在前两篇文章中,我们已经介绍了HDFS的理论基础以及命令行的基本操作。
但是,在实际中我们使用HDFS的平台时,是不可能全部进行命令行操作的。一定是要与编程结合起来进行的。所以,本篇将介绍HDFS相关的一些编程操作。
上篇链接:
Hadoop学习篇(二)——HDFS
Hadoop学习篇(二)——HDFS实践操作
Hadoop学习篇(二)——HDFS编程操作1
说明:如涉及到侵权,请及时联系我,并在第一时间删除文章。
2.3 HDFS编程操作
HDFS有很多常用的Java API,这里我们用Java API模拟Shell操作。
2.3.1 环境配置
2.3.1.1 maven配置
首先进行编译环境配置。这里创建maven项目,通过远程仓库下载对应jar包。
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop_version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop_version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>${hadoop_version}</version>
</dependency>
(注意:这里的${hadoop_version}需要更换成你下载的Hadoop的版本)
2.3.1.2 手动导入
这里我们也可以通过手动倒入jar包进行。
需要导入的jar包位置有:
hadoop_path/share/hadoop/common/lib/*.jar
hadoop_path/share/hadoop/client/lib/*.jar
hadoop_path/share/hadoop/hdfs/lib/*.jar
2.3.1.3 常用API
- org.apache.hadoop.fs.FileSystem 通用文件系统的抽象基类,可悲分布式文件系统继承。
- org.apache.hadoop.fs.FileStatus 一个接口,用于客户端展示系统中文件和目录的元数据,可通过FileSystem.ListStatus()方法获得具体的实例对象。
- org.apache.hadoop.fs.FSDataInputStream 文件输入流,用于读取Hadoop文件。
- org.apache.hadoop.fs.FSDataOutputStream 文件输出流,用于写Hadoop文件。
- org.apache.hadoop.fs.Path 用于表示Hadoop文件系统中的一个文件或目录的路径。
- org.apache.hadoop.fs.PathFilter 一个接口,实现PathFilter.accept(Path path)来判断是否接收路径path对应的文件或目录
- org.apache.hadoop.conf.Configuration 访问配置项。以core-site.xml文件为准。
2.3.2 编程操作
HDFS的编程操作,实际上就是用高级语言模拟HDFS的命令行操作,从而做到机器代替人工的大量处理。
我们的编程操作主要进行模拟的有:
- 判断文件是否存在
- 实现ls命令
- 实现cat命令
- 写入HDFS
- HDFS文件的下载与上传
2.3.2.1 判断文件是否存在
java">import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.IOException;
public class HadoopOp {
private static Configuration conf;
private static FileSystem fs;
public static void main(String[] args) {
isExist(conf, fs, "/user");
}
public static void isExist(Configuration conf, FileSystem fs, String filePath) {
try {
conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://localhost:9000");
conf.set("fs.hdfs.impl", "org.apache.hadoop.hdfs.DistributedFileSystem");
fs = FileSystem.get(conf);
if (fs.exists(new Path(filePath)) {
System.out.println("File Exists");
} else{
System.out.println("File None");
}
} catch (IOException e) {
e.printStackTrace();
} finally {
if (fs != null) {
try {
fs.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
运行结果有:

2.3.2.2 实现ls命令
这里递归输出文件全部信息,包括权限、创建时间、所属等。
借用FileStatus创建数组,存放路进行新。采用递归思想,遍历每一个目录。
java">import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.IOException;
public class HadoopOp {
private static Configuration conf;
private static FileSystem fs;
public static void main(String[] args) {
conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://localhost:9000");
conf.set("fs.hdfs.impl", "org.apache.hadoop.hdfs.DistributedFileSystem");
fs = FileSystem.get(conf);
listStatus(conf, fs, "/user");
}
public static void listStatus(Configuration conf, FileSystem fs, String filePath) {
try {
FileStatus[] fileStatuses = fs.listStatus(new Path(filePath));
for (FileStatus fileStatus:fileStatuses) {
if (fileStatus.isDirectory()) {
String dir = fileStatus.getPath().toString();
System.out.println("---------------------------");
System.out.println("The directory path:\t" + dir);
listStatus(conf, fs, dir);
} else {
System.out.println("The file path:\t" + fileStatus.getPath().toString());
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
运行结果有:

