概念
HDFS (Hadoop Distributed File System),Hadoop分布式文件系统,用来存超大文件的。
HDFS 遵循主/从架构,由单个 NameNode(NN) 和多个 DataNode(DN) 组成:
- NameNode : 负责执行有关
文件系统命名空间的操作,例如打开,关闭、重命名文件和目录等。它同时还负责集群元数据的存储,记录着文件中各个数据块的位置信息。管理员,负责协调。 - DataNode:负责提供来自文件系统客户端的读写请求,执行块的创建,删除等操作。打工人,负责存数据。
使用流程
写文件
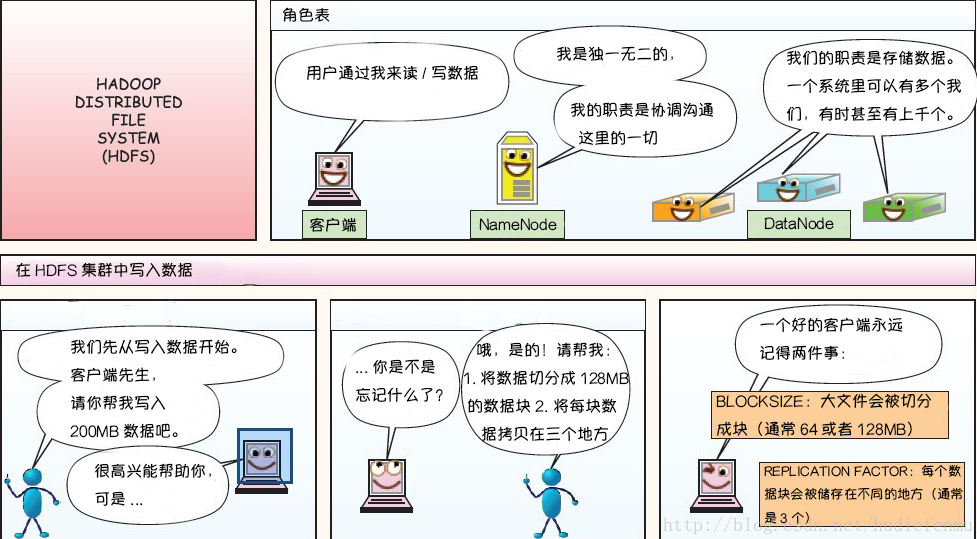
有一个文件需要存储到分布式集群上。
客户端提供两个参数:
- blocksize:块大小(默认128M)
- replication factor: 复制因子 (默认3个)
默认情况下,hdfs把文件拆分成一堆128M的块,每个块复制出3个副本,扔到不同的DataNode上存储。
如下图:
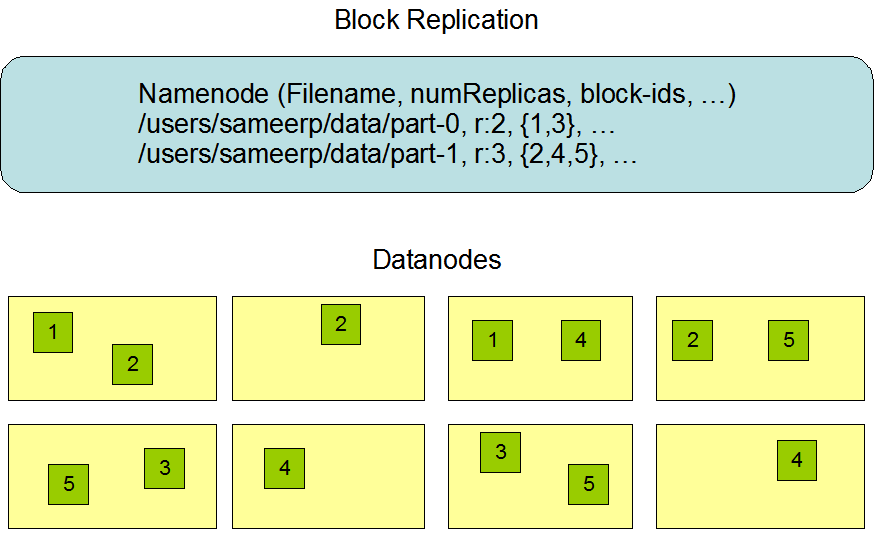
数据被分成了2块:part-0,part-1
part0复制因子为2,所以{1, 3}分别被扔到了2个DataNode上;
part1复制因子为3,所以{2, 4,5}分别被扔到了3个DataNode上;
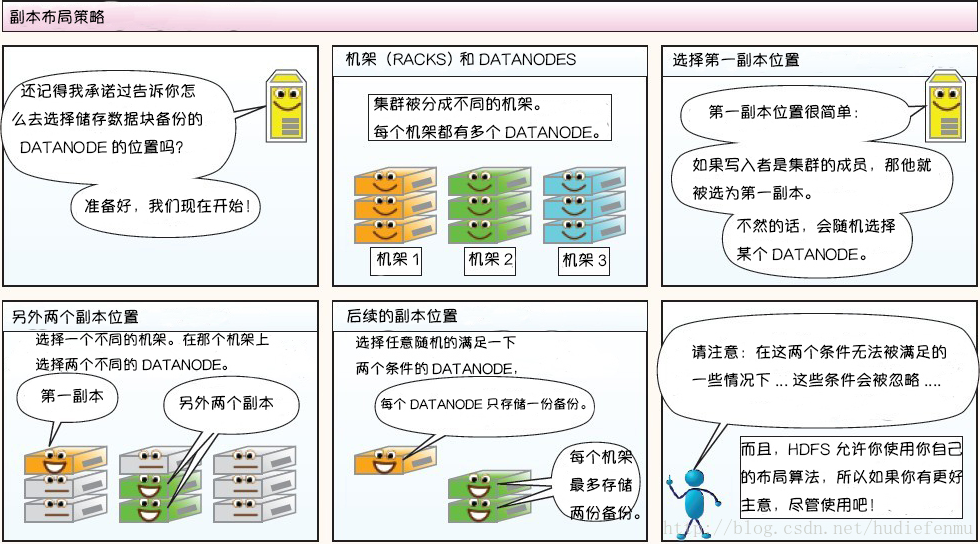
DataNode选择策略
复制因子为3时:
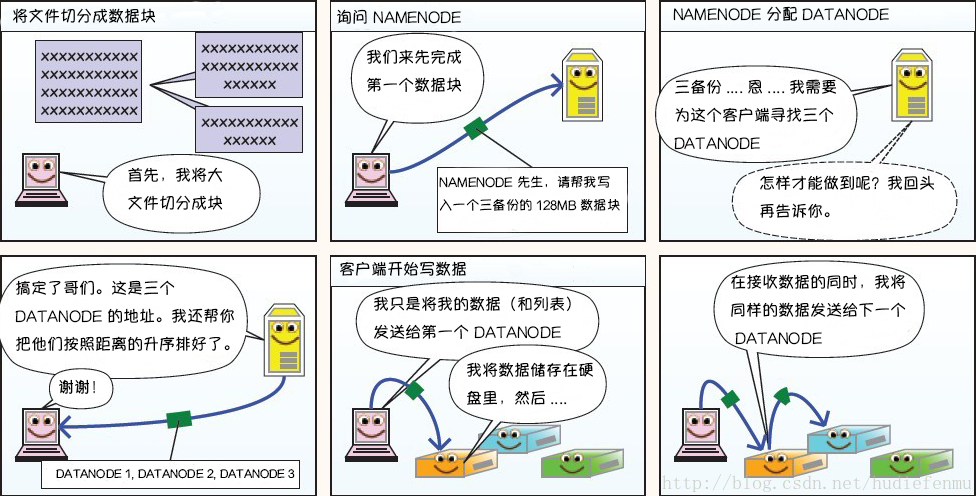
第1份:若写入程序本身在一个DataNode上,就放在该DataNode上;若不在,就随机选一个DataNode,把数据写进去;
第2份:在另一个机架上随机找个DataNode,从上一个DataNode负责把数据复制过来;
第3份:在第2份同一机架上,再找一个DataNode,从上一个DataNode负责把数据复制过来;
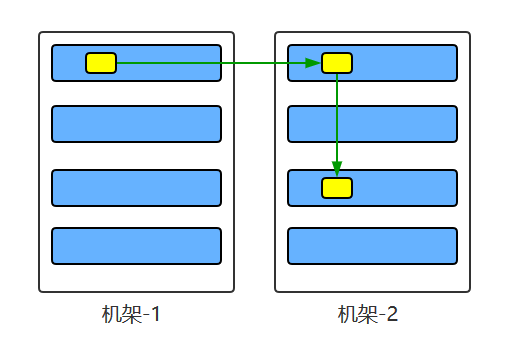
复制因子大于3时,第4份以后的数据就随便找DataNode放了,但要满足:
- 每个机架上的副本数低于上限,通常为 (复制系数 - 1 ) / 机架数量 + 2。复制系数=3,机架数=2时,上限为 2/2 + 2 = 3。为了铺的平均一点,一个机架炸了也没事。
- 一个DataNode上只能有同一个块的一个副本。要的是雨露均沾。
写文件成功后,NameNode会返回按距离升序排好的DataNode地址。
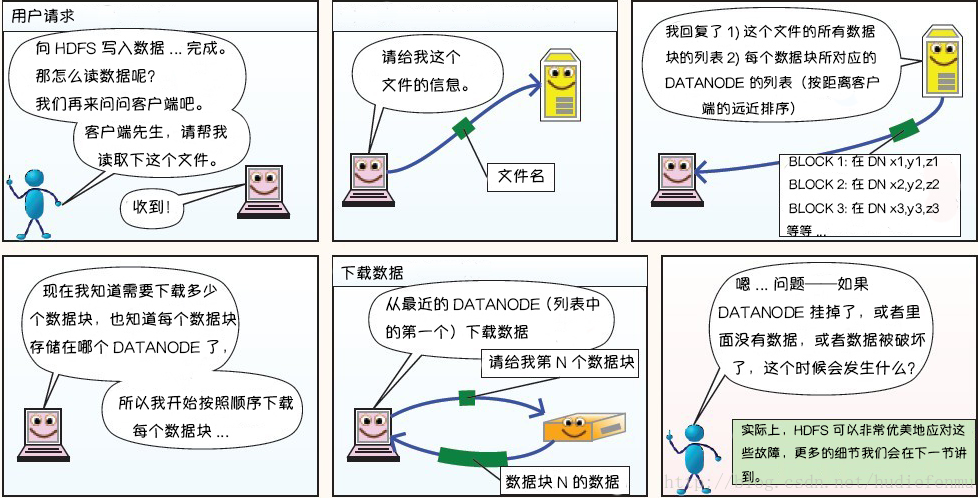
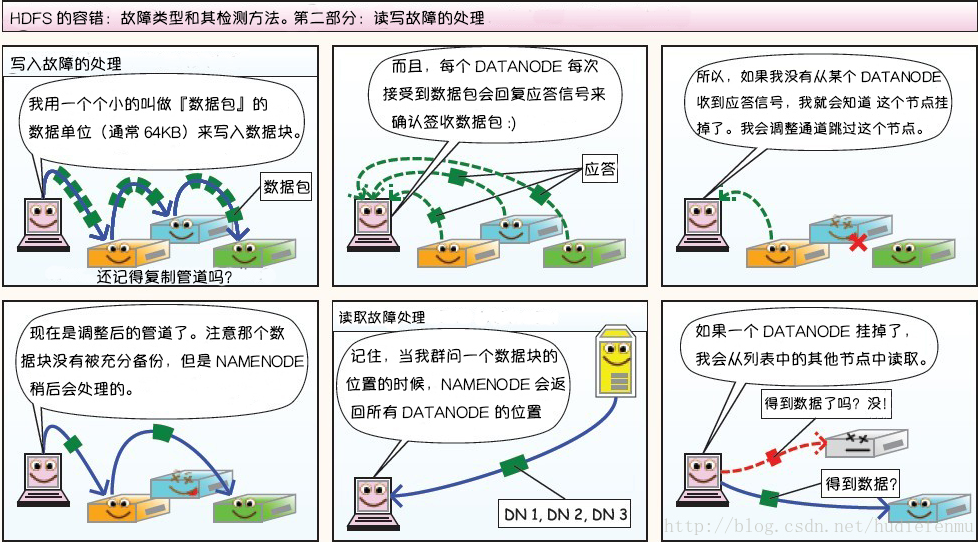
读文件
总的原则:优先读取距离读取器最近的副本。先在同一个机架上找,再去隔壁机架找,再去隔壁数据中心找…
怎么知道文件包含哪些副本?问NameNode。
怎么知道副本都存在哪些DataNode,距离又多远呢?问NameNode。
(更具体的读写流程还是看最后的漫画比较好。一图胜千言)
稳定性原理
1. 心跳机制和重新复制
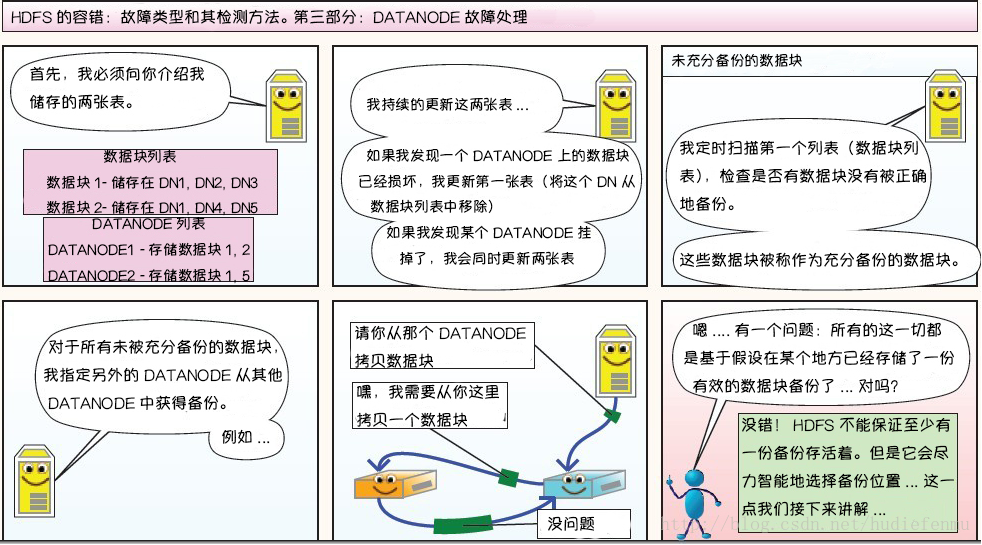
每个 DataNode 定期向 NameNode 发送心跳消息,如果超过指定时间没有收到心跳消息,则将 DataNode 标记为死亡,以后有各种请求都会忽略该DataNode。
由于数据不再可用,可能会导致某些块的复制因子小于其指定值,NameNode 会跟踪这些块,并在必要的时候进行重新复制。
2. 数据的完整性
当客户端创建 HDFS 文件时,它会计算文件的每个块的 校验和,存在同一 HDFS 命名空间下的单独的隐藏文件中。
当客户端检索文件内容时,它会验证从每个 DataNode 接收的数据是否与存储在关联校验和文件中的 校验和 匹配。如果匹配失败,则证明数据已经损坏,就换个DataNode拿数据。
3.元数据的磁盘故障
FsImage 和 EditLog 是 HDFS 的核心数据,这些数据的意外丢失可能会导致整个 HDFS 服务不可用。
为了避免这个问题,可以配置 NameNode 使其支持 FsImage 和 EditLog 多副本同步,任何改变都会引起每个副本 FsImage 和 EditLog 的同步更新。
4.支持快照
快照支持在特定时刻存储数据副本,在数据意外损坏时,可以通过回滚操作恢复到健康的数据状态。
适用场景
适合大文件的存储,文档的大小应该是是 GB 到 TB 级别的。
支持高吞吐量的数据访问,而非低延迟的数据访问。量大,但不快。
支持将内容追加到文件末尾,但不支持数据的随机访问,不能从文件任意位置新增数据。
附:图解HDFS存储原理
1. HDFS写数据原理
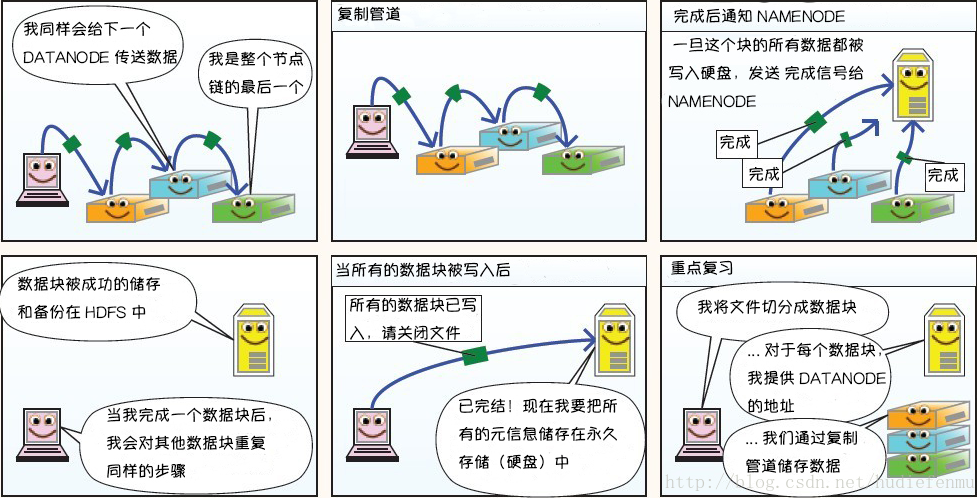
2. HDFS读数据原理
3. HDFS故障类型和其检测方法
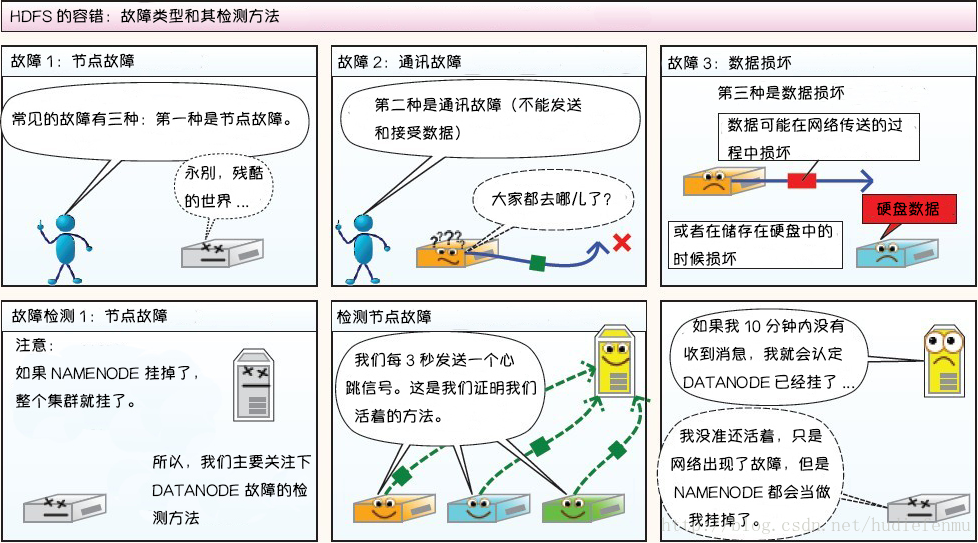
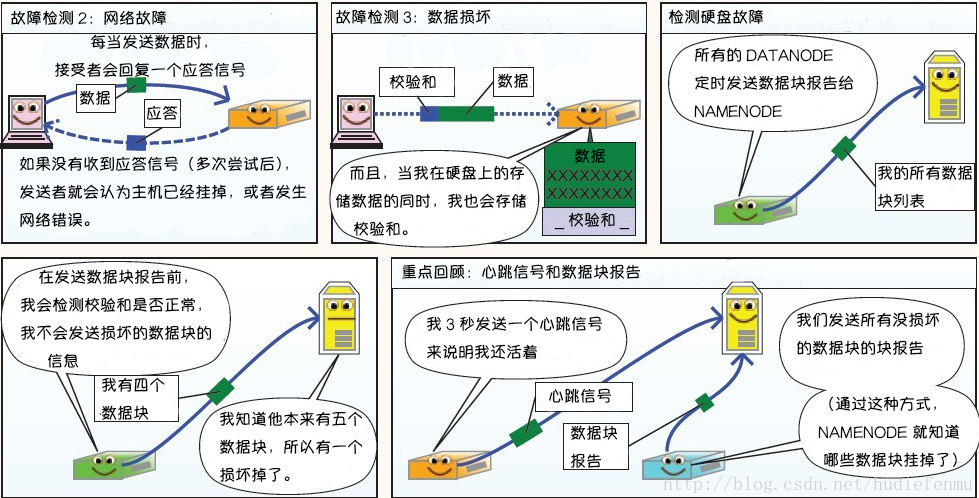
第二部分:读写故障的处理
第三部分:DataNode 故障处理
副本布局策略:
参考资料
https://github.com/heibaiying/BigData-Notes/blob/master/notes/Hadoop-HDFS.md
翻译经典 HDFS 原理讲解漫画

![leecode[242]有效的字母异位词 Python3实现(collections.Counter,哈希计数)](/images/no-images.jpg)

