Hadoop之HDFS
HDFS简介
HDFS是Hadoop的三大组件之一,用马士兵老师的话来说他就是一块分余展(分布式,冗余数据,可扩展)的大硬盘。它以数据节点的方式来存储数据,从逻辑上来说他分为NameNode和DataNode,这些节点都是用来存放数据的。其中NameNode中存放的是元数据,也就是一些文件与数据块的映射以及数据块与DataNode之间的映射(类比于操作系统中的目录文件),而真实的数据放在DataNode中。其中DataNode可以很方便的进行横向扩展这样保证了大量数据的存储,下面详细介绍他们。
NameNode
NameNode主要负责元数据的存储以及与处理用户的请求。
元数据
主要是一些映射信息主要包括:文件与块的映射,块与DataNode之间的映射。
块
这里提到了块,在HDFS中存放一个大的文件是需要分块存储的。在2.X的版本中块的大小默认为128M。如果一个文件大于128M那么就会被分为多块。分块有诸多好处比如说切了块文件的存放可以很灵活的进行存放这是灵活数据冗余的基础,然后切块之后文件系统只需要管理块而无需管理具体的文件,最后使得复制较为轻松把复制一个超大文件改为复制几个小文件的组合。
以下为一个元数据的格式:
例如: /test/a.log,3,{b1,b2},[{b1:[h0,h1,h3]},{b2:[h0,h2,h4]}]
我们可以看到一条元数据包括文件名,复本数量(备份数量),文件分块,以及每个分块具体在哪个DN(DataNode)上。有了这些我们就可以知道这些文件的具体位置了。
NameNode中的核心文件
NameNode中的核心文件包括
Fsimage:这是元数据的镜像文件,它存在硬盘上它并不是元数据的实时同步。只有在满足条件的时候才进行数据同步。它存在的意义就是为了奔溃恢复。
这里的条件是指:默认情况下3600秒同步一次,当edits达到64M同步一次,Hadoop重启的时候同步一次。
Edits:日志文件,每当客户端操作一次hdfs就会先在日志文件中留下操作日志然后才在内存中生成相应的元数据。这里有点蒙内存什么鬼?
原来在操作hdfs的时候NameNode会将元数据保留在内存中一份这样的话会大大提高请求的应答效率。而上述的Fsimage和Edits都是硬盘层面的。
Fstime:记载checkpoint的时间,也就是上一次我的fsimage所更新的时间,这样的话就能够计算出什么时间应该进行下一次更新。
SecondaryNameNode
上面我们提到了我们的Fsimage文件会在一定的条件下将元数据同步一次,由于NameNode在生产环境中的负载量很大,所以这个工作一般会交给SecondaryNameNode来执行,当然我们希望SecondaryNameNode会有一台独立的主机。同步数据的流程如下图所示:
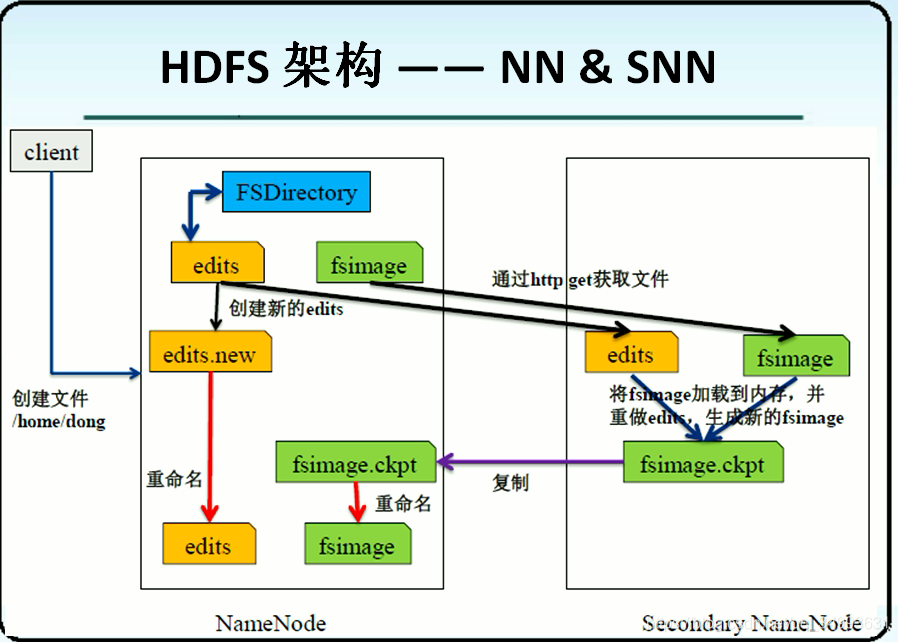
①由于同步数据会用到edits与fsimage两个文件,所以先将这两个文件通过网络复制到SSN上面。这时SSN将两个文件load到内存中进行合并。
②考虑到这时可能有客户端来访问所以在edits拷贝到SSN的时候也会在NN上面创建一个edits.new的文件用来写入这一段时间的日志。
③SNN将文件合并完毕然后将合并后的文件fsimage.ckpt通过网络赋值到NN上,然后fsimage.ckpt重命名为fsimage同时edits.new重命名为edits。
④同步完成
从上面我们不难发现SNN并不是为了NN的备份而产生的,只是为了同步数据。但是它有一个副作用就是能够帮助NN在崩溃的时候恢复部分数据。
DataNode
数据节点专门用来存放实际的数据。所有的文件在DN上都以块来存储。 这里面有一个核心的概念就是心跳机制。他指的是DN会每隔一段时间(默认3秒)就会给NN发送一个数据包(心跳报告)。它里面包含两种信息即它的存活状态以及他里面的数据信息。NN会根据心跳报告来更新自己元数据的信息。同时NN也会回送一些消息这样DN就会根据这些消息来增加删除移动节点上面的数据。如果一个DN在10分钟之内没有发送心跳报告的话那么NN就会认为当前的DN已经lost,并且将当前节点上丢失的数据补充到其它节点上。从中我们也可以看出NN并没有主动的管理DN而是DN主动去请求NN的。
Block复本放置策略与机架感知
Block的放置既要保证能够崩溃恢复又要保证数据传输的效率,针对这两个不同的要求会有不同的放置策略。
①第一个Block会放在内存占用不大而且CPU占用率不高的任意一个DN上面。
②第二个就要放在与第一个不同的机架上面,为了崩溃恢复。
③第三个就放在本机架就ok这样就满足了以上两个要求。
机架感知策略
Hadoop对于数据放在哪一个机架是不知道的,也就是他不知道slave在哪里。这就需要管理员人为的配置机架与slave的对应关系。具体的:
要将hadoop机架感知的功能启用,配置非常简单,在namenode所在机器的hadoop-site.xml配置文件中配置一个选项:
| <property> <name>topology.script.file.name</name> <value>/path/to/RackAware.py</value> </property> |
| #!/usr/bin/python #-*-coding:UTF-8 -*- import sys
rack = {"hadoopnode-176.tj":"rack1", "hadoopnode-178.tj":"rack1", "hadoopnode-179.tj":"rack1", "hadoopnode-180.tj":"rack1", "hadoopnode-186.tj":"rack2", "hadoopnode-187.tj":"rack2", "hadoopnode-188.tj":"rack2", "hadoopnode-190.tj":"rack2", "192.168.1.15":"rack1", "192.168.1.17":"rack1", "192.168.1.18":"rack1", "192.168.1.19":"rack1", "192.168.1.25":"rack2", "192.168.1.26":"rack2", "192.168.1.27":"rack2", "192.168.1.29":"rack2", }
if __name__=="__main__": print "/" + rack.get(sys.argv[1],"rack0")
|
客户端访问HDFS流程的具体说明
客户端读取HDFS上的文件
①客户端对NN发起RPC请求,告诉自己想要请求的资源。
②NN会根据客户端的情况返回给用户数据包(也就是元数据)包括文件与block的映射以及block与DN的映射关系。需要注意的是如果请求的数据过多的话那么NN一次性只会给客户端发送一部分元数据。
③客户端拿到元数据之后会就近原则的去DN上找数据。有一种特殊情况就是如果当前的客户端正好是一个DN的话而且请求的数据正好在自己的主机上的时候此时客户端就会直接读取本机的数据。
③每读取完一个块的时候会有一次checksum操作检查,读取到的数据与从NN哪里拿到的元数据的信息是否一致,如果不一致的话那么就会先会告诉NN这个块已经损坏让NN删除该块而自己再去其它的DN上读取该数据块。
④如果读完这一批的数据块客户端会再次询问有没有其他的数据块,如果有那么就再接收一批元数据信息进行新一轮的读取直到全部的数据块都读取完毕。
⑤当所有的数据块都读取完毕的时候,客户端会告知NN全部读完让它关闭不在使用的资源。
客户端上传文件到HDFS上
①客户端首先向NN发起一个RPC请求。
②NN会根据客户端的请求做两个判断,要上传的文件是否已经存在,上传者是否拥有上传的权限。都满足则会为上传文件创建一个记录,否则抛出异常。
③当客户端开始上传文件的时候首先会将文件切分成为一个个的package从而构成packages。Packages构成了一个data queue队列,客户端会按照找个队列的顺序来依次写出到HDFS上。
④当package写入一个节点失败之后客户端会通知NN删除这个残缺的数据,然后再继续写入当前package到其它完好的DN上。
⑤当一个package写入完成之后会使用pipeline的技术将该数据复制到其它的DN上作为复本。在一个节点完全成功之后DN会给客户端回复一个ack packet。此时在客户端的ack queue中增加当前这条信息,同时在data queue中删除当前传输成功的package转向下一个package的传输。
⑥在⑤的过程中如果出现了DN的损坏那么这个DN就会在管道中移出。NN会再次分配一个DN保持冗余节点的一致。
⑦在全部上传完成之后客户端会告诉NN全部传输完毕然后NN会关闭其它不在使用的资源。
客户端删除HDFS上的文件
①客户端向NN发起请求然后,NN判断文件的状况与权限。
②如果满足条件NN首先在日志中删除这个文件,然后再内存中删除这个文件。需要注意的是当前的问价依然存在于DN上,并没有真正的删除。
③此后DN会向NN发起心跳报告进而与NN中的元数据做比较,这时候会发现NN中的元数据中某文件已经被删除,所以在等待一段时间之后会删除这个删除的文件。
安全模式
Hadoop刚刚启动的时候由于会触发fsimage与edits的整合过程以及将edits中的数据输入到内存中所以暂时不受理用户的请求即用户已经进入了安全模式。这时namenode会收集datanode的报告与元数据进行比对当数据块达到最小复本以上是会被认为是安全的,再等待一段时间之后安全模式会自动解除。
再此感谢兰刚老师: -)