2.3.2.3 实现cat命令
这里将HDFS文件内容转换为FSDataInputStream数据输入流,传至Java的InputStreamReader数据输入流中,并转换为BufferedReader进行读取。
java">import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
public class HadoopOp {
private static Configuration conf;
private static FileSystem fs;
public static void main(String[] args) {
conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://localhost:9000");
conf.set("fs.hdfs.impl", "org.apache.hadoop.hdfs.DistributedFileSystem");
fs = FileSystem.get(conf);
ReadFile(conf, fs, "/user/hadoop/Exp/test/f1.txt");
}
public static void ReadFile(Configuration conf, FileSystem fs, String filePath) {
try {
FSDataInputStream fsDataInputStream = fs.open(new Path(filePath));
BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(fsDataInputStream));
String content = null;
while ((content = bufferedReader.readLine()) != null) {
System.out.println(content);
}
bufferedReader.close();
fs.close();
} catch (IOExpection e) {
e.printStackTrace();
}
}
}
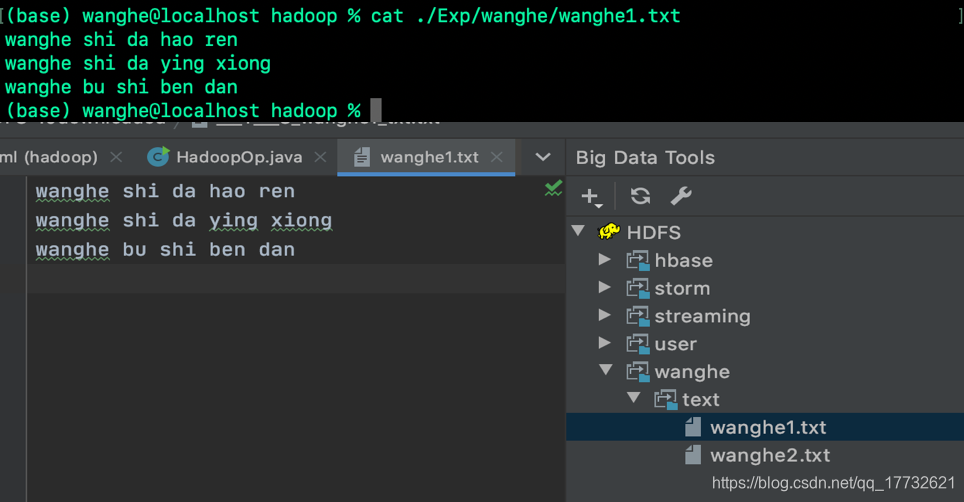
文件内容为:

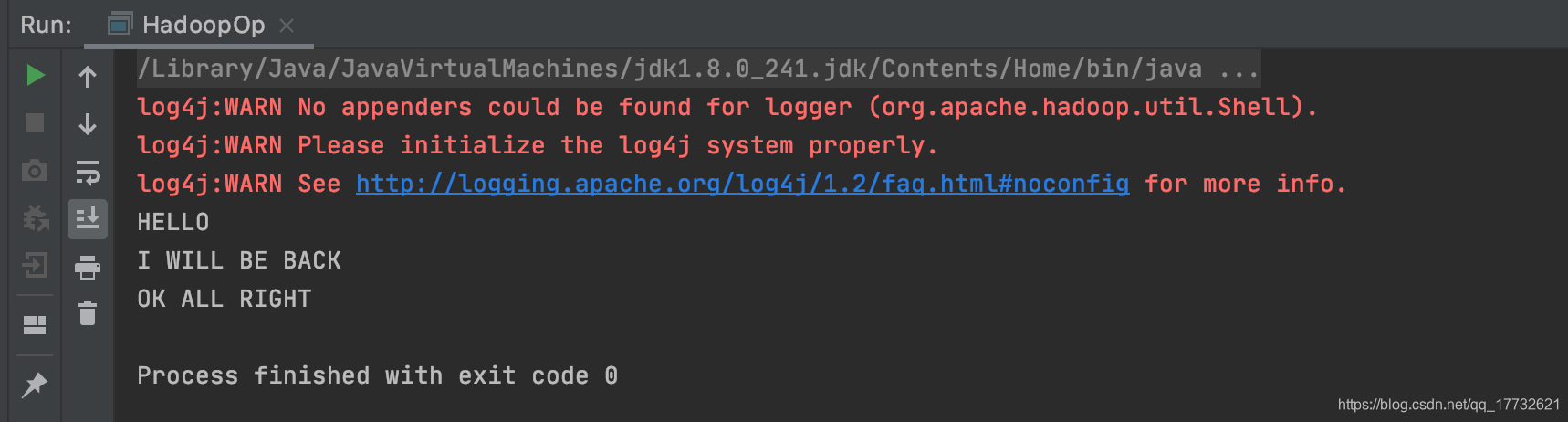
程序运行结果: