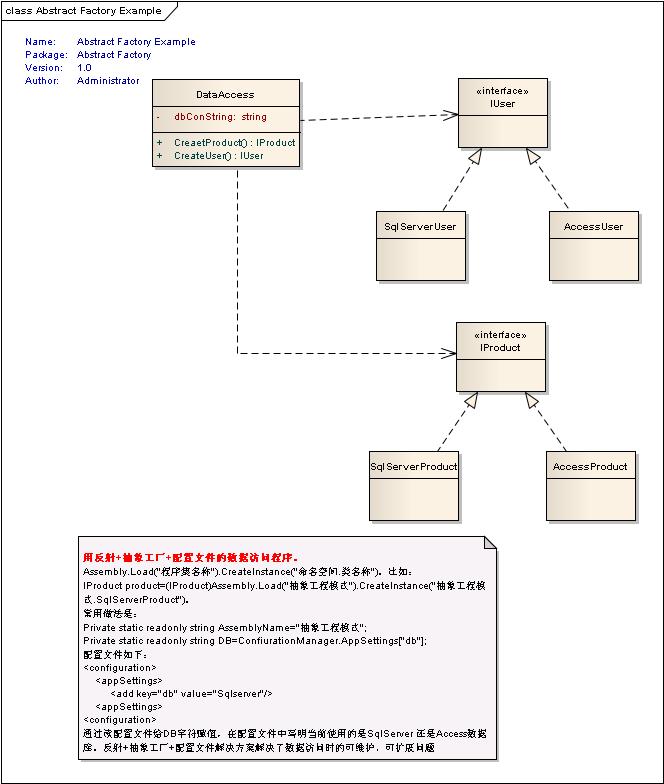
一 写在前面
1 Hive的自定义函数(User-Defined Functions)分三类:
- UDF:one to one,进一出一,row mapping。是row级别操作,类似upper、substr等
- UDAF:many to one,进多出一,row mapping。是row级别操作,类似sum、min等
- UDTF:one to many ,进一出多。类似:alteral view与explode实现的一行变多行
2 实现自定义函数有两种方式:
- 通过jar包形式实现(java)
- 通过Transform关键字实现(支持多种语言,一般用Python)
Transform关键字实现 与 jar包形式实现 在不同场景下的性能不同。数据量较小时,大多数场景下
transform有优势,而数据量大时jar包有优势在大数据量的场景下,Transform(Python)执行效率低的根本原因在于Python是直接向操作系统申请资源,而不是向YARN的ResourceManager申请资源,故而导致节点的资源无法高效组织和被利用。所以,不要轻易使用transform
接下来写一个统计统计字段长度的自定义函数
二 JAVA实现
0、基础信息
0.1 Hive有两个不同的接口编写UDF程序
一个是基础的UDF接口(org.apache.hadoop.hive.ql. exec.UDF) 可以处理基本类型的数据,如Text、IntWritable、LongWritable、DoubleWritable等
一个是复杂的GenericUDF接口(org.apache.hadoop.hive.ql.udf.generic.GenericUDF)可以处理Map、List、Set类型的数据
0.2 org.apache.hadoop.hive.ql. exec.UDF
只需要继承udf,然后实现evaluate()方法就行了
0.3 org.apache.hadoop.hive.ql.udf.generic.GenericUDF
至少需要实现以下三个方法
java">public ObjectInspector initialize(ObjectInspector[] arguments)
// 这个方法只调用一次,并且在evaluate()方法之前调用
// 该方法接受的参数是一个ObjectInspectors数组。该方法检查接受正确的参数类型和参数个数
// 该方法用于函数初始化操作,并定义函数的返回值类型
public Object evaluate(DeferredObject[] args){}
// 函数处理的核心方法,用途和UDF中的evaluate一样,处理真实的参数,并返回最终结果
public String getDisplayString(String[] children)
// 这个方法用于当实现的GenericUDF出错的时候,打印出提示信息。而提示信息就是你实现该方法最后返回的字符串1、UDF函数编写
1.1 前期准备
- 在IntelliJ IDEA里新建一个Maven项目
- 在pom.xml引入hive的依赖(注意版本号)
java"> <dependencies> <dependency> <groupId>org.apache.hive</groupId> <artifactId>hive-exec</artifactId> <version>3.1.2</version> </dependency> </dependencies>3.新建一个类(com.zhs.udf.FirstUDF)
