本文是尚硅谷Hadoop教程的学习笔记,由于个人的需要,只致力于搞清楚Hadoop是什么,它可以解决什么问题,以及它的原理是什么。至于具体怎么安装、使用和编写代码不在我考虑的范围内。
一、Hadoop入门
大数据的特点:
- Volume(大量)
- Velocity(高速)
- Variety(多样)
- Value(低价值密度)
1. Hadoop概念
是一个分布式系统基础架构
2. Hadoop优势
- 高可靠
- 高扩展性
- 高效性
- 高容错性
3. Hadoop组成
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5SetVMFj-1651112212696)(/Users/zuzhiang/Library/Application Support/typora-user-images/image-20220408103502973.png)]](https://img-blog.csdnimg.cn/b221c385072c4821a272e1fd2c357bc2.png)
(1) HDFS架构概述
HDFS(Hadoop Distributed File System)是一个分布式文件系统

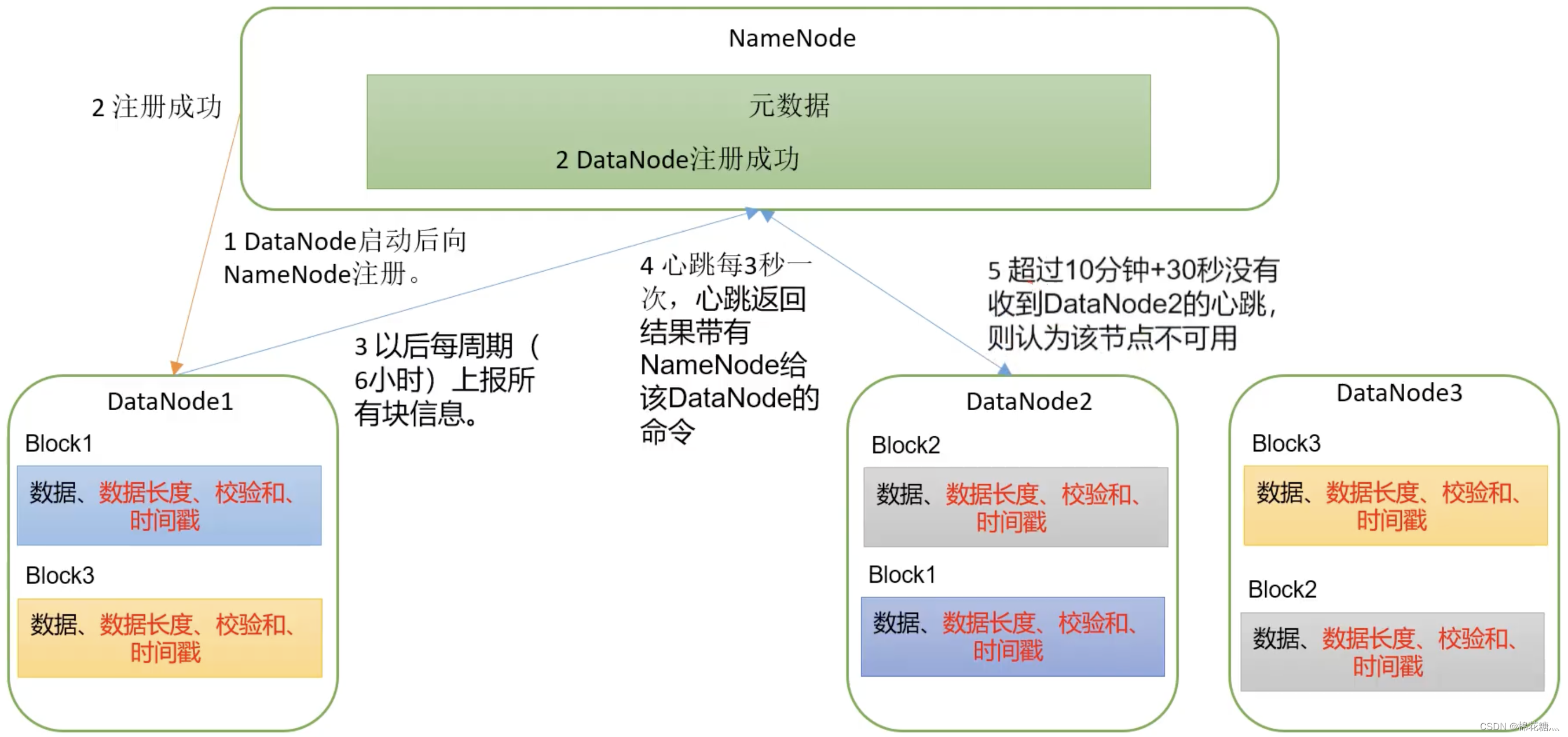
- NameNode(NN):存储文件的元数据,如文件名、文件目录结构、文件属性,以及每个文件的块列表和块所在的DataNode等。
- DataNode(DN):在本地文件系统存储文件块数据,以及块数据的校验和。
- Secondary NameNode(2NN):每隔一段时间对NameNode元数据备份。
(2) YARN架构概述
YARN(Yet Another Resource Negotiater):另一种资源协调者,是Hadoop的资源管理器。
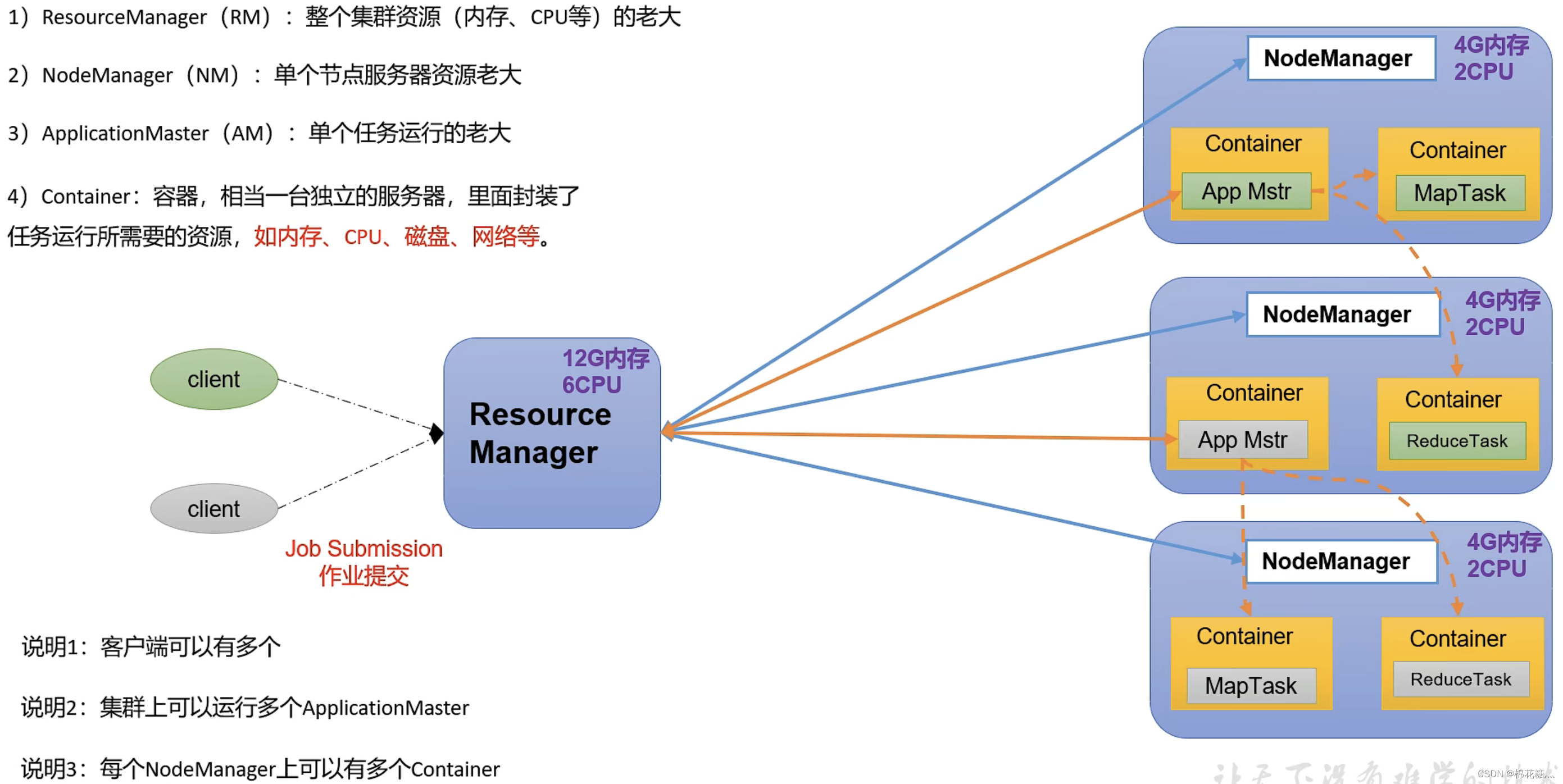
- ResourceManager(RM):整个集群资源(内存、CPU等)的管理者
- NodeManager(NM):单个节点服务器资源管理者
- ApplicationMaster(AM):单个任务运行的管理者
- Container:容器,相当于一台独立的服务器,里面封装了任务运行所需要的资源,如内存、CPU、磁盘、网络等
说明:
- 客户端可以有多个
- 集群上可以运行多个ApplicationMaster
- 每个NodeManager上可以有多个Container
MapReduce_56">(3) MapReduce架构概述
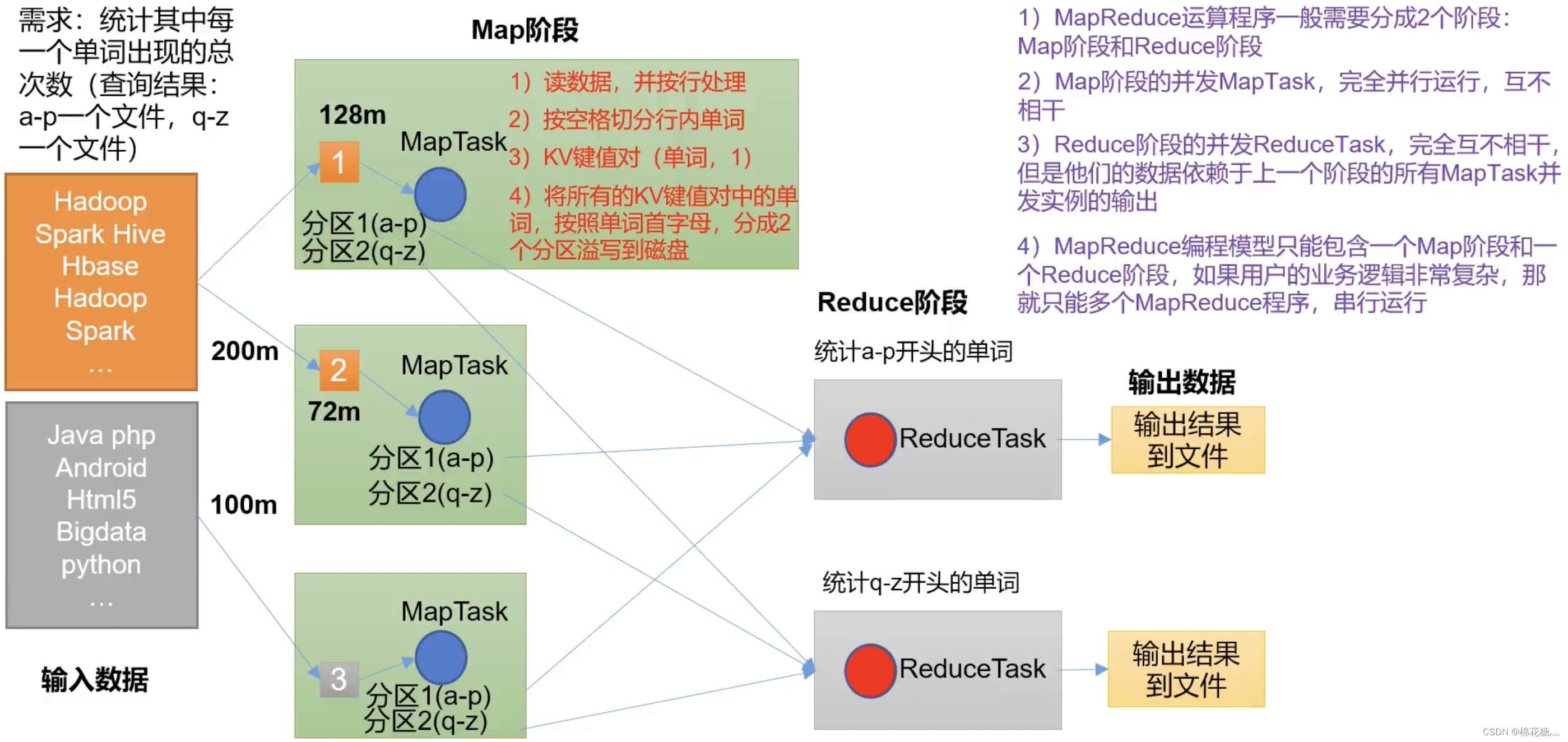
MapReduce将计算拆成两个阶段:Map和Reduce
- Map阶段并行处理输入数据
- Reduce阶段对Map结果进行汇总

MapReduce_66">(4) HDFS、YARN、MapReduce三者关系

4. 大数据技术生态体系

二、HDFS
1. 概述
(1) 优缺点
优点:
- 高容错性:一个数据会自动保存多个副本,某个副本丢失后,它可以自动恢复
- 适合处理大数据:无论是数据规模还是文件数量规模大都可以处理
- 可构建在廉价的机器上
缺点:
- 不适合低延迟的数据访问:如毫秒级的存储数据是做不到的
- 无法高效地对大量小文件进行存储:
- 存储大量小文件时,会占用NameNode大量内存去存储文件目录信息和块信息,而NameNode的内存是有限的
- 小文件存储的寻址时间会超过读取时间,它违反了HDFS的设计目标
- 不支持并发写入和文件的随机修改
- 不允许多个线程同时写同一文件
- 仅支持数据追加,不支持随机修改
(2) 组成
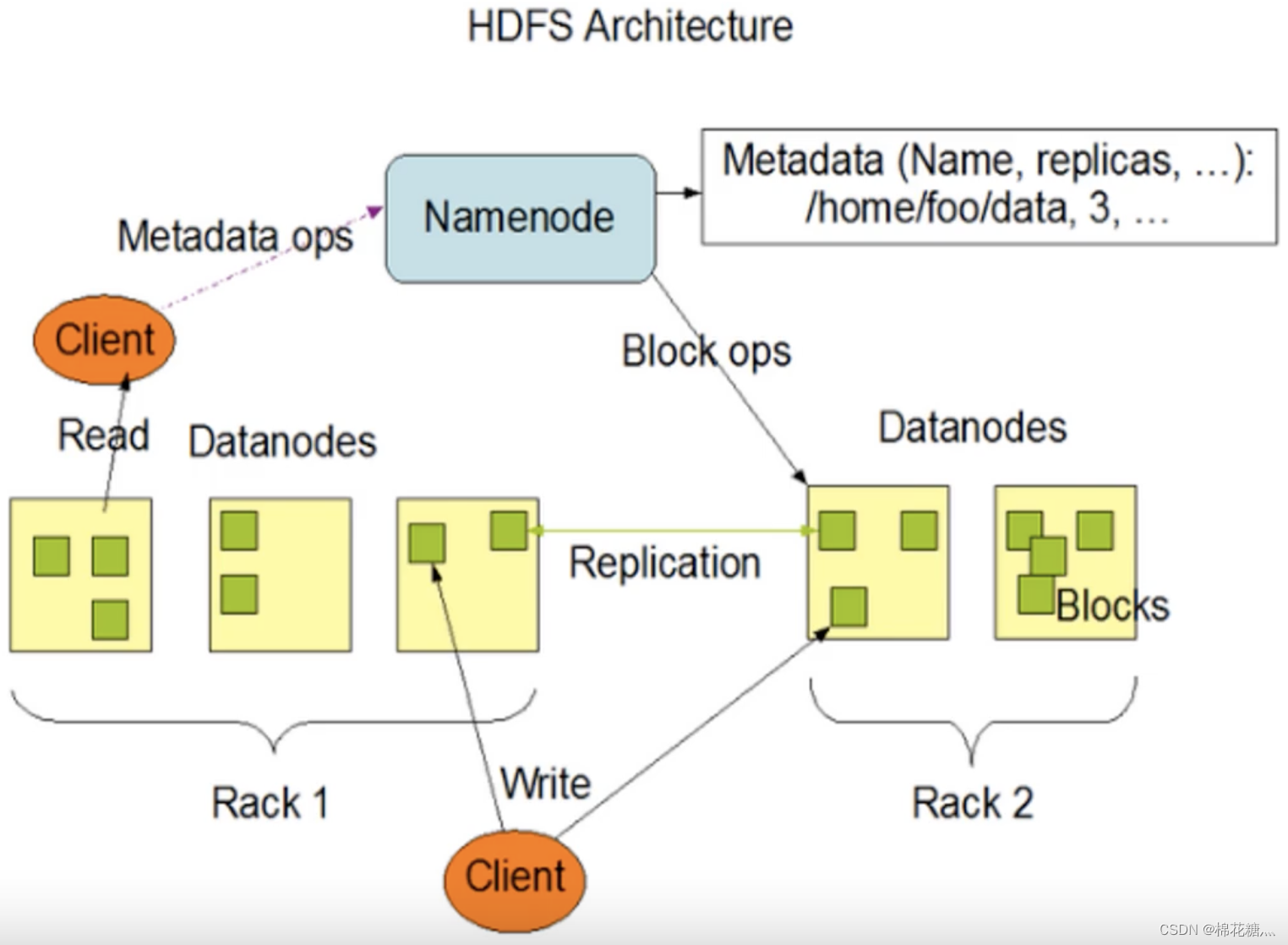
NameNode(NN):就是Master,它是一个主管、管理者,其功能是:
- 管理HDFS的名称空间
- 配置副本策略
- 管理数据块的映射信息
- 处理客户端读写请求
DataNode(DN):就是Slave,NameNode下达命令,DataNode执行具体操作,其功能是:
- 存储实际数据块
- 执行数据块的读写操作
Secondary NameNode(2NN):并非NameNode的热备,当NameNode挂掉时,它并不能马上替换NameNode并提供服务,其功能是:
- 辅助NameNode,分担其工作量,比如定期合并Fsimage和Edits,并推送给NameNode
- 在紧急情况下,可辅助恢复NameNode
Client:就是客户端,其功能是:
- 文件切分,当文件上传HDFS时,将文件切分为一个个块,并进行上传
- 与NameNode交互,获取文件的位置信息
- 与DataNode交互,读取或写入数据
- 提供一些命令来管理HDFS,如NameNode格式化
- 通过命令来访问HDFS,如对NameNode的增删改查操作
(3) 文件块大小
在Hadoop1.x中文件块大小默认为64M,而在2.x和3.x中为128M。当寻址时间为传输时间的1%时为最佳状态。文件块的大小太小,则会导致大文件被分割成太多块,增加寻址时间。而文件块大小太大,则会使得传输时间远大于寻址时间。文件块的大小主要取决于磁盘的传输速率。
2. HDFS的读写流程
(1) 剖析文件的写入

(2) 网络拓扑-节点距离计算
节点距离:两个节点到达最近公共祖先的距离之和
(3) 机架感知-副本存储节点总结
第一个副本存储在客户端所在的节点上,如果客户端在集群外,则随机选一个。
第二个副本在另一个机架的随机节点上。
第三个副本在第二个副本所在机架的随机节点上。
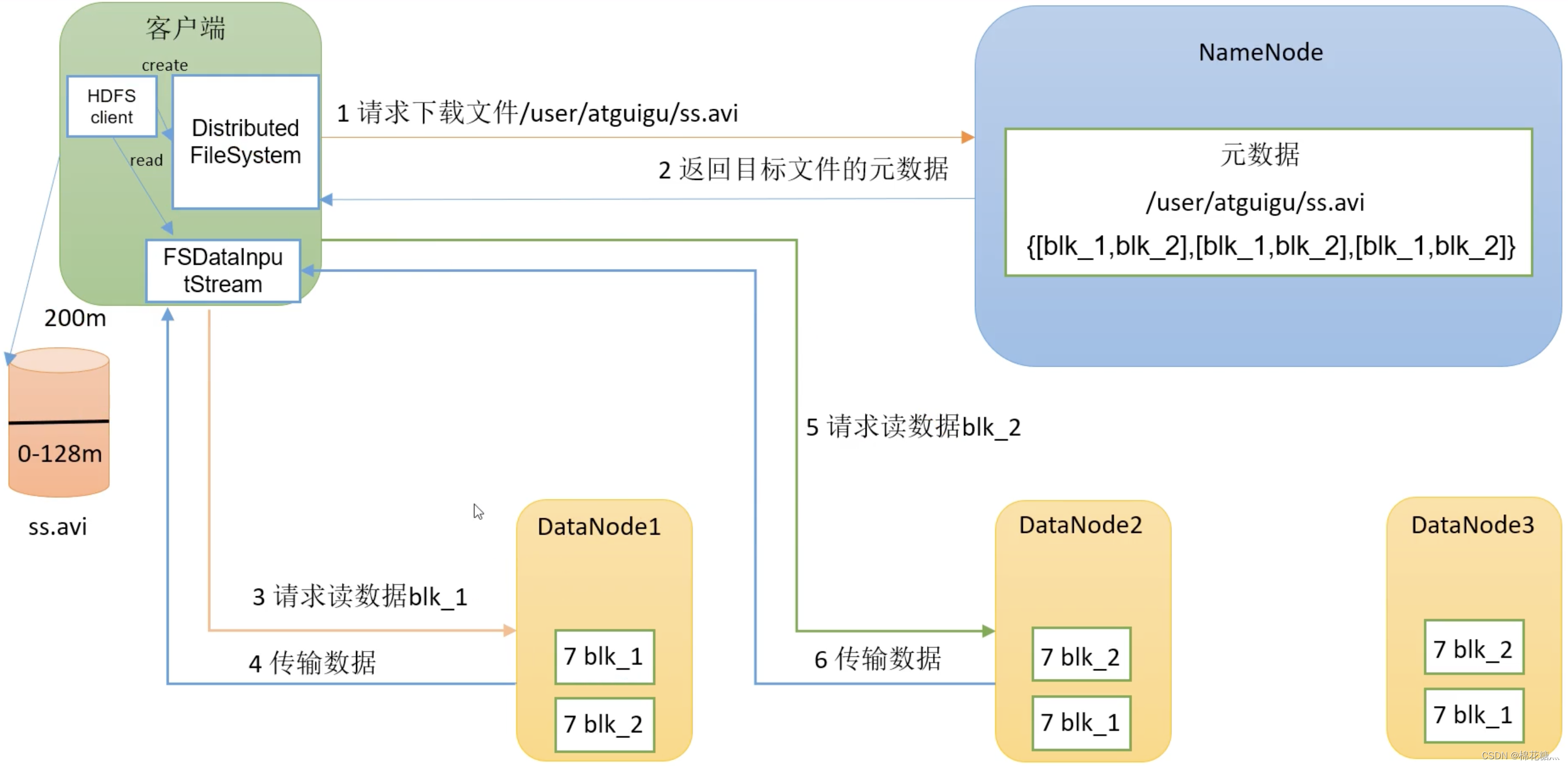
(4) 剖析文件的读取
3. NN和2NN
4. fsimage和edits概念
fsimage文件:HDFS文件系统元数据的一个永久性检查点,其中包含HDFS文件系统所有的目录和文件innode的序列号信息
edits文件:存放HDFS文件系统所有更新操作的路径,文件系统客户端所执行的所有写操作首先会被记录在edits文件中
seen_txid文件:保存的是一个数字,就是最后一个edits_的数字
5. DataNode工作机制
MapReduce_171">三、MapReduce
MapReduce_173">1. MapReduce概述
(1) 定义
MapReduce是一个分布式运算程序的编程框架
MapReduce核心思想:
(2) 优缺点
优点:
- 易于编程。用户只需要关心业务逻辑
- 良好的扩展性。可以动态增加服务器,解决计算资源不够的问题
- 高容错性。任何一台集群挂掉,可以将任务转移到其他节点
- 适合海量数据计算(TB/PB)。几千台服务器共同计算
缺点:
- 不擅长实时计算。MySQL擅长
- 不擅长流式计算。Flink擅长
- 不擅长DAG有向无关图计算。Spark擅长
2. 编程规范
用户编写的程序分为3个部分:Mapper、Reducer和Driver
(1) Mapper阶段
- 用户自定义的Mapper要继承自己的父类
- Mapper的输入是键值对的形式
- Mapper中的业务逻辑写在map()方法中
- Mapper的输出是键值对的形式
- map()方法对每一个<K, V>调用一次
(2) Reducer阶段
- 用户自定义的Reducer要继承自己的父类
- Reducer的输入类型与Mapper的输入类型相对应
- Reducer的业务逻辑写在reduce()方法中
- ReduceTask进程对每一组相同的<K, V>调用一次reduce()方法
(3) Driver阶段
相当于Yarn集群的客户端,用于提交整个程序到Yarn集群,提交的是封装了MapReduce程序相关运行 参数的job对象
3. 核心框架原理
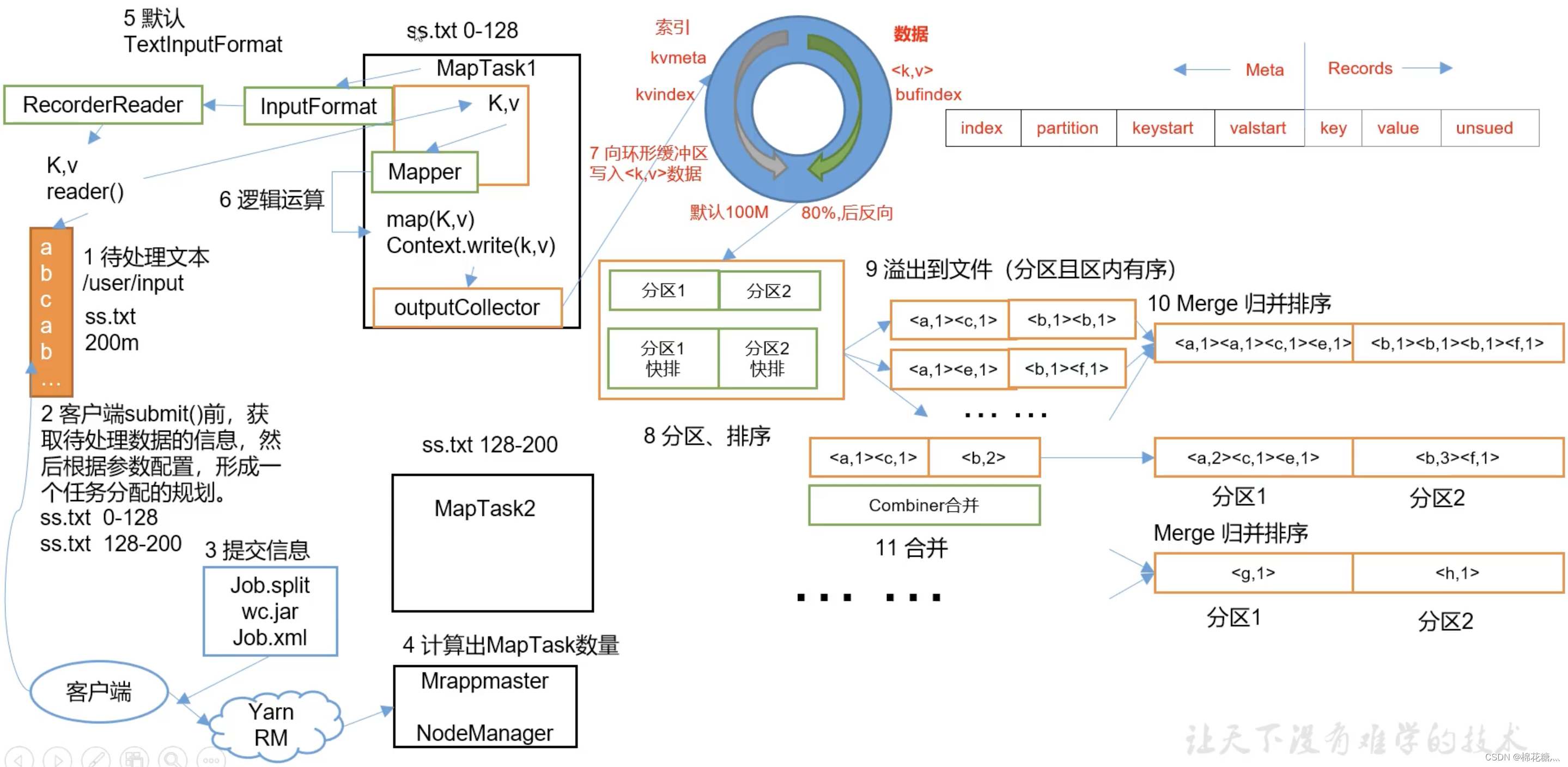
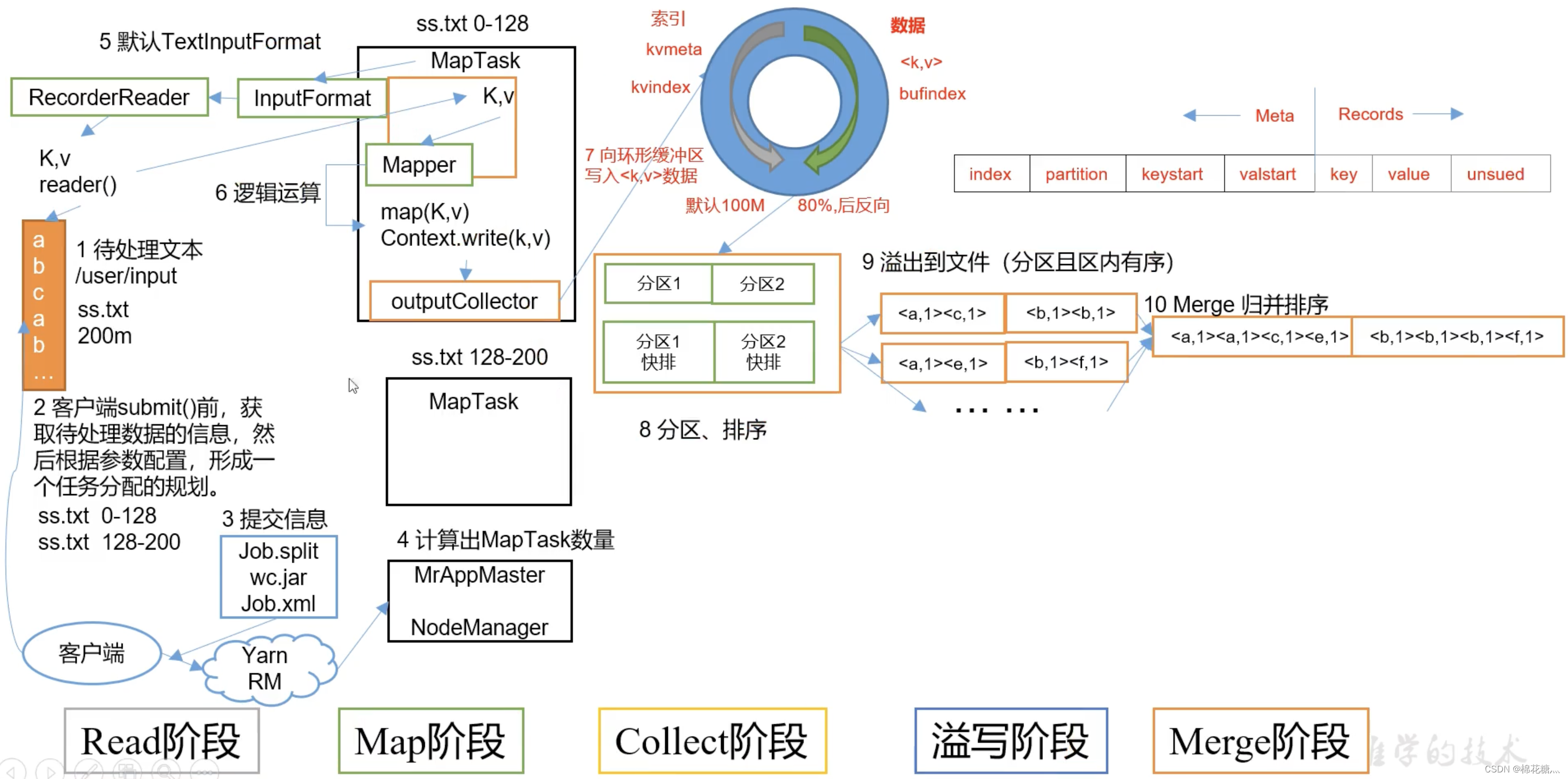
(1) 输入数据处理InputFormat
切片与MapTask并行度决定机制:MapTask的并行度决定Map阶段任务处理并发度,进而影响到整个job的处理速度。
数据块(block)是物理上把数据分成一块一块的,数据块是HDFS数据存储单位。
数据切片只是在逻辑上对输入数据进行分片,数据切片是MapReduce程序计算输入数据的单位。一个切片会对应启动一个MapTask。
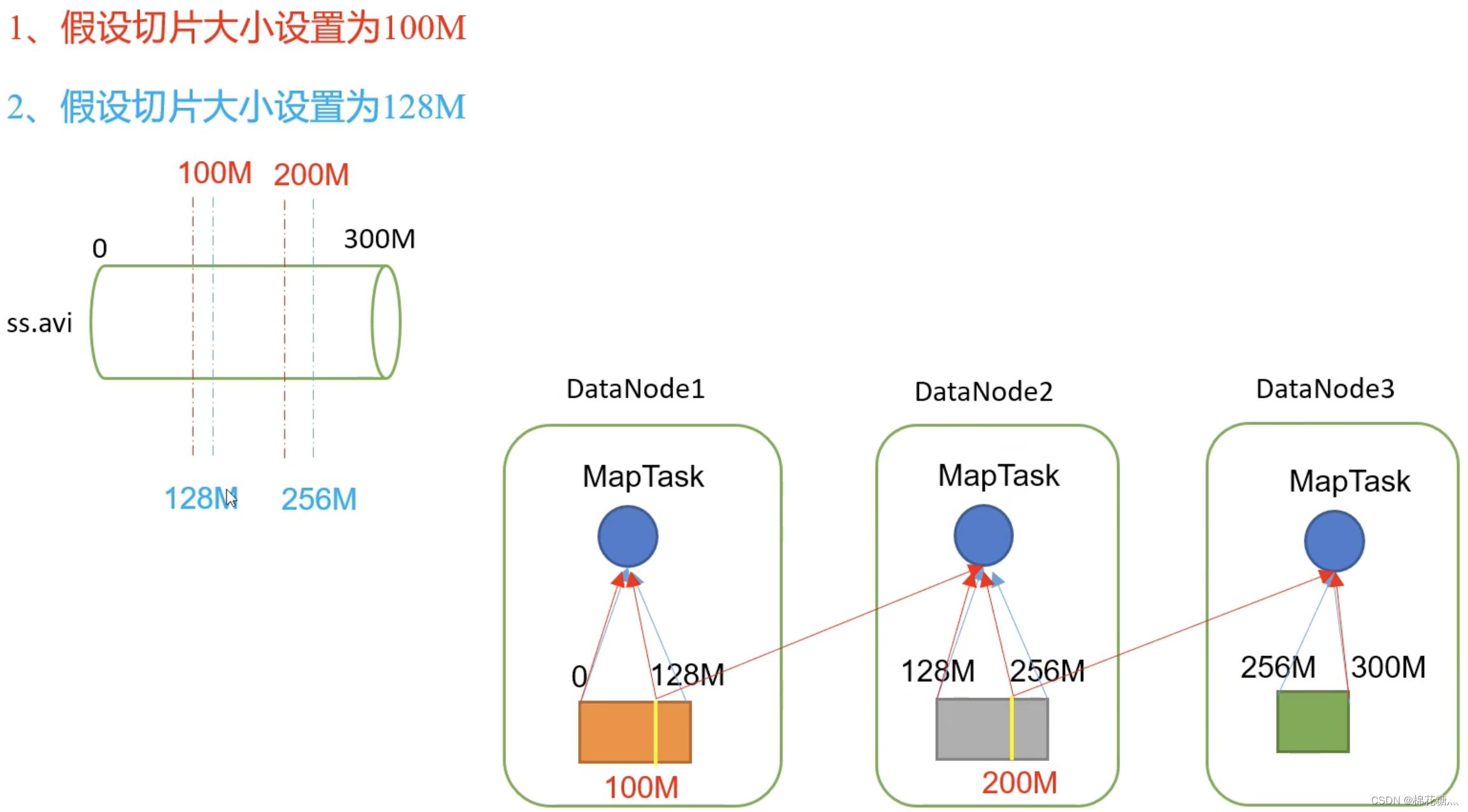
TextInputFormat切片机制
-
一个job的map阶段并行度由提交job时的切片数决定。
-
每一个切片分配一个MapTask并进行处理
-
默认情况下切片大小等于块大小
-
切片时不考虑数据集整体,而是对每个文件单独切片
CombineTextInputFormat切片机制
框架默认的TextInputFormat切片机制是对任务按文件规划切片,不管文件多小,都会是一个单独的切片,都会交给一个MapTask, 这样如果有大量小文件,就会产生大量的MapTask,处理效率极其低下。
应用场景:
Combine TextInputFormat用于小文件过多的场景,它可以将多个小文件从逻辑上规划到一个切片中,这样,多个小文件就可以交给一个MapTask处理。
生成切片过程包括虚拟存储过程和切片过程二部分。首先判断虚拟存储的文件大小是否大于setMaxInputSplitSize值,大于等于则单独形成一个切片。如果不大于则跟下一个虚拟存储文件 进行合并,共同形成一个切片。
MapReduce工作流程:
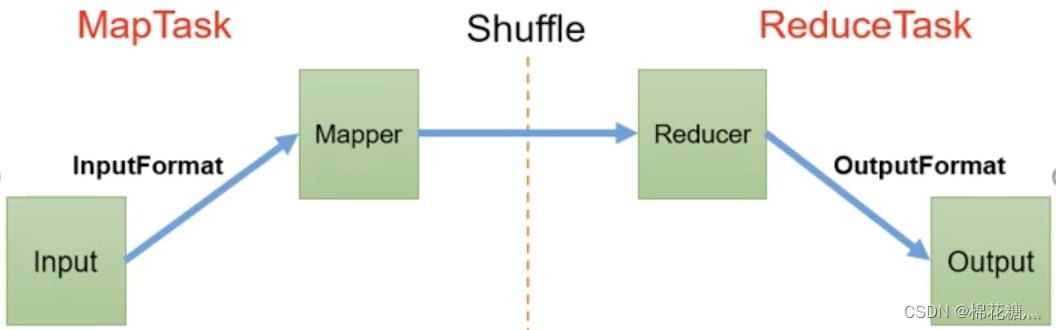
(2) Shuffle
map方法之后,reduce方法之前的数据处理过程称为shuffle(混洗)。
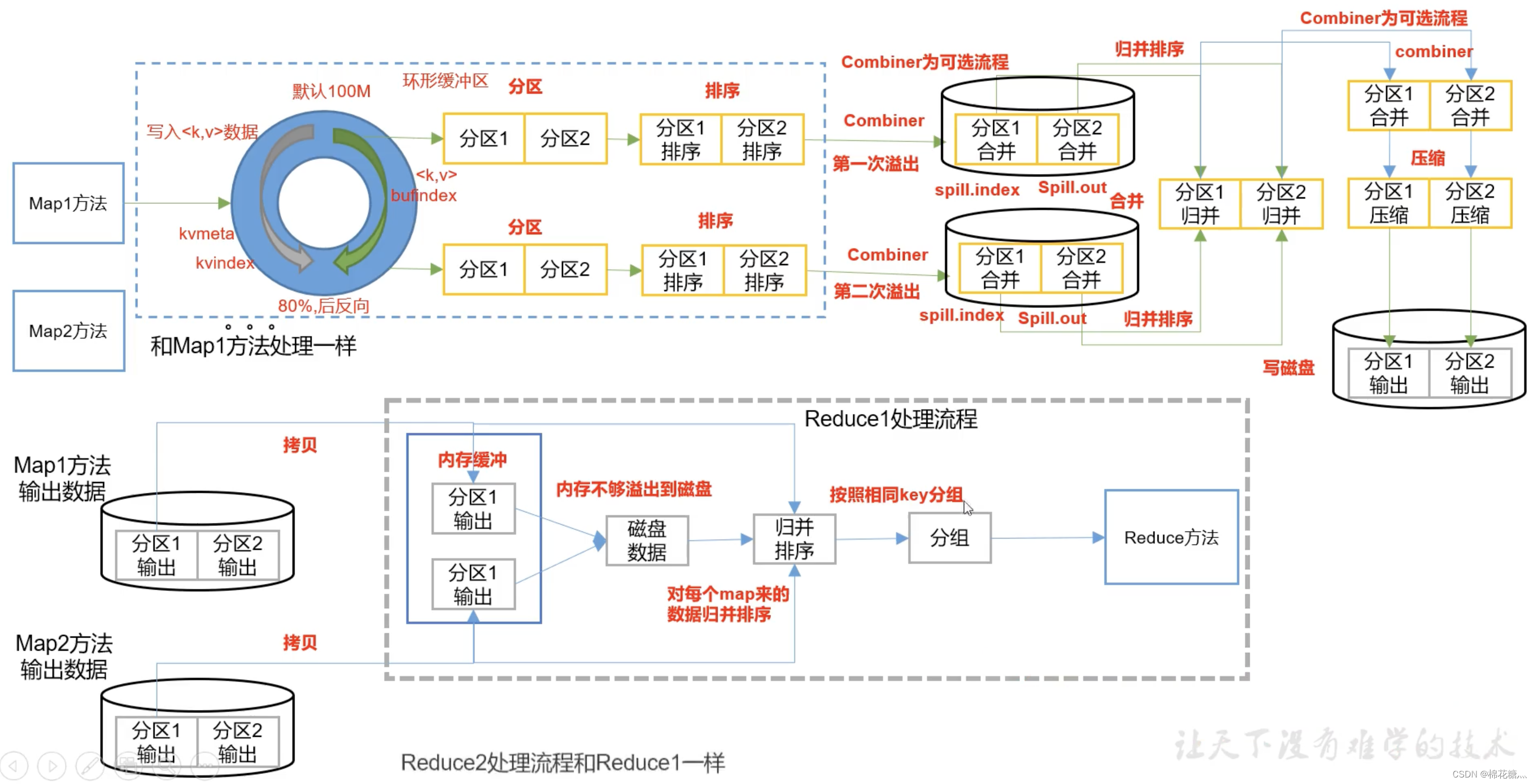
Combiner是MR程序中Mapper和Reducer之外的一种组件
Combiner和Reducer的区别在于运行的位置不同,Combiner在每个MapTask所在的节点运行,Reducer是接收全局所有Mapper的输出结果
Combiner的意义是对每个MapTask的输出进行局部汇总,以减小网络传输量
Combiner能够应用的前提是不能影响最终业务逻辑
(3) 输出数据处理OutputFormat
MapTask工作机制:
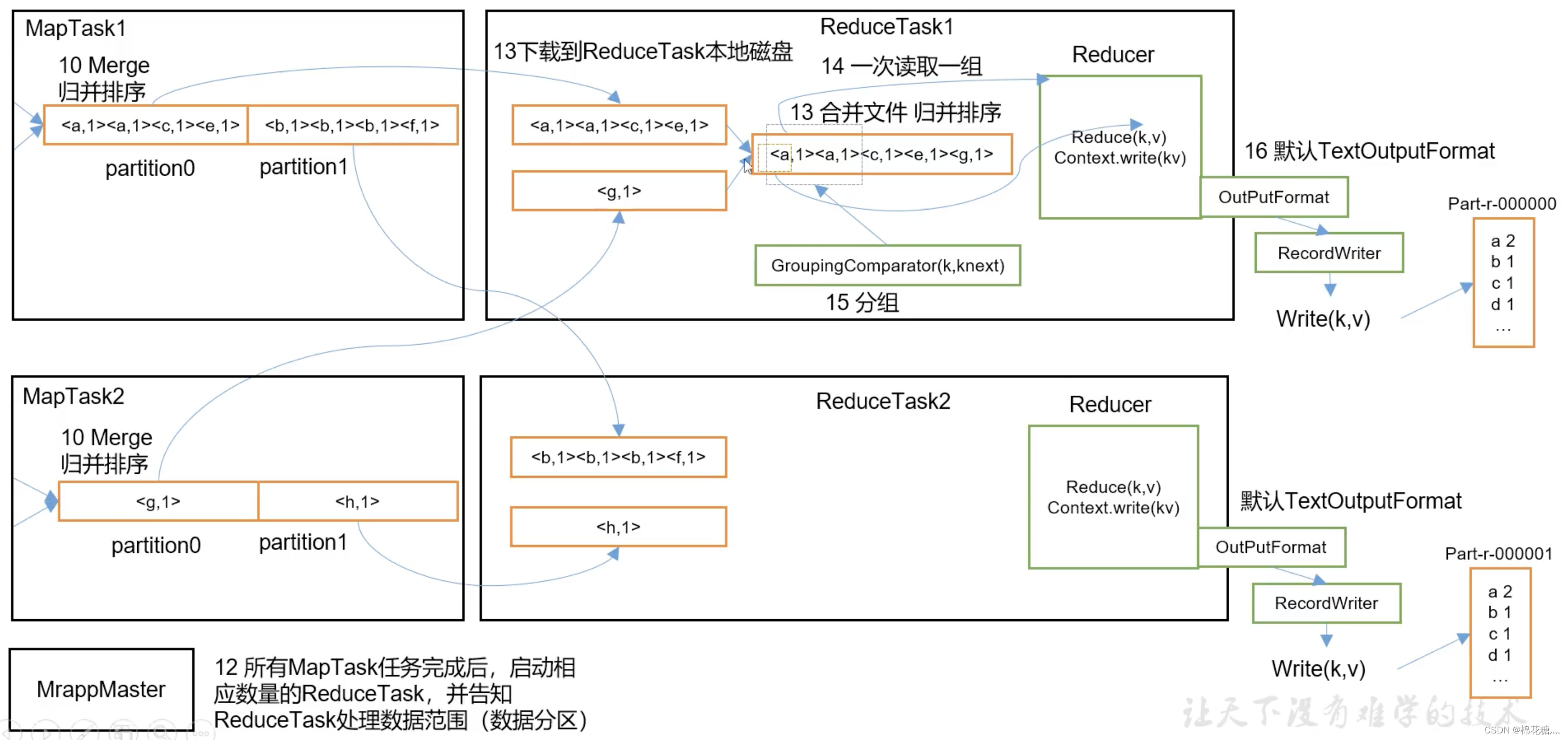
ReducerTask工作机制;
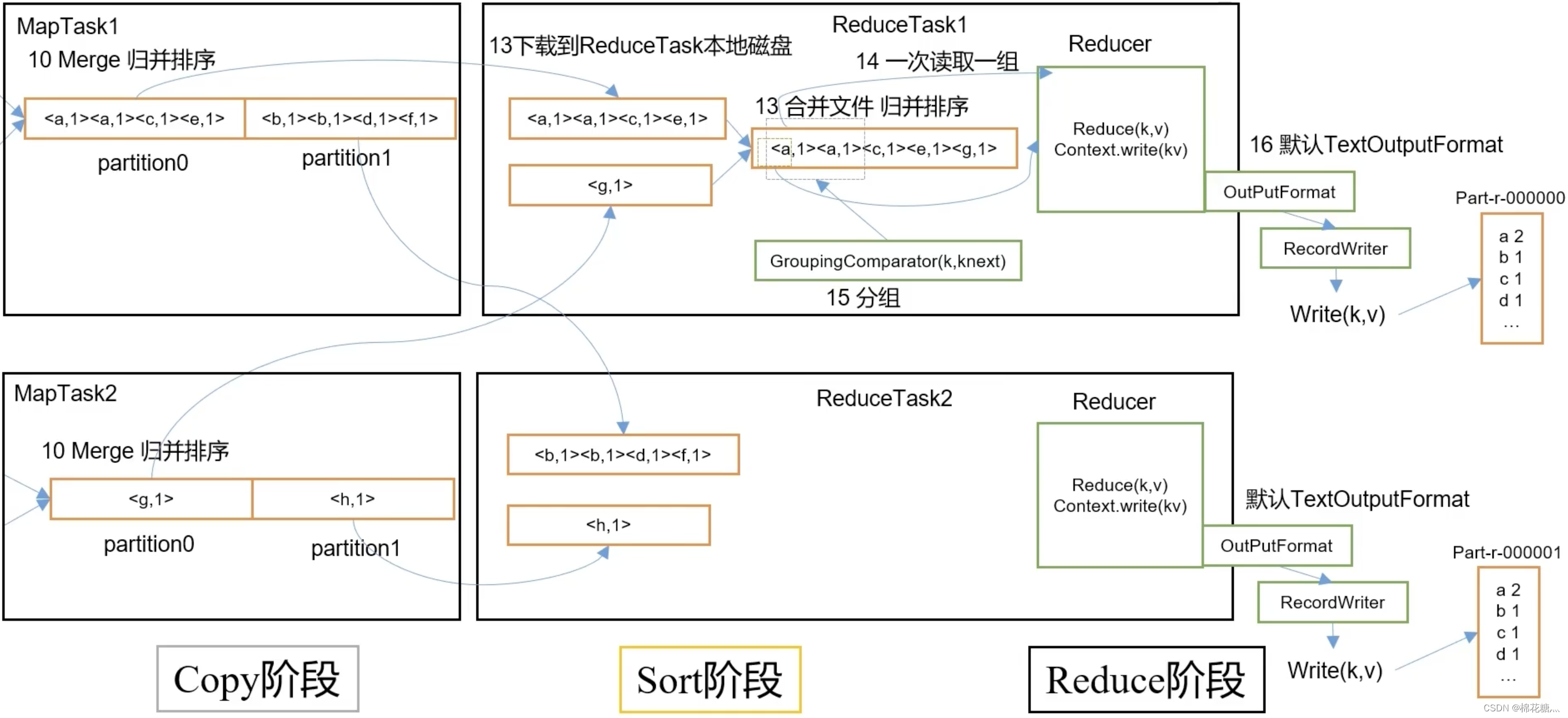
ReduceTask的并行度同样影响整个Job的执行并发度和执行效率,但与MapTask的并发数由切片数决定不同,ReduceTask 数量的决定是可以直接手动设置
(1) ReduceTask=0, 表示没有Reduce阶段, 输出文件个数和Map个数一 致
(2) ReduceTask默认值就是 1,所以输出文件个数为一个
(3)如果数据分布不均匀,就有可能在Reduce阶段产生数据倾斜
(4) Reduce Task数量并不是任意设置,还要考虑业务逻辑需求,有些情况下,需要计算全局汇总结果,就只能有1个Reduce Task
(5)具体多少个ReduceTask, 需要根据集群性能而定
(6)如果分区数不是1,但是ReduceTask为1, 是否执行分区过程。答案是:不执行分区过程。因为在MapTask的源码中,执行分区的前提是先判断ReduceNum个数是否大于1。不大于1肯定不执行
(5) 数据清洗(ETL)
“ETL,是英文Extract-Transform-Load的缩写,用来描述将数据从来源端经过抽取(Extract)、转换(Transform) 、加载(Load)至目的端的过程。ETL一词较常用在数据仓库,但其对象并不限于数据仓库在运行核心业务MapReduce程序之前,往往要先对数据进行清洗,清理掉不符合用户要求的数据。清理的过程往往只需要运行Mapper程序,不需要运行Reduce程序。
(6) 总结
1、Input Format
- 默认的是TextInputformat,key是偏移量,v 是一行内容
- 处理小文件用CombineTextInputFormat,把多个文件合并到一起统一切片
2、Mapper
- setup()初始化
- map()用户的业务逻辑;
- clearup() 关闭资源
3、分区
- 默认分区HashPartitioner,默认按照key的hash值 % numreducetask个数自定义分区
4、排序
- 部分排序:每个输出的文件内部有序。
- 全排序:一个reduce,对所有数据大排序。
- 二次排序:自定义排序范畴, 实现writableCompare接口,重写compareTo方法。总流量倒序按照 上行流量正序
5、Combiner
- 前提:不影响最终的业务逻辑()求和没问题,求平均值不行)
- 提前聚合map => 解决数据倾斜的一个方法
6、Reducer
- setup() 初始化
- reduce() 用户的业务逻辑
- clearup() 关闭资源
7、Output Format
- 默认TextOutputFormat按行输出到文件
- 自定义
四、Yarn
1. Yarn基础架构
Yarn是一个资源调度平台,负责为运算程序提供服务器运算资源,相当于一个分布式的操作系统平台,而MapReduce等运算程序则相当于运行于操作系统之上的应用程序。
YARN主要由ResourceManager、NodeManager、ApplicationMaster和Container等组件构成
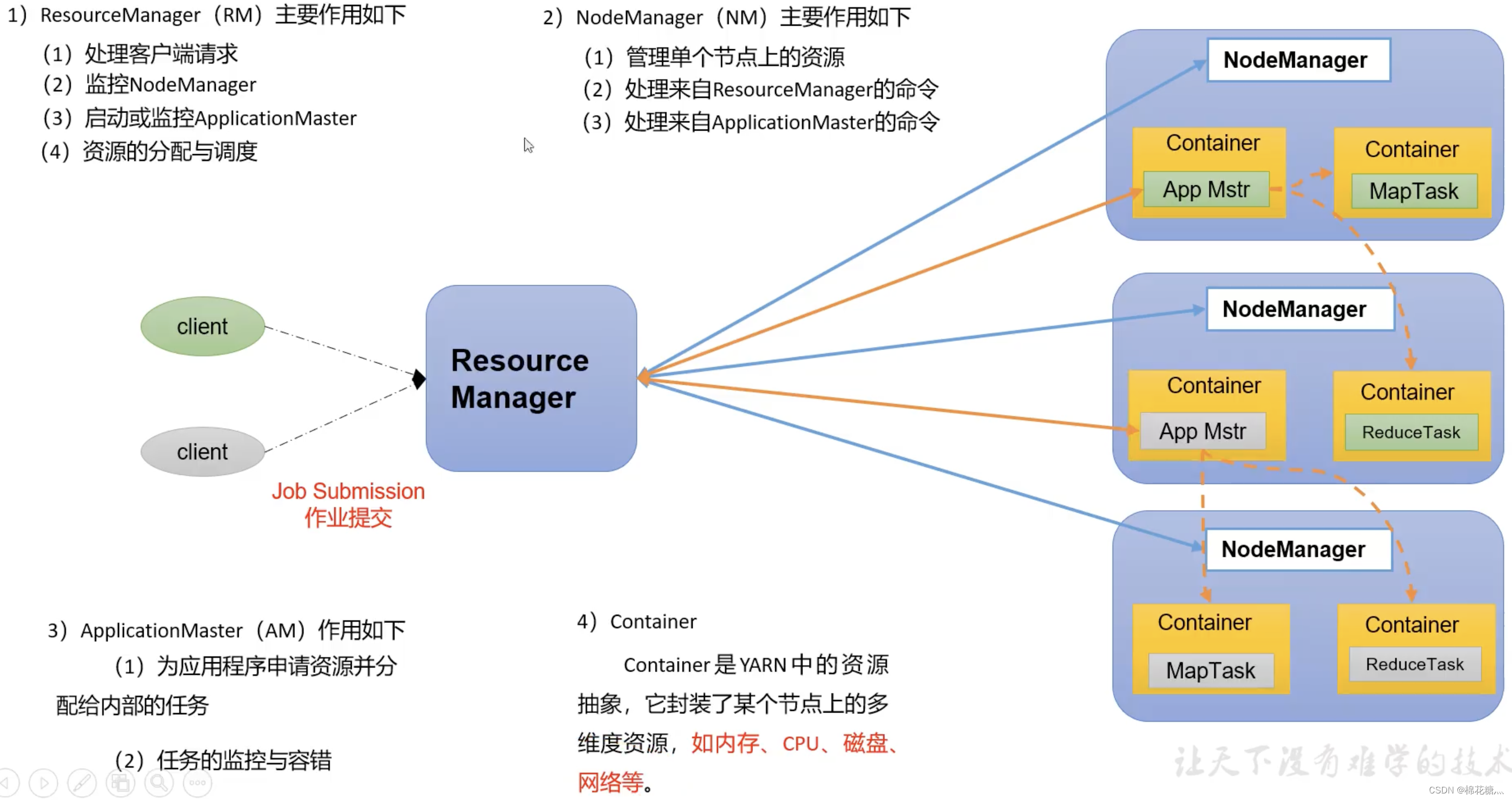
2. Yarn工作机制
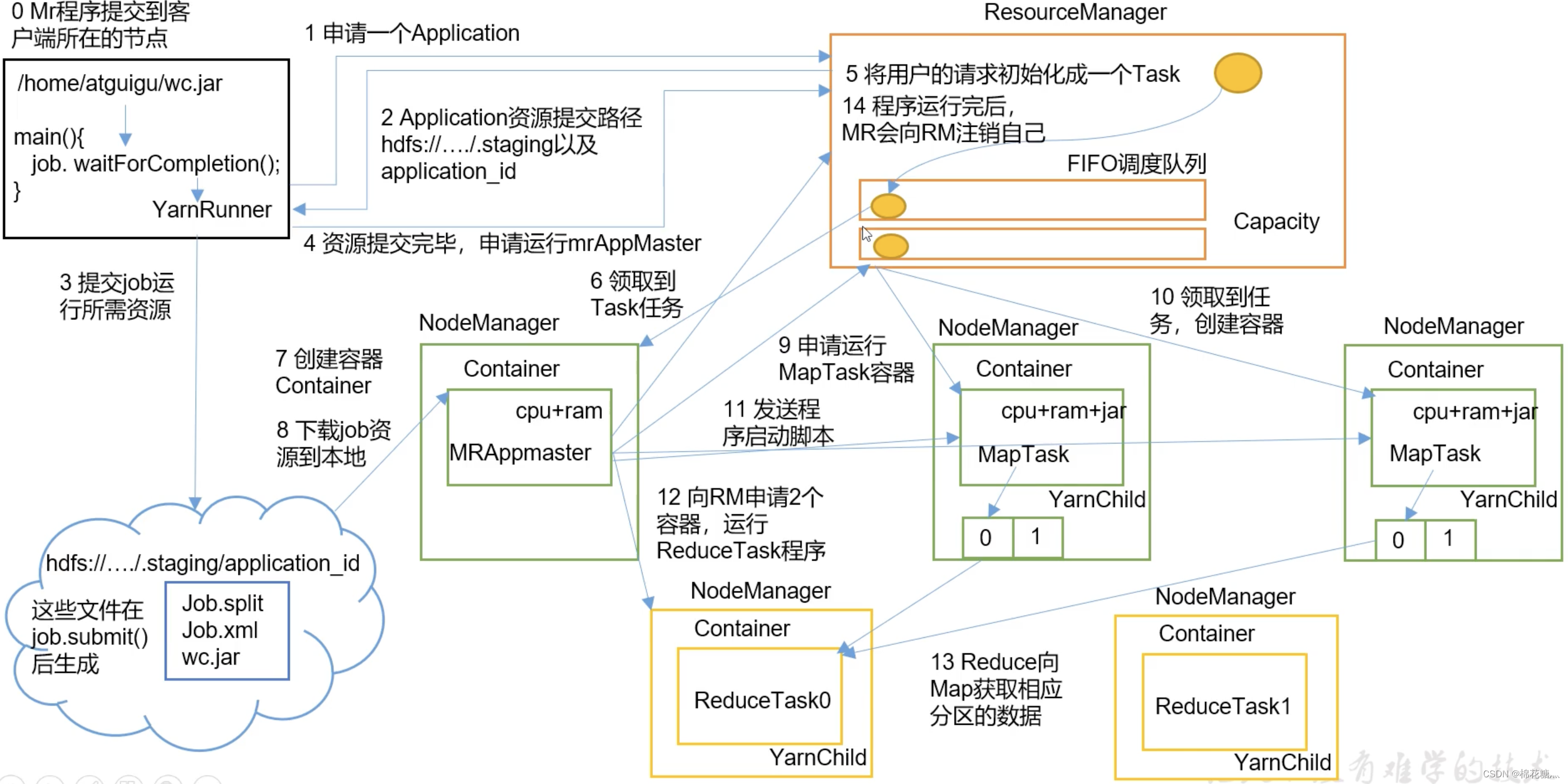
MapReduce_368">3. Yarn和HDFS、MapReduce的配合
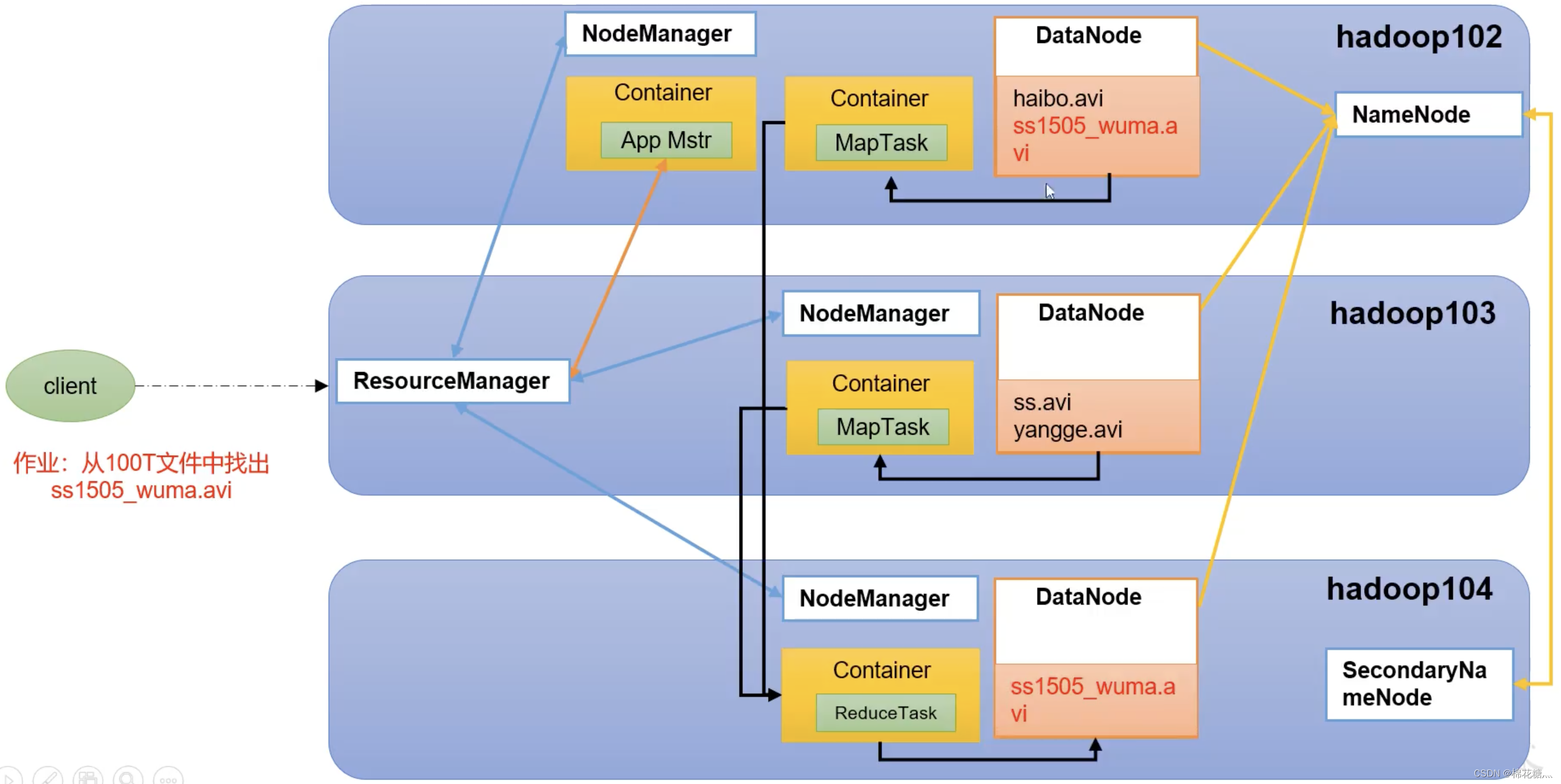
4. Yarn的调度器和调度算法
目前,Hadoop作业调度器主要有三种:FIFO、 容量(Capacity Scheduler)和公平(Fair Scheduler)。 Apache Hadoop3.1.3默认的资源调度器是容量调度器。CDH框架默认调度器是公平调度器。
(1) FIFO
FIFO调度器(First In First Out):单队列,根据提交作业的先后顺序,先来先服务。
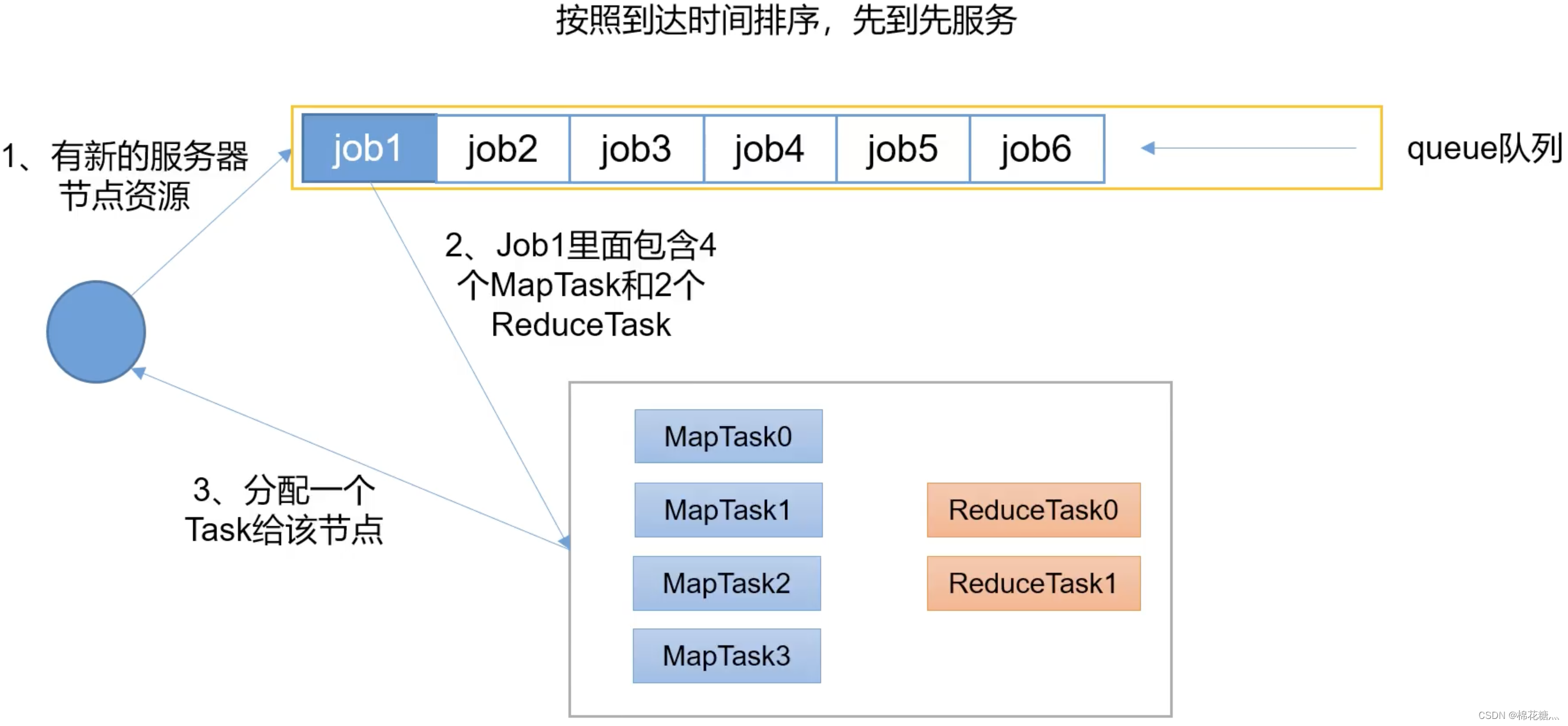
(2) 容量调度器
容量调度器是一个多用户调度器

一个队列中只要资源够,就可以按提交顺序分配给先来的job
容量调度器资源分配算法:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-D6aX0mMH-1651112212700)(/Users/zuzhiang/Library/Application Support/typora-user-images/image-20220416170827551.png)]](https://img-blog.csdnimg.cn/2c5f5135e91f49c2a57ac3955d900c7a.png)
(3) 公平调度器
公平调度器是一个多用户调度器

- 公平调度器设计目标是:在时间尺度上,所有作业获得公平的资源。某一时刻一个作业应获资源和实际获取资源的差距叫"缺额”
- 调度器会优先为缺额大的作业分配资源
公平调度器资源分配方式:
-
FIFO策略:公平调度器每个队列资源分配策略如果选择FIFO的话,此时公平调度器相当于上面讲过的容量调度器。
-
Fair策略:Fair策略(默认)是一种基于最大最小公平算法实现的资源多路复用方式,默认情况下,每个队列内部采用该方式分配资源。这意味着,如果一个队列中有两个应用程序同时运行,则每个应用程序可得到1/2的资源;如果三个应用程序同时运行,则每个应用程序可得到1/3的资源。
-
具体资源分配流程和容量调度器一致;
- 选择队列
- 选择作业
- 选择容器
以上三步,每一步都是按照公平策略分配资源
-
-
DRF策略:DRF(Dominant Resource Fairness),我们之前说的资源,都是单一标准,例如只考虑内存(也是Yarn默认的情况)。但是很多时候我们资源有很多种,例如内存,CPU,网络带宽等,这样我们很难衡量两个应用应该分配的资源比例。