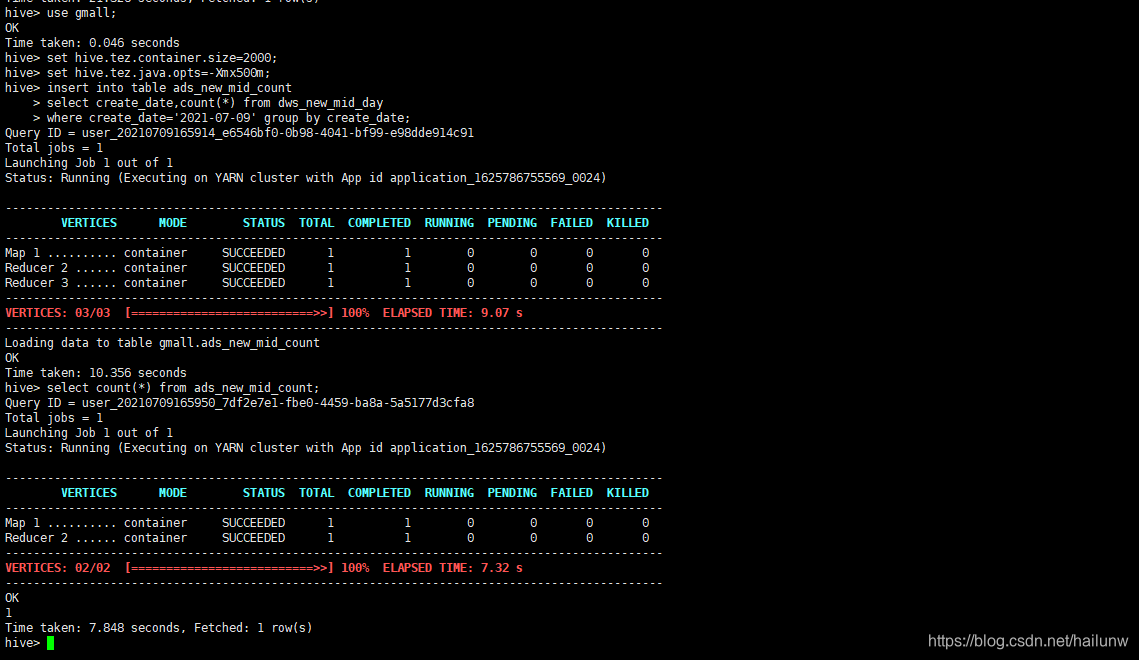
hive> set hive.tez.container.size=1024;
hive> set hive.tez.java.opts=-Xmx500m;
hive> insert into table student(id,name) values(1,'test');
Query ID = user_20210708122909_fd4262de-bf1f-496d-9470-3ae789364d34
Total jobs = 1
Launching Job 1 out of 1
Status: Running (Executing on YARN cluster with App id application_1625717375401_0007)
----------------------------------------------------------------------------------------------
VERTICES MODE STATUS TOTAL COMPLETED RUNNING PENDING FAILED KILLED
----------------------------------------------------------------------------------------------
Map 1 .......... container SUCCEEDED 1 1 0 0 0 0
Reducer 2 ...... container SUCCEEDED 1 1 0 0 0 0
----------------------------------------------------------------------------------------------
VERTICES: 02/02 [==========================>>] 100% ELAPSED TIME: 9.94 s
----------------------------------------------------------------------------------------------
Loading data to table default.student
OK
Time taken: 13.999 seconds
hive> select * from student;
OK
1 test
Time taken: 0.239 seconds, Fetched: 1 row(s)
hive>