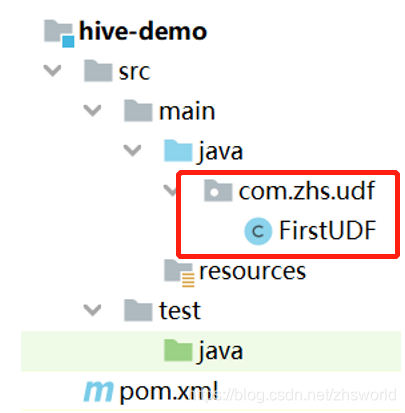
1.2 FirstUDF代码的代码
java">package com.zhs.udf;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
// extends 表示继承类。UDF需要继承GenericUDF
public class FirstUDF extends GenericUDF {
@Override
// ObjectInspector接口使得Hive可以不拘泥于一种特定数据格式, 使得数据流在输入端和输出端切换不同的格式
// UDF的初始化方法,主要用于验证输入参数的数据类型及输入参数的个数,返回值为ObjectInspector类型
public ObjectInspector initialize(ObjectInspector[] objectInspectors) throws UDFArgumentException {
if (objectInspectors.length != 1){
throw new UDFArgumentException("参数个数不为1");
}
// 基本类型的OI实例由工厂类 PrimitiveObjectInspectorFactory 创建
// 其它类型的OI实例由工厂类 ObjectInspectorFactory 创建
return PrimitiveObjectInspectorFactory.javaIntObjectInspector;
}
@Override
// 当UDF被调用时,对每行的数据进行逻辑处理
// DeferredObject 是封装的数组格式
public Object evaluate(DeferredObject[] deferredObjects) throws HiveException {
// 1.取出输入数据
String input = deferredObjects[0].get().toString();
// 2.判断数据数据是否为null
if (input == null) {
return 0;
}
// 3.返回输入数据的长度
return input.length();
}
@Override
// 展示方法,主要用于打印UDF的一些基本信息,如MR的执行计划,一般返回空即可
public String getDisplayString(String[] strings) {
return "";
}
}
1.3 打包
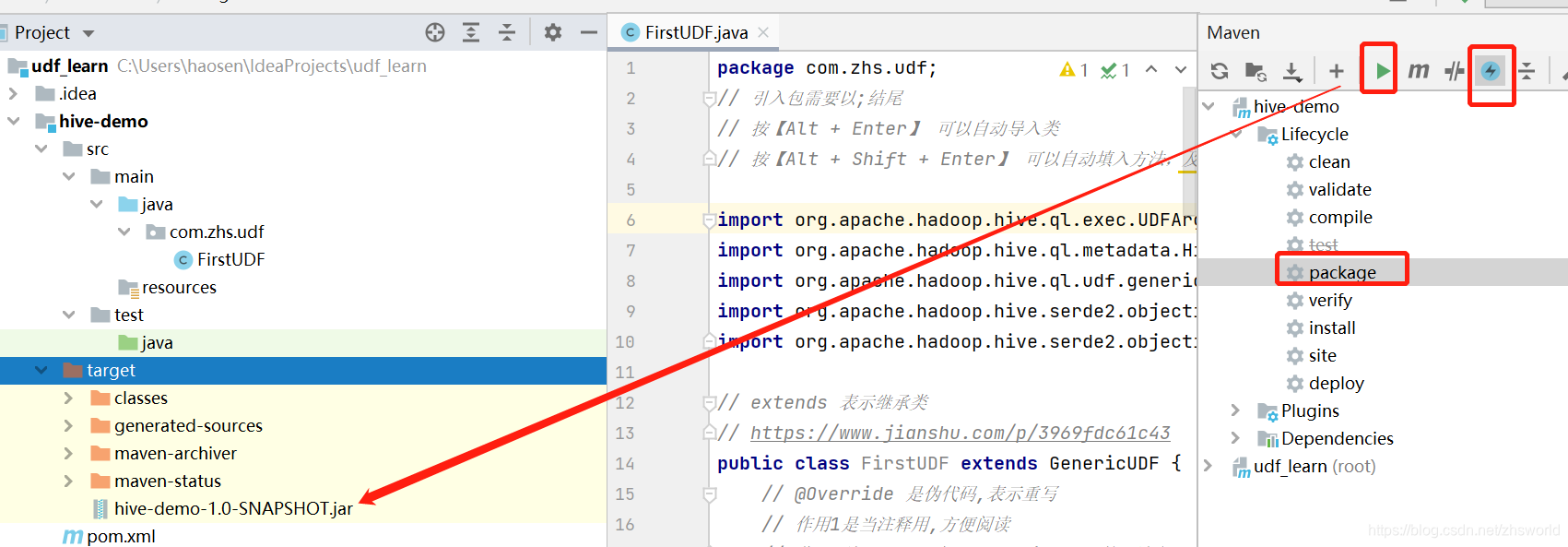
2、上传Jar包
Tips1: UDF使用的jdk版本最好与Hadoop集群使用的jdk版本相同
Tips2: 可以使用Xftp将本地jar包上传到安装hive的虚拟机/远程服务器上
2.1 如果是临时用,可以上传到任一目录下
2.2 如果是永久用,需要把jar包上传到hdfs的lib目录下
java">-- 第一步
把jar包先上传到了/home/zhs/Documents/hive-demo-1.0-SNAPSHOT.jar路径下
-- 第二步
-- 1 可以看看有没有lib目录
hadoop fs -ls /lib
-- 2 如果没有,则在hadoop上创建lib目录
hadoop fs -mkdir /lib
-- 3 把jar复制到lib目录下
hadoop fs -put /home/zhs/Documents/hive-demo-1.0-SNAPSHOT.jar /lib/
-- 4 可以再看下有没有复制成功
hadoop fs -mkdir /lib3、添加jar包到hive环境中(临时函数需要,永久函数不需要这步)
Tips:通过该方式添加的jar文件只存在于当前会话中,当会话关闭后不能够继续使用
java">// 先启动hive
// 语法:add jar +jar包所在的目录/jar包名字;
// /home/zhs/Documents/是jar包上传的目录
add jar /home/zhs/Documents/hive-demo-1.0-SNAPSHOT.jar;4、临时函数
java">// 创建临时函数
// 语法:CREATE TEMPORARY FUNCTION function_name AS class_name;
// class_name 就是类名+包名
create temporary function my_len as "com.zhs.udf.FirstUDF"
// 销毁临时函数
// 语法:DROP TEMPORARY FUNCTION [IF EXISTS] function_name;
drop temporary function my_len ;
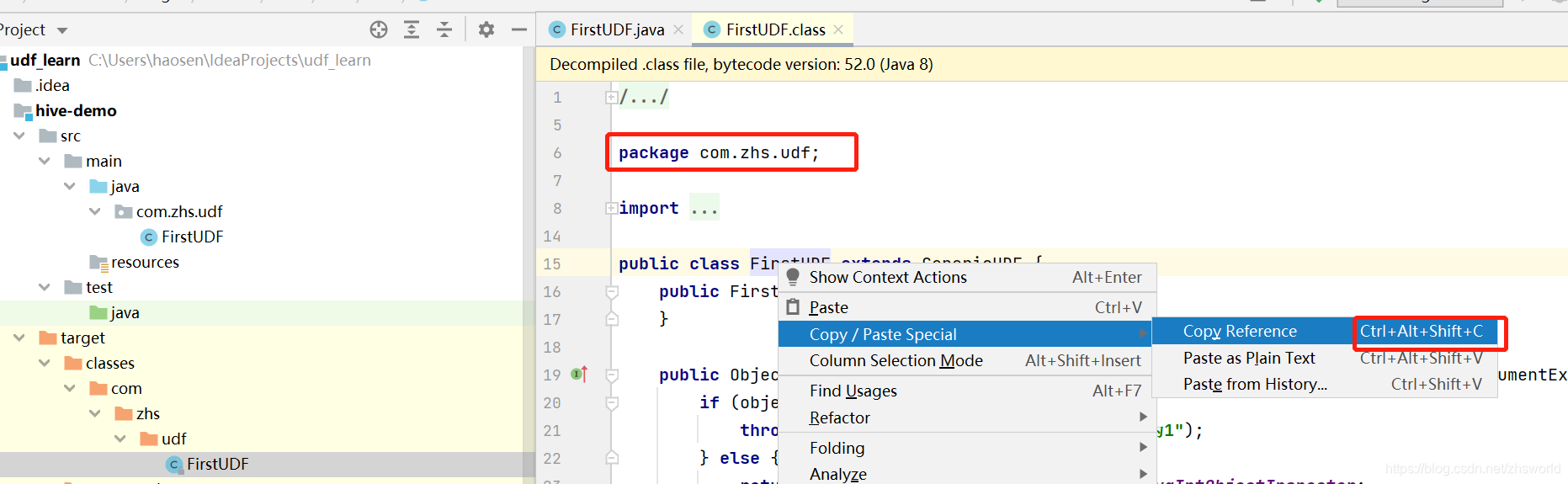
5、永久函数
java">create function my_len as "com.zhs.udf.FirstUDF"
using jar 'hdfs://localhost:9000/lib/hive-demo-1.0-SNAPSHOT.jar';
6、调用/测试
sql">select my_len("zhs");
-- 返回结果是 3
三 Python实现
0、基础信息
Hive的TRANSFORM关键字提供了在SQL中调用自写脚本的功能,脚本一般都是python写的
Select Transform 功能允许指定启动一个子进程,将输入数据按照一定的格式通过stdin输入子进程,并且通过parse子进程的stdout输出来获取输出数据
1 直接使用python命令示例
sql">select transform('for i in range(1, 5): print i;') using 'python' as (data);
-- 输出内容如下
1
2
3
42 使用python脚本示例
2.1、创建my_len.py并编写函数
practice.sc表如下:

# -*- coding: utf-8 -*-
import sys
for line in sys.stdin:
detail = line.strip().split(",")
sid = detail[0]
cid = detail[1]
socre = detail[2]
len_sid = len(sid)
len_cid = len(cid)
len_socre = len(socre)
len_list = (str(len_sid),str(len_cid),str(len_socre))
print("\t".join(len_list))2、上传脚本
/home/zhs/Documents/my_len.py
3、添加py脚本hive环境中
add jar /home/zhs/Documents/my_len.py;4、调用
sql">SELECT TRANSFORM (sid,cid,score)
USING 'python3 /home/zhs/Documents/my_len.py'
AS (len1,len2,len3)
FROM practice.sc;输出示